【深度学习框架Keras】一个回归的例子
一、boston_housing数据集共包含506条数据,涵盖了士顿不同郊区房屋14种特征的信息。
from keras.datasets import boston_housing
import numpy as np
(train_data,train_targets),(test_data,test_targets) = boston_housing.load_data()二、数据集的相关信息
print('the shape of train data is ',train_data.shape)
print('the shape of test data is ',test_data.shape)
print('the shape of train target is ',train_targets.shape)
print('train target:',train_targets[:20])the shape of train data is (404, 13)
the shape of test data is (102, 13)
the shape of train target is (404,)
train target: [15.2 42.3 50. 21.1 17.7 18.5 11.3 15.6 15.6 14.4 12.1 17.9 23.1 19.9
15.7 8.8 50. 22.5 24.1 27.5]
三、处理数据集(标准化)
from sklearn import preprocessing
train_data = preprocessing.scale(train_data)
test_data = preprocessing.scale(test_data)四、设计网络结构
- 由于数据较少,所以设计一个小的神经网络防止过拟合
- 用于回归,所以输出层没有激活函数,仅是原始的线性函数,如果加入激活函数可能会限制输出值的范围
- 回归问题选择mse(mean squared error)做为loss function,metrics选择mae(mean absolute error)
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(train_data.shape[1],)))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',loss='mse',metrics=['mae'])
return model五、训练模型,使用k折交叉验证的方式选择超参数(epochs)
- 因为数据比较少,所以选择使用交叉验证的方式
all_scores = []
from sklearn.model_selection import KFold
floder = KFold(n_splits=4,random_state=0,shuffle=False)
for train_index,val_index in floder.split(train_data,train_targets):
model = build_model()
model.fit(train_data[train_index],
train_targets[train_index],
epochs=100,
batch_size=1,
verbose=0)#保持沉默
val_mse,val_mae = model.evaluate(train_data[val_index],train_targets[val_index],verbose=0)
all_scores.append(val_mae)评估结果
print('每折交叉验证的等分:',all_scores)
print('所有交叉验证等分的均值:',np.mean(all_scores)) # 均值更能体现真正的得分每折交叉验证的等分: [1.8091062413583887, 2.3354533285197645, 2.6341338936645204, 2.3044699477677297]
所有交叉验证等分的均值: 2.270790852827601
六、改进模型的训练,保存每个epochs的history,用于绘制loss图
all_mae_histories = []
from sklearn.model_selection import KFold
floder = KFold(n_splits=4,random_state=0,shuffle=False)
for train_index,val_index in floder.split(train_data,train_targets):
model = build_model()
history = model.fit(train_data[train_index],
train_targets[train_index],
validation_data = [train_data[val_index],train_targets[val_index]],
epochs=500,
batch_size=1,
verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)# 计算每个epochs的均值
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(500)]七、绘制
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12,4))
plt.plot(range(1,len(average_mae_history)+1),average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')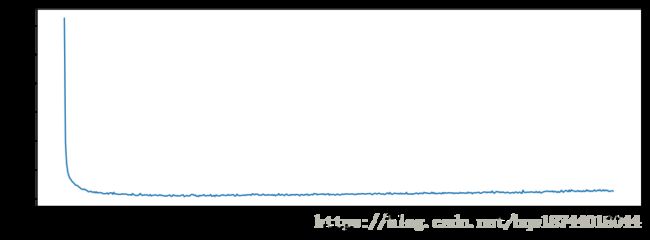
上面的图的极差太大,看不出来后面那些细小的变化,因此去掉前10个点,然后做一个滑动平均
def smooth_curve(points,factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor+point*(1-factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.figure(figsize=(12,4))
plt.plot(range(1,len(smooth_mae_history)+1),smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
八、选择超参数epochs,重新训练模型
model = build_model()
model.fit(train_data,
train_targets,
epochs=80,# 由上图发现在epochs=80的位置上MAE最低
batch_size=16,
verbose=0)
test_mse_score,test_mae_score = model.evaluate(test_data,test_targets,verbose=0)test_mae_score2.8045994534212