【Keras-LeNet】CIFAR-10
系列连载目录
- 请查看博客 《Paper》 4.1 小节 【Keras】Classification in CIFAR-10 系列连载
学习借鉴
- github:BIGBALLON/cifar-10-cnn
- 知乎专栏:写给妹子的深度学习教程
参考
- 【Keras-CNN】CIFAR-10
- 本地远程访问Ubuntu16.04.3服务器上的TensorBoard
硬件
- TITAN XP
文章目录
- 1 Introduction
- 1.1 CIFAR-10
- 1.2 LeNet
- 2 LeNet + 除以255
- 3 LeNet + Z-score 标准化
- 4 LeNet + 减均值、除以标准差 + data augmentation
- 5 LeNet + 减均值、除以标准差 + data augmentation + weight decay
1 Introduction
1.1 CIFAR-10
CIFAR-10.是由Alex Krizhevsky、Vinod Nair 与 Geoffrey Hinton 收集的一个用于图像识别的数据集,60000个32*32的彩色图像,50000个training data,10000个test data有10类,飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,每类6000张图。与MNIST相比,色彩、颜色噪点较多,同一类物体大小不一、角度不同、颜色不同。

1.2 LeNet
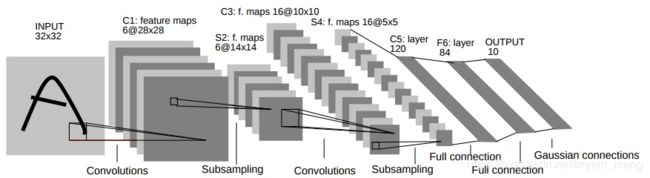
- input: 32×32×3
- conv1: 32×32×3 → 28×28×6
| kernel size | stride | number of filters | padding |
|---|---|---|---|
| 5 | 1 | 6 | 0 |
- maxpooling2: 28×28×6 → 14×14×6
| kernel size | stride | number of filters | padding |
|---|---|---|---|
| 2 | 2 | 6 | 0 |
- conv3: 14×14×6 → 10×10×16
| kernel size | stride | number of filters | padding |
|---|---|---|---|
| 5 | 1 | 16 | 0 |
- maxpooling4: 10×10×16 → 5×5×16
- fc5: 5×5×16 = 200 → 120
- fc6: 120 → 84
- output: 84 → 10

_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 6) 456
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 16) 2416
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 16) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 400) 0
_________________________________________________________________
dense_1 (Dense) (None, 120) 48120
_________________________________________________________________
dense_2 (Dense) (None, 84) 10164
_________________________________________________________________
dense_3 (Dense) (None, 10) 850
=================================================================
Total params: 62,006
Trainable params: 62,006
Non-trainable params: 0
parameters 计算,可以参考 【Keras-CNN】MNIST 2.3节 参数量计算
3 × 5 × 5 × 6 + 6 = 456
6 × 5 × 5 × 16 + 16 = 2416
400 × 120 + 120 = 48120
120 × 84 + 84 = 10164
84 × 10 + 10 = 850
2 LeNet + 除以255
导入各种库以及设置 hyper-parameters
import keras
from keras import optimizers
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Conv2D, Dense, Flatten, MaxPooling2D
from keras.callbacks import LearningRateScheduler, TensorBoard
batch_size = 128
epochs = 180
iterations = 391
num_classes = 10
log_filepath = './lenet'
下载数据集,查看数据集
# load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('train:',len(x_train))
print('test :',len(x_test))
print('train_image :',x_train.shape)
print('train_label :',y_train.shape)
print('test_image :',x_test.shape)
print('test_label :',y_test.shape)
output
train: 50000
test : 10000
train_image : (50000, 32, 32, 3)
train_label : (50000, 1)
test_image : (10000, 32, 32, 3)
test_label : (10000, 1)
数据处理
- one-hot
- /255 归一化操作
# one-hot 编码
y_train = keras.utils.to_categorical(y_train, num_classes) # one-hot 编码 (50000,10)
y_test = keras.utils.to_categorical(y_test, num_classes) # one-hot 编码 (10000,10)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# data preprocessing
x_train /= 255 #
x_test /= 255
搭建网络,设置好 training schedule
he_normal 的官网解释如下:normal distribution centered on 0 with s t d d e v = s q r t ( 2 / f a n _ i n ) stddev = sqrt(2 / fan\_in) stddev=sqrt(2/fan_in) where f a n _ i n fan\_in fan_in is the number of input units in the weight tensor.
def build_model():
model = Sequential()
model.add(Conv2D(6, (5, 5), padding='valid', activation = 'relu', kernel_initializer='he_normal', input_shape=(32,32,3)))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(16, (5, 5), padding='valid', activation = 'relu', kernel_initializer='he_normal'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation = 'relu', kernel_initializer='he_normal'))
model.add(Dense(84, activation = 'relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation = 'softmax', kernel_initializer='he_normal'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
# learning rate
def scheduler(epoch):
if epoch < 100:
return 0.01
if epoch < 150:
return 0.005
return 0.001
开始训练
# build network
model = build_model()
print(model.summary())
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# start traing
model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,callbacks=cbks,
validation_data=(x_test, y_test), shuffle=True)
# save model
model.save('lenet.h5')
如下是training的 accuracy 和 loss 变化


再看看在测试的 accuracy 和 loss
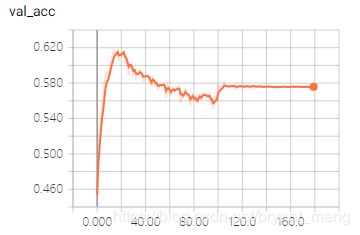

看看训练时最后几个 epoch
Epoch 178/180
50000/50000 [==============================] - 4s 78us/step - loss: 6.4374e-04 - acc: 1.0000 - val_loss: 4.6217 - val_acc: 0.5756
Epoch 179/180
50000/50000 [==============================] - 4s 79us/step - loss: 6.4141e-04 - acc: 1.0000 - val_loss: 4.6220 - val_acc: 0.5759
Epoch 180/180
50000/50000 [==============================] - 4s 83us/step - loss: 6.3841e-04 - acc: 1.0000 - val_loss: 4.6230 - val_acc: 0.5758
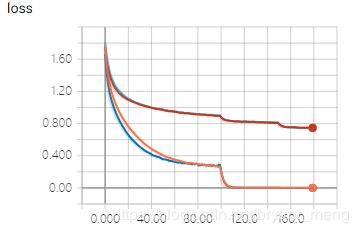
训练精度都为 100% 了,测试的时候精度才刚过 57%,过拟合还是相当严重的咯!而且验证集上的 loss 飘了,引用某大佬(同学)的朋友圈,“深度学习最怕遇见 ‘NIKE’ 了”
3 LeNet + Z-score 标准化
Z-score 标准化 就是减去均值,除以标准差
均值方差计算方法
import numpy as np
for i in range(0,3):
print(np.mean(x_train[:,:,:,i]))
print(np.std(x_train[:,:,:,i]))
output
125.30694
62.993233
122.95031
62.08874
113.86539
66.70485
我们把减均值,除以方差的 data preprocessing 简写为 dp
# data preprocessing
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
改变下 log 的存放位置(最开始 import 的时候的那里)
log_filepath = './lenet_dp'
改变下保存模型的名字(最后的地方)
model.save('lenet_dp.h5')
其它不变,开始训练




只看最后几个 epoch
Epoch 178/180
50000/50000 [==============================] - 4s 84us/step - loss: 3.6695e-04 - acc: 1.0000 - val_loss: 4.2865 - val_acc: 0.6122
Epoch 179/180
50000/50000 [==============================] - 4s 83us/step - loss: 3.6541e-04 - acc: 1.0000 - val_loss: 4.2874 - val_acc: 0.6123
Epoch 180/180
50000/50000 [==============================] - 4s 88us/step - loss: 3.6389e-04 - acc: 1.0000 - val_loss: 4.2882 - val_acc: 0.6123
可以看出过拟合现象有一定的缓解,不过还是有些严重,val_loss 中 “NIKE”还是出现了
4 LeNet + 减均值、除以标准差 + data augmentation
data augmentation(我们简写成da)
- 随机水平翻转
- 图片水平/垂直偏移
新增一个库
from keras.preprocessing.image import ImageDataGenerator
修改 log_filepath
log_filepath = './lenet_dp_da'
在 start train 前加入 data augmentation
# using real-time data augmentation
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train)
修改 start train 的内容如下
# start train
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
修改模型保存路径
# save model
model.save('lenet_dp_da.h5')
其它不变,开始训练
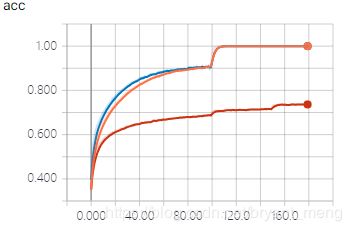
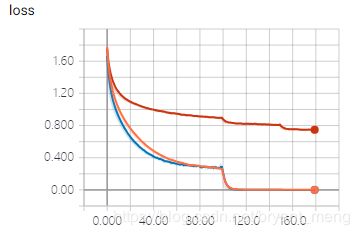
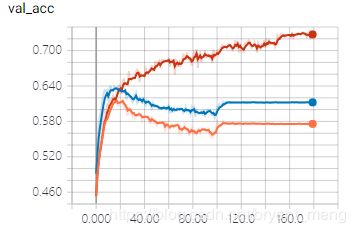
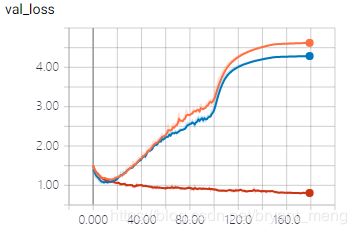
看看最后几次的 epoch
Epoch 177/180
391/391 [==============================] - 22s 57ms/step - loss: 0.7480 - acc: 0.7367 - val_loss: 0.8140 - val_acc: 0.7263
Epoch 178/180
391/391 [==============================] - 26s 67ms/step - loss: 0.7455 - acc: 0.7361 - val_loss: 0.8183 - val_acc: 0.7214
Epoch 179/180
391/391 [==============================] - 22s 57ms/step - loss: 0.7478 - acc: 0.7350 - val_loss: 0.8004 - val_acc: 0.7293
Epoch 180/180
391/391 [==============================] - 23s 60ms/step - loss: 0.7471 - acc: 0.7372 - val_loss: 0.8024 - val_acc: 0.7289
引入 data augmentation 之后,训练集 accuracy 比之前两个实验都低很多(70%+ vs 100%),但是测试集上的 accuracy 和训练集上的相当,且比前面两个实验高许多,说明大大缓解了过拟合问题。“NIKE”消失了
5 LeNet + 减均值、除以标准差 + data augmentation + weight decay
新增了 weight dacay,我们简写为 wd,其实就是 regularization,此处我们采用 l 2 l_2 l2 regularization 来防止过拟合
导入库和设置 hyper parameters 的时候,新增如下两句
from keras.regularizers import l2
weight_decay = 0.0001
修改保存 log 的文件名,修改如下
log_filepath = './lenet_dp_da_wd'
模型设计中,conv 层和 fc 层加入 weight decay,修改如下
def build_model():
model = Sequential()
model.add(Conv2D(6, (5, 5), padding='valid', activation = 'relu', kernel_initializer='he_normal', kernel_regularizer=l2(weight_decay), input_shape=(32,32,3)))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(16, (5, 5), padding='valid', activation = 'relu', kernel_initializer='he_normal', kernel_regularizer=l2(weight_decay)))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation = 'relu', kernel_initializer='he_normal', kernel_regularizer=l2(weight_decay) ))
model.add(Dense(84, activation = 'relu', kernel_initializer='he_normal', kernel_regularizer=l2(weight_decay) ))
model.add(Dense(10, activation = 'softmax', kernel_initializer='he_normal', kernel_regularizer=l2(weight_decay) ))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
修改保存模型的名字,修改如下
# save model
model.save('lenet_dp_da_wd.h5')
其它不变,开始训练




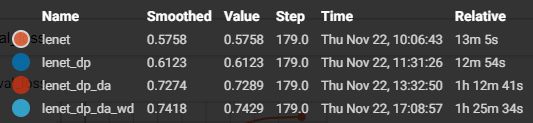
最后几个 epoch 的结果
Epoch 177/180
391/391 [==============================] - 22s 56ms/step - loss: 0.7460 - acc: 0.7555 - val_loss: 0.8056 - val_acc: 0.7406
Epoch 178/180
391/391 [==============================] - 23s 58ms/step - loss: 0.7428 - acc: 0.7557 - val_loss: 0.8103 - val_acc: 0.7425
Epoch 179/180
391/391 [==============================] - 22s 56ms/step - loss: 0.7420 - acc: 0.7554 - val_loss: 0.8158 - val_acc: 0.7415
Epoch 180/180
391/391 [==============================] - 23s 58ms/step - loss: 0.7414 - acc: 0.7558 - val_loss: 0.8081 - val_acc: 0.7429
效果比 LeNet + 减均值、除以标准差 + data augmentation 好一点点,注意加了 data augmentation 之后,train accuracy 会比不加低,train loss 会比不加的高,但是 test accuracy 会比不加高, test loss 会开始,比不加好。大大克服了 overfitting 的影响。