CNN入门实战:我如何把准确率从86% 提高到99%(中)

蒋竺波
新加坡研究院 AI Department 公众号:follow_bobo
首发于专栏:https://zhuanlan.zhihu.com/c_141391545
个人公众号:follow_bobo
能不能点个赞,就是那种看起来写的还不错的样子
我们先来总结一下上一期的数据情况,顺便补充一点上一期没有讲到的:
目标类别一共20类,每类数量400-50不等
单从数据的情况,数据量少,并且不平衡,这个时候一个最基础的判断是用Pretrained model 实现两个Solution:
- Fine tune with Pretrained model
对于Google自己家的模型,比如Inception系列,我们用Tensorflow来fine tune,,毕竟自己家的模型,总会特别优化一点, 对于其他Pretrained model, 主要用Keras。
可能有人会问,Pretrained model 都是用ImageNet 训练的,但是ImageNet 里面并没有医疗数据呀?
首先,我们的数据量比较少,不建议Train from scratch.
第二,你可以理解为用Pretrained model 的参数来初始化model 的参数,而这些Pretrained model 的参数 的是经过专家们精确调参出来,效果肯定比随机生成参数好很多。最后也证明Fine tune with Pretrained model 在20个epochs 时就收敛了,并且有90%以上的Accuracy。
2. Extracting features with Pretrained model + Xg boost
这是在Kaggle 比赛中很常见的一种做法,特别是针对数据集比较少的时候。在这里最后效果不如 Fine tune,并且考虑到日后我们的数据越来越多,暂时不用这个方法。
如果有读者想有此法,我提醒一下。在提取特征之前,需要对model进行Domain Transfer, 什么意思,举个例子,Pretrained model 用的是ImageNet 训练,Domain 分布来自ImageNet, 我们的Domain来自医疗数据,如果模型中有Batch Normalization, 算法如下:

其中的mean, variance, scale γ and shift β 是来自于ImageNet 数据,你需要在这里转换成你的数据的mean, variance, scale γ , shift β.
怎么转换?很简单啦。
Freeze 住BN层以外的所有参数,将learning rate 设为1,训练几个Epoch就可以了。
mean, variance 可以在前向传播中学到,scale γ , shift β可以在反向传播中学到.
数据形式比较统一(都是超声波图和多普勒图),背景比较单一(都是黑色),图片质量参差不齐,亮度,颜色不一致,很多情况下图片包含大量噪声
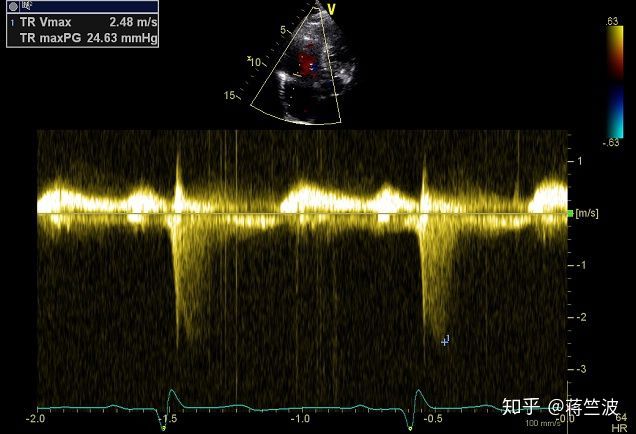
展示数据 2
也就是说我们要对数据去噪,提取重要部分,并且还要进行标准化
图片数据是由上(超声波,label 为 A ),下(多普勒,label 为B)两部分组成,经过和医生讨论,医生主要看的是B,A作为辅助判断,但是A 和 B 是有关联的,所有我们实验了以下多个模型:
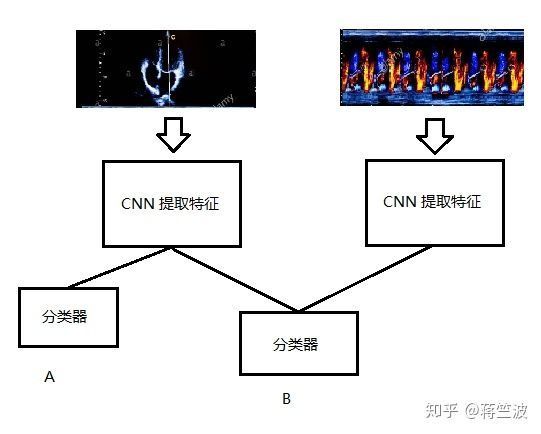
模型 1.0
模型 2.0
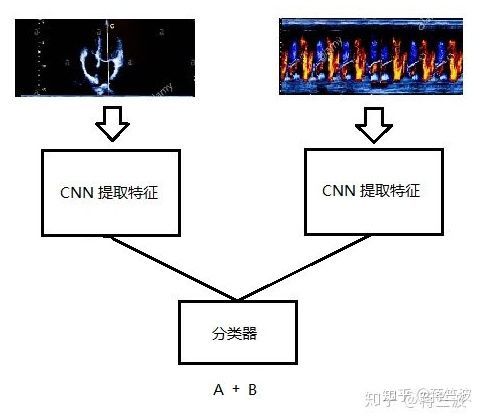
模型 3 .0
模型 3 虽然最节省资源,但表现略差,模型1 和2 结果接近,但 因为B为主输出,A 为副输出,我们可以容忍A有一定的预测误差,所有模型 1 更符合我们的目的
在经过几十次模型结构的调整以及调参(上节提过),最终模型 1.0 的平均分类准确率已经可以约94%了.
Step 6 : 数据增强
有小伙伴问,你有尝试做数据增强(Augmentation)吗?
考虑到医疗数据的特殊性,轻微的变动(比如旋转,放大等)都会影响到数据的label, 以及未来更多数据会陆陆续续进来,因此我们在这不做数据增强。
Step 7 : 额外信息
这一步其实我认为比较重要,这一步也显示出科研和工程的不同,工程就是为了达到目的不择手段的。按理说,如果再专注一模型层面上,准确率是还有可能提升的,但是需要耗费的时间成本过大,我们决定把方向转向一些未知方向。
在和医生详细沟通之后,我们发现除了图片数据,跟随着病人的还有一份Dicom数据,什么是Dicom 数据,下面是从Wiki 嫖下来的Dicom数据的解释:
在所有的用途上都是使用相同的格式,包括了网络应用和档案处理,和其他格式不同的是它统合了所有的资讯在同一个资料内,也就是说,如果有一张胸腔X光影像在你的病人个人资料内,这个影像决不可能意外地再从你的病人资料中分离。
DICOM的档案是由标准化且自由型式的开头再加上一连串的影像数据,单一个DICOM的物件只包含一张影像,但是此影像可能会有多个套图,这是为了能储存动态影像以及其他复图形式的资料。
其实一开始甲方是不愿意给Dicom 的,因为这个Dicom 涉及到病人太多隐私信息,经过多方协商后,甲方答应给出一小部分Dicom 做实验。其中我们的图片数据也来自于这份Dicom 数据中
Dicom 示例(图片来源于网络)
上面我们已经知道图片数据是由(A + B )组成,实际上B 还可以由(C+ D)组成
从这个Dicom 数据中,我们发现一个很重要的特征E,来自于正在给病人做检查的仪器设备,它竟然可以把 C 100%分类正确,意味着,当我们用模型 1 预测B时,B 中的C 和 特征E 中的C不一致时,可以轻松过滤掉错误预测。
同时,我们发现,从Dicom 数据中,我们挑选出了近20多类我们认为有价值的meta特征数据(心率等)来训练一个只对D 做分类的ML 分类器,意外的是分类准确率有80%左右。
这个时候我们考虑到将这20多类meta特征和CNN 提取出来的特征结合,然后一起送进B分类器,我们打印出了B分类器的特征rank 排序,发现这些meta特征重要性非常低,实验结果也是对B分类器的结果没有任何帮助。
至此,我们把分类器C,D 单独加进模型 1.0 ,成为模型1.1。

模型 1.1
合分类器的原理是Majority voting ,也就是投票机制。
由于最终模型还没有完成,所以合分类器的细节暂且不表。
由于数据量比较少,模型 1.1 表现和模型1 几乎一样。
但从理论上,C和D 的加入,肯定能给这个模型带来一定的贡献。
Step 8 : 研究超声波数据A
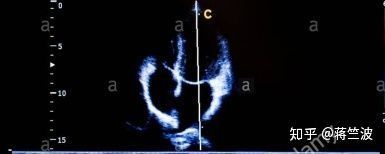
超声波数据A
我们现在把目光放在超声波数据A,我们希望从中发现点什么可以利用的。
等等,这是什么,拥有一双好奇大眼睛的我提出了问题?
中间那个白线是干啥子用的?所有的超声波数据都有着根白线。
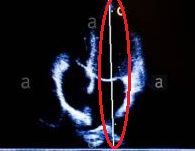
于是,我们想办法把这根白线的长度和角度提取出来,看能不能发现什么玄机。
好家伙
每一个多普勒B类数据(对,B类), 在超声波A 类中对应的白线角度是有一个大概分布,比如(A1 + B1 )的白线角度为60-90度,(A2 + B2)的白线角度为90-105度,下图展示了其中3 类的分布:
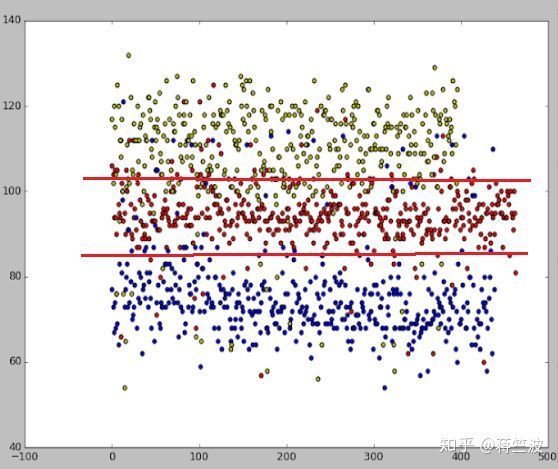
与多普勒B类数据对应的超声波A类白线角度分布 其中3类分布
从上图可以看到,每一个B类对于的A类白线角度是会有一个大概范围。
但同时也存在大量的overlap 以及 outliers,所以我们把overlap过于大的几类合并在一类
最后大概分类准确率只有80%左右,我们称之为分类器E。
其实对于白线角度的信息,我们在想CNN是否已经学进去,于是我们可视化了CNN最后一层global average pooling 层 学到的特征,并绘制了heat map 图,仍然无法确定CNN是否已经学习了白线的信息。
所以最后,我们仍然把分类器E放进合分类器里。
Step 9 : 挖掘多普勒数据B
在医生沟通的过程中, 我们了解到医生是怎么对多普勒数据分类的
他们主要看三点:
波形中波峰的个数,波峰的宽度,波峰与波峰之间的距离
于是我们提出一个问题:
如果我们把这三点找出来,然后根据医生的判断逻辑,做一个rule-base 分类器F,会不会帮助合分类器?
但是很明显这三点信息,应该是被CNN 学进去了,不出意外,CNN 自己学习的效果,要比rule-base 效果好
考虑到这个项目的下一阶段需要用到这三点信息,我们决定还是把它提取出来
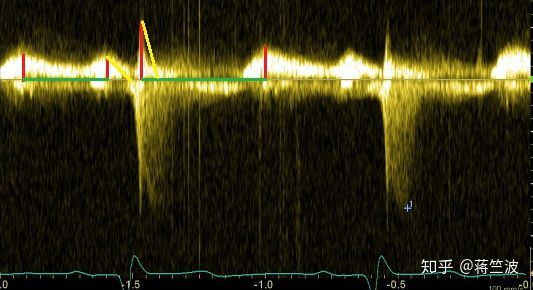
红线表示峰高,黄线表示峰宽,绿线表示峰与峰之间的距离
想要获得这三点信息,就得获得波形;
想要获得波形,很明显传统CV 的Pixel by Pixel 的方法肯定不行的,因为存在大量噪声
我们想到的是:
用Unet 为多普勒B类数据生成一个Mask,然后在Mask 上用CV的方法提取信息。
效果图如下:
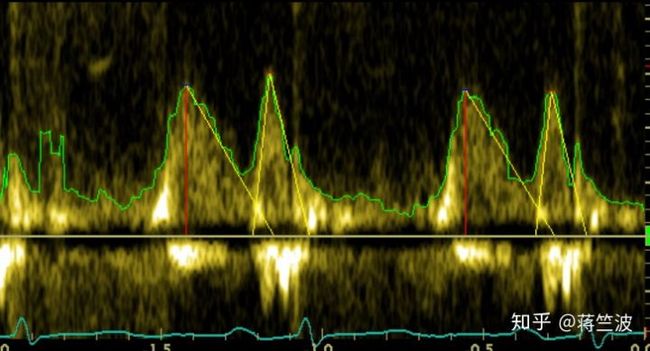
这个rule-base 的方法在这不多提,因为这个方法表现不稳定。
当图片质量非常好的时候,它可以有效的提出三个特征。
可是图片质量稍微不好,它就会出岔子。
自此,我们的模型已经由模型1.0 升级成模型1.2 了,特别是C分类器的出现,帮我们过滤了一部分错误答案。
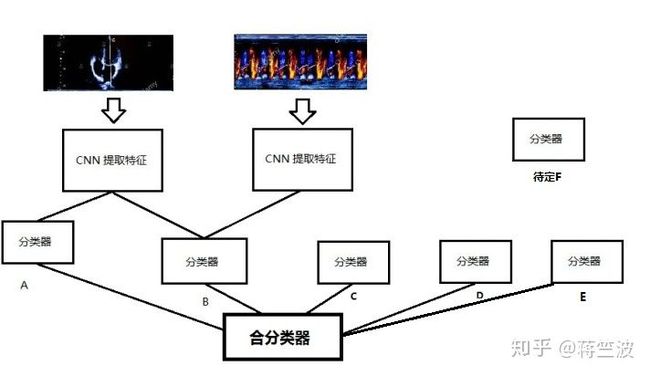
模型 1.2
下期见。
拜了个拜。
