打造自己的图像识别模型
这篇文章关注的重点是如何使用TensorFlow 在自己的图像数据上训练深度学习模型,主要涉及的方法是对已经预训练好的ImageNet模型进行微调( Fine-tune)。本章将会从四个方面讲解:数据准备、训练模型、在测试集上验证准确率、导出模型并对单张图片分类。
1.微调的原理
在自己的数据集上训练一个新的深度学习模型时,一般采取在预训练
ImageNet 上进行微调的方法。什么是微调?这里以VGG16为例进行讲解。

如上图所示,VGG16的结构为卷积+全连接层。卷积层分为5 个部
分共13 层, 即图中的conv 1~ conv 5。还有3层是全连接层,即图中的fc6、fc7、fc8。卷积层加上全连接层合起来一共为16层,因此他被称为VGG16。如果要将VGG16的结构用于一个新的数据集,首先要将fc8这一层去掉。原因是fc8层的输入时fc7层的特征,输出是1000类的改,v,这1000类正好对应了ImageNet模型中的1000个类别。在自己的数据中,类别一般不是1000类,因此fc8层的结构在此时是不适用的,必须将fc8层去掉,重新采用符合数据类别的全连接层,作为新的fc8。比如数据集为5类。
此外,在训练的时候,网络的参数的初始值并不是随机化生成的,而是瞎用VGG16在ImageNet上已经训练好的初始值。这样做的原因在于,在ImageNet数据集上训练过的VGG16 中的参数已经包含了大量有用的卷积过滤器,与其从零开始初始化VGG16 的所高参数,不如使用已经训练好的参数当作训练的起点。这样做不仅可以节约大量训练时间,而且高助于分类器性能的提高。
载入VGG16 的参数后,就可以开始训练了。此时需要指定训练层数的
范围。一般来说,可以选择以下几种范围进行训练:
- 只训练fc8。训练范围一定要包含fc8这一层。之前说过,fc8的结构被调整过,因此它的参数不能直接从ImageNet预训练模型中取得。可以只训练fc8,保持其它层的参数不懂。这就相当于将VGG16当作一个“特征提取器”:用fc7层提取的特征做一个Softmax模型分类。这样做的好处是训练速度快,但往往性能不会太好。
- 训练所有参数。还可以对网络的所有参数进行训练,这种方法的训练速度可能比较慢,但是取得较高的性能,可以充分发挥深度模型的威力。
- 训练部分参数。通常固定千层参数不变,训练深层参数。如固定conv1、conv2部分的参数不训练,只训练conv3、conv4、conv5、fc6、fc7、fc8的参数。
这种训练方法就是所谓的对神经网络模型做微调。借助微调,可以从预
训练模型出发,将神经网络应用到自己的数据集上。下面介绍如何在
Tensor Flow 中进行微调。
2.数据准备
首先要做一些数据准备方面的工作:一是把数据集切分为训练集和验证集, 二是转换为tfrecord 格式。在data_prepare/文件夹中提供了会用到的数据集和代码。
首先要将自己的数据集切分为训练集和验证集,训练集用于训练模型,
验证集用来验证模型的准确率。这篇文章已经提供了一个实验用的卫星图片分类数据集,这个数据集一共高6个类别, 见表3-1 。

在data_prepare 目录中3 用一个pie 文件夹保存原始的图像文件,图像
文件保存的结构如下:

将图片分为train 和validation 两个目录,分别表示训练使用的图片和验
证使用的图片。在每个目录中,分别以类别名为文件夹名保存所高图像。在每个类别文件夹下,存放的就是原始的图像(如jpg 格式的图像文件)。下面,在data_prepare 文件夹下,使用预先编制好的脚本data_convert .py,将图片转换为为tfrecord 格式:

解释这里的参数含义:
- -t pic/: 表示转换pic文件夹中的数据。pic文件夹中必须有一个train目录和一个validation目录,分别代表训练和验证数据集。每个目录下按类别存放了图像数据。
- –train-shards 2:将训练数据集分成两块,即最后的训练数据就是两个tfrecord格式的文件。如果自己的数据集较大,可以考虑将其分为更多的数据块。
- –validation-shards 2: 将验证数据集分为两块。
- –num-threads 2:采用两个线程产生数据。注意线程数必须要能整除train-shaeds和validation-shards,来保证每个线程处理的数据块是相同的。
- –dataset-name satellite: 给生成的数据集起一个名字。这里将数据集起名叫“satellite”,最后生成的头文件就是staellite_trian和satellite_validation。
运行上述命令后,就可以在pic文件夹中找到5 个新生成的文件,分别
是训练数据satellite_train_00000-of-00002. tfrecord 、satellite_train 00001-of-00002. tfrecord ,以及验证数据satellite_validation_00000-of-00002. tfrecord 、satellite_validation_00001-of-00002 .tfrecord 。另外,还高一个文本文件label.txt ,官表示图片的内部标签(数字)到真实类别(字符串)之间的映射顺序。如图片在tfrecord 中的标签为0 ,那么就对应label.txt 第一行的类别,在tfrecord的标签为1 ,就对应label.txt 中第二行的类别,依此类推。
3.使用TensorFlow Slim微调模型
TensorFlow Slim 是Google 公司公布的一个图像分类工具包,它不仅定义了一些方便的接口,还提供了很多ImageNet数据集上常用的网络结构和预训练模型。截至2017 年7 月, Slim 提供包括VGG16 、VGG19 、InceptionVl ~ V4, ResNet 50 、ResNet 101, MobileNet 在内大多数常用模型的结构以及预训练模型,更多的模型还会被持续添加进来。
在本节中,先介绍如何下载Slim 的源代码,再介绍如何在Slim 中定义
新的数据库,最后介绍如何使用新的数据库训练以及如何进行参数调整。
3.1 下载TensorFlow Slim的源代码
如果需要使用Slim 微调模型,首先要下载Slim的源代码。Slim的源代
码保存在tensorflow/models 项目中,可以使用下面的git命令下载
tensorflow/models:
git clone https://github.com/tensorflow/models.git找到models/research/ 目录中的slim文件夹,这就是要用到的TensorFlowSlim 的源代码。这里简单介绍TensorFlowSlim的代码结构, 见表3-2。

3.2 定义新的datasets文件
在slim/datasets 中, 定义了所有可以使用的数据库,为了使用在第3.2节中创建的tfrecord数据进行训练,必须要在datasets中定义新的数据库。
首先,在datasets/目录下新建一个文件satellite.py,并将flowers.py 文件中的内容复制到satellite.py 中。接下来,需要修改以下几处内容:第一处是FILE_PATTERN 、SPLITS_TO SIZES 、NUM_CLASSES , 将其进行以下修改:
_FILE_PATTERN = 'satellite_%s_*.tfrecord'
SPLITS_TO_SIZES = {'train':4800, 'validation':1200}
_NUM_CLASSES = 6FILE_PATTERN变量定义了数据的文件名的格式和训练集、验证集的数量。这里定义_FILE_PATTERN = ‘satellite%s_*.tfrecord’和SPLITS_TO_SIZES = {‘train’:4800, ‘validation’:1200},就表明数据集中,训练集的文件格式为satellite_train_*.tfrecord,共包含4800张图片,验证集文件名格式为satellite_validation_*.tfrecord,共包含1200张图片。_NUM_CLASSES变量定义了数据集中图片的类别数目。
第二处修改image/format部分,将之修改为:
'image/format' tf.FixedLenFeature( (), tf. string, default_value ='jpg'),此处定义了图片的默认格式。收集的卫星图片的格式为jpg图片,因此修改为jpg 。最后,也可以对文件中的注释内容进行合适的修改。
修改完satellite.py后,还需要在同目录的dataset_factory.py文件中注册satellite数据库。未修改的dataset_factory. py 中注册数据库的对应代码为:
from datasets import cifar10
from datasets import flowers
from datasets import imagenet
from datasets import mnist
from datasets import satellite # 自己添加的
datasets_map = {
'cifar10': cifar10,
'flowers': flowers,
'imagenet': imagenet,
'mnist': mnist,
'satellite': satellite,
}3.3 准备训练文件夹
定义完数据集后,在slim文件夹下再新建一个satellite目录,在这个目录中,完成最后的几项准备工作:
- 新建一个data目录,并将3.2 节中准备好的5 个转换好格式的训练数据复制进去。
- 新建一个空的train_dir 目录,用来保存训练过程中的日志和模型。
- 新建一个pretrained目录,在slim的GitHub页面找到Inception V3 模型的下载地址,下载并解压后,会得到一个inception_v3 .ckpt 文件,将该文件复制到pretrained 目录下。
最后形成的目录结构为:
3.4 开始训练
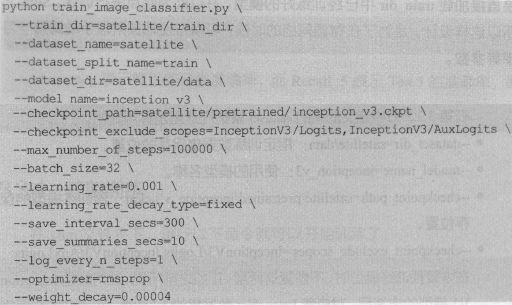
在slim 文件夹下,运行以下命令就可以开始训练了:

这里面的额参数比较多,下面一 一进行介绍:
- –trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits:首先来解释trainable_scope的作用,因为它非常重要。trainable_scopes规定了在模型中微调变量的范围。这里的设定表示只对InceptionV3/Logits,InceptionV3/AuxLogits 两个变量进行微调,其它的变量都不动。InceptionV3/Logits,InceptionV3/AuxLogits就相当于在第一节中所讲的fc8,他们是Inception V3的“末端层”。如果不设定trainable_scopes,就会对模型中所有的参数进行训练。
- –train_dir=satellite/train_dir:表明会在satellite/train_dir目录下保存日志和checkpoint。
- –dataset_name=satellite、–dataset_split_name=train:指定训练的数据集。在3.2节中定义的新的dataset就是在这里发挥用处的。
- –dataset_dir=satellite/data: 指定训练数据集保存的位置。
- –model_ name=inception_v3 :使用的模型名称。
- –checkpoint_path=satellite/pretrained/inception_v3.ckpt:预训练模型的保存位置。
- –checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits : 在恢复预训练模型时,不恢复这两层。正如之前所说,这两层是InceptionV3模型的末端层,对应着ImageNet 数据集的1000 类,和当前的数据集不符, 因此不要去恢复它。
- –max_number_of_steps 100000 :最大的执行步数。
- –batch size =32 :每步使用的batch 数量。
- –learning rate=0.001 : 学习率。
- –learning_rate_decay_type=fixed:学习率是否自动下降,此处使用固定的学习率。
- –save interval secs=300 :每隔300s ,程序会把当前模型保存到train dir中。此处就是目录satellite/train dir 。
- –save_summaries_secs=2 :每隔2s,就会将日志写入到train_dir 中。可以用TensorBoard 查看该日志。此处为了方便观察,设定的时间间隔较多,实际训练时,为了性能考虑,可以设定较长的时间间隔。
- –log_every_n_steps=10: 每隔10 步,就会在屏喜上打出训练信息。
- –optimizer=rmsprop: 表示选定的优化器。
- –weight_decay=0.00004 :选定的weight_decay值。即模型中所高参数的二次正则化超参数。
以上命令是只训练末端层InceptionV3/Logits, InceptionV3 /AuxLogits, 还可以使用以下命令对所有层进行训练:
对比只训练、末端层的命令,只再一处发生了变化,即去掉了
–trainable_ scopes 参数。原先的–trainable_ scopes= Inception V3 /Logits ,InceptionV3 / AuxLogits 表示只对末端层Inception V3 /Logits 和Inception V3 / AuxLogits 进行训练,去掉后就可以训练模型中的所有参数了。下面会比较这两种训练方式的效果。
3.5 训练程序行为
当train_ image_ classifier. py 程序启动后,如果训练文件夹(即satellite/train_ dir )里没再已经保存的模型,就会加载checkpoint_path中的预训练模型,紧接着,程序会把初始模型保存到train_dir中,命名为model.cpkt-0,0表示第0步。这之后,每隔5min(参数一save interval secs=300 指定了每隔300s 保存一次,即5min)。程序还会把当前模型保存到同样的文件夹中,命名格式和第一次保存的格式一样。因为模型比较大,程序只会保留最新的5 个模型。
此外,**如果中断了程序井再次运行,程序会首先检查train dir 中有无已经保存的模型,如果有,就不会去加载checkpoint_path中的预训练模型, 而是直接加载train dir 中已经训练好的模型,并以此为起点进行训练。**Slim之所以这样设计,是为了在微调网络的时候,可以方便地按阶段手动调整学习率等参数。
3.6 验证模型准确率
如何查看保存的模型在验证数据集上的准确率呢?可以用eval_image classifier.py 程序进行验证,即执行下列命令:

这里参数含义为:
- –checkpoint_path=satellite/train _ dir: 这个参数既可以接收一个目录的路径,也可以接收一个文件的路径。如果接收的是一个目录的路径,如这里的satellite/train_dir,就会在这个目录中寻找最新保存的模型文件,执行验证。也可以指定一个模型验证,以第300步为例,在satellite/train_ dir 文件夹下它被保存为model.clcpt-300.meta 、
model.ckpt-300.index 、model. ckpt-3 00.data-00000-of-00001 三个文件。此时,如果要对它执行验证,给checkpoint_path 传递的参数应该为satellite/train_ dir/model.ckpt-300 。 - –eval_dir=satellite/eval_dir :执行结果的曰志就保存在eval_dir 中,同样可以通过TensorBoard 查看。
- –dataset_name=satellite 、–dataset_split_name=validation 指定需要执行的数据集。注意此处是使用验证集( validation )执行验证。
- –dataset_dir=satellite/data :数据集保存的位置。
- –model_ name「nception_ v3 :使用的模型。
执行后,应该会出现类似下面的结果:
eval/Accuracy[0.51]
eval/Recall_5[0.97333336]Accuracy表示模型的分类准确率,而Recall_5 表示Top 5 的准确率,即在输出的各类别概率中,正确的类别只要落在前5 个就算对。由于此处的类别数比较少,因此可以不执行Top 5 的准确率,民而执行Top 2 或者Top 3的准确率,只要在eval_image_classifier.py 中修改下面的部分就可以了:

3.7 TensorBoard 可视化与起参数选择
在训练时,可以使用TensorBoard 对训练过程进行可视化,这也有助于
设定训练模型的万式及超参数。使用下列命令可以打开TensorBoard (其实就是指定训练文件夹):
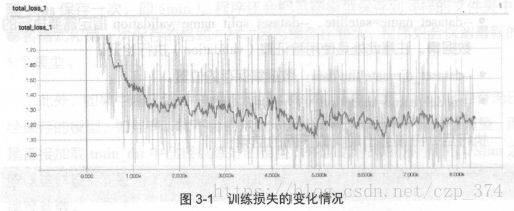
tensorboard --logdir satellite/train_dir在TensorBoard中,可以看到损失的变化由线3 如图3-1 所示。观察损
失曲线高助于调整参数。当损失曲线比较平缓,收敛较慢时, 可以考虑增大学习率,以加快收敛速度;如果揭失曲线波动较大,无法收敛,就可能是因为学习率过大,此时就可以尝试适当减小学习率。
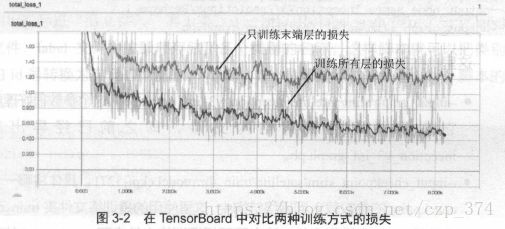
此外,使用TensorBoard ,还可以对比不同模型的损失变化曲线。如在3.6节中给出了两条命令,一条命令是只微调Inception V3 末端层的,
另外一条命令是微调整个网络的。可以在train_dir 中建立两个文件夹,训练这两个模型时,通过调整train_dir参数,将它们的日志分别写到新建的文件夹中,此时再使用命令tensorboard –logdir satellite/train_dir 打开TensorBoard,就可以比较这两个模型的变化曲线了。如图3-2 所示, 上方的曲线为只训练末端层的损失,下方的曲线为训练所高层的损失。仅看损失,训练所高层的效果应该比只训练末端层要好。事实也是如此,只训练末端层最后达到的分类准确率在76%左右,而训练所高层的分类准确率在82%左右。读者还可以进一步调整训练、变量、学习率等参数,以达到更好的效果。
3.8 导出模型并对单张图片进行识别
训练完模型后,常见的应用场景是:部署训练好的模型并对单张图片做
识别。这里提供了两个代码文件: freeze_graph. py 和classify_image_inception_v3. py 。前者可以导出一个用于识别的模型,后者则是使用inception_v3 模型对单张图片做识别的脚本。
TensorFlow Slim提供了导出网络结构的脚本export_inference_ graph.py 。首先在slim 文件夹下运行:
python export_inference_ graph.py \
--alsologtostderr \
--model_name=inception_v3 \
--output_file=satallite/inception_v3_inf_graph.pb \
--dataset_name satellite这个命令会在satellite 文件夹中生成一个inception_v3 _inf _graph. pb 文件。注意: inception_v3 _inf _graph.pb 文件中只保存了Inception V3 的网络结构,并不包含训练得到的模型参数,需要将checkpoint 中的模型参数保存进来。方法是使用freeze_graph. py 脚本(在chapter_3 文件夹下运行):
python freeze-graph.py \
--input_graph slim/satellite/inception_v3_inf_graph.pb \
--input_checkpoint slim/satallite/train_dir/model.ckpt-5271 \
--input_binary true \
--output_node_names InceptionV3/Predictions/Reshape_1 \
--output_graph slim/satellite/frozen_graph.pb这里参数含义为:
- –input_graph slim/satellite/inception_v3_inf_graph.pb。这个参数很好理解,它表示使用的网络结构文件,即之前已经导出的inception_v3 _inf_gr aph.pb 。
- –input_checkpoint slim/satallite/train_dir/model.ckpt-5271。具体将哪一个checkpoint 的参数载入到网络结构中。这里使用的是训练文件夹train _d让中的第5271 步模型文件。我们需要根据训练文件夹下checkpoint的实际步数,将5271修改成对应的数值。
- input_binary true。导入的inception_v3_inf_graph.pb实际是一个protobuf文件。而protobuf 文件有两种保存格式,一种是文本形式,一种是二进制形式。inception_v3 _ inf graph. pb 是二进制形式,所以对应的参数是–input binary true 。初学的话对此可以不用深究,若高兴趣的话可以参考资料。
- –output_graph slim/satellite/frozen_graph.pb。最后导出的模型保存为slim/satellite/frozen_graph.pb 文件。
如何使用导出的frozen_graph.pb 来对单张图片进行预测?编写了一个classify image_inception_ v3.py 脚本来完成这件事。先来看这个脚本的使用方法:
python classify_image_inception_v3.py \
--model_path slim/satellite/frozen_graph.pb \
--label_path data_prepare/pic/label.txt \
--image_file test_image.jpg一model_path 很好理解,就是之前导出的模型frozen_graph. pb 。模型的输出实际是“第0 类’、“第1 类”……所以用–label_path 指定了一个label文件, label文件中按顺序存储了各个类别的名称,这样脚本就可以把类别的id号转换为实际的类别名。–image _file 是需要测试的单张图片。脚本的运行结果应该类似于:
water (score = 5.46853)
wetland (score = 5.18641)
urban (score = 1.57151)
wood (score = -1.80627)
glacier (score = -3.88450)这就表示模型预测图片对应的最可能的类别是water,接着是wetland 、urban 、wood 等。score 是各个类别对应的Logit 。
最后来看classify_image_inception_ v3 . py 的实现方式。代码中包含一个preprocess for_ eval函数, 它实际上是从slim/preprocessing/inception_preprocess ing.py里复制而来的,用途是对输入的图片做预处理。
classify_ image_inception_v3.py 的主要逻辑在run_inference_on_ image函数中,第一步就是读取图片,并用preprocess_for_eval做预处理:
with tf.Graph().as_default():
image_data = tf.gfile.FastGFile(image, 'rb').read()
image_data = tf.image.decode_jpeg(image_data)
image_data = preprocess_for_eval(image_data, 299, 299)
image_data = tf.expand_dims(image_data, 0)
with tf.Session() as sess:
image_data = sess.run(image_data)Inception V3 的默认输入为299 * 299 ,所以调用preprocess_for_eval 时指定了宽和高都是299 。接着调用create_graph()将模型载入到默认的计算图中。
def create_graph():
"""Creates a graph from saved GraphDef file and returns a saver."""
# Creates graph from saved graph_def.pb.
with tf.gfile.FastGFile(FLAGS.model_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')FLAGS.model_path 就是保存的slim/satellite/frozen_graph.pb 。将之导入后先转换为graph_def,然后用tf.import_graph_def()函数导入。导入后,就可以创建Session 并测试图片了,对应的代码为:
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('InceptionV3/Logits/SpatialSqueeze:0')
predictions = sess.run(softmax_tensor,
{'input:0': image_data})
predictions = np.squeeze(predictions)
# Creates node ID --> English string lookup.
node_lookup = NodeLookup(FLAGS.label_path)
top_k = predictions.argsort()[-FLAGS.num_top_predictions:][::-1]
for node_id in top_k:
human_string = node_lookup.id_to_string(node_id)
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))InceptionV3/Logits/SpatialSqueeze:0是各个类别Logit值对应的节点。输入预处理后的图片image_data,使用sess.run()函数去除各个类别预测Logit。默认只取最有可能的FLAGS.num_top_predictions个类别输出,这个值默认是5。可以运行脚本时用–num_top_predictions参数来改变此默认值。node_ lookup 定义了一个NodeLookup 类,它会读取label文件,并将模型输出的类别id转换成实际类别名,实现代码比较简单,就不再详细介绍了。
4. 总结
这篇文章首先简要介绍了微调神经网络的基本原理,接着详细介绍了如何使用TensorFlow Slim 微调预训练模型,包括数据准备、定义新的datasets文件、训练、验证、导出模型井测试单张图片等。如果需要训练自己的数据,可以参考从第2节开始的步骤,修改对应的代码,来打造自己的图像识别模型。