保护个人数据集隐私,怎么少得了Python和Pandas

全文共2256字,预计学习时长4分钟
 图片来源:unsplash.com/@dmey503
图片来源:unsplash.com/@dmey503
工作中处理含敏感信息的数据集是有风险的。一旦这类数据在数据集中出现,数据科学家们应谨慎再谨慎。
人们通常认为,处理敏感信息时,只要删除姓名、ID及信用卡卡号就能保护个人隐私。这其实是误解。尽管删除直接识别信息能起到一定作用,但人们能通过数据集里很多其他信息来重新识别个体。
比方说,哈佛大学定量社会分析学院(IQSS)数据隐私实验室的主管娜塔尼亚·斯威尼(Latanya Sweeney)就证实道,87%的美国人身份可通过邮政编码、性别及出生日期被再次确认。
本文将介绍如何有效降低数据集的隐私风险,并同时维持其分析价值,以开展机器学习。
接下来的例子将使用在数据科学家中备受欢迎的工作平台Jupyter Notebooks,运用原始数据和隐私保护的数据来预测工薪阶层。本文将运用CryptoNumerics的隐私文件库进行隐私算法,运用sklearn进行回归分析。
CryptoNumerics隐私文件库文献:https://cryptonumerics.com/cn-protect-for-data-science/?utm_source=DZone
现在来看看例子吧。
首先,输入文件库。

将数据集读入Pandas。

接下来选择隐私模型。本案例将使用k匿名(k-anonymity)。如果个体无法被k-1个体识别,那么该数据集就是k匿名的。换句话说,数据集里每个数据点都在一个数据组群中,该组群中至少有k个数据点不会被攻击者识别。现在将k值设为5,但是k值可以根据风险需求进行调整。

之后选择一个质量模型。如果隐私模型被定义为隐私约束条件,鉴于此,质量模型需要进行优化。因而系统默认值为“信息损失”或简写为“损失”。基本上质量模型需要涵盖一个隐私的数据集,且同时将损失的信息减至最少。
广义上,有两种方式可以修改数据集并保护隐私,但这最终也会引发信息损失:
一般化——每一栏都被替换成更一般化的数据。比如,邮编被泛化后要编辑字符,那么12345或12346都将被替换成123**。再比如,年龄19、25、26都将换成区间,也就是[10-19]及[20-29]。
抑制——每一行都将从数据集中移除(由空字符*代替)。当某些特殊的数据点难以概括时,抑制是有效的。比如,当仅有一人在[60-80]的年龄区间,且不希望数据点被识别时,与其创造一个更大的年龄区间(假设[40-80]),不如直接将此人从数据集中移除,只保留内容详实且隐私的信息。
但是实施抑制的过程就如参数一般,是一场交易。人们可以设置抑制的界限,即算法最多可抑制的行数。假设设置界限为0.1,那么不超过(有可能远远小于)10%的行数会被编辑。换句话说,就是将最多10%的行数定为可移除的“异常值”。

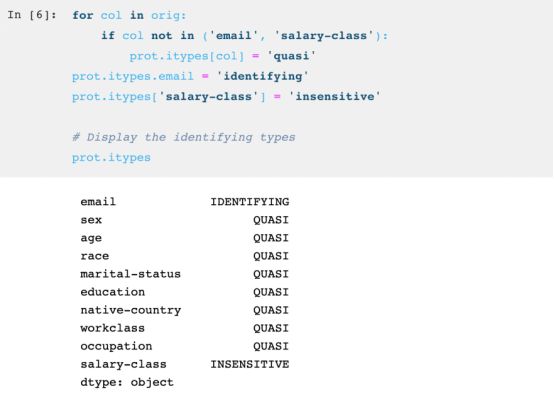
现在将四种隐私特质分配给数据:
识别性:这类数据,如社会安全号码,可以凭借自身轻松地对他人进行重新识别。
准识别性:这类数据本身在重新识别方面风险较小。在与其他数据并行时,它们能可靠地连接到公开记录中的信息。这类数据包括性别、邮编及出生日期。
敏感性:这类数据不会给重新识别带来风险,但是一旦揭露了个人纪录,客户会受到伤害。具体例子如医疗诊断、政治性捐款及网络浏览历史。
不灵敏性:这类数据点没有隐私风险。
完成数据集隐私保护的最后一个步骤是创造层级。
运用层级是为了让算法能够概括列。一个层级可辨别保护隐私的方式,比如,依据不同的概括度,层级可以用以下间隔[10-14]、[10-19]、[0-19]来替换年龄11。
有几种方式可以自动创造层级,或在DataFrame中手动将层级分类。首先,本文将运用OrderHierarchy自动地创造一个年龄层级。在创造层级的方式中,OrderHierarchy不仅是最简单的方式之一,且很好地满足了多种需求。第一个参数“间隔”表明输出的格式应为[最低-最高]。剩下的参数(用乘法)表明间隔的大小。举例来说,5,2,2意味着为大小为5,10,20的间隔提供选项。由于OrderHierarchy总是从数据集中最小的元素开始,因此最小的间隔总是像[17-26]这样的间隔。
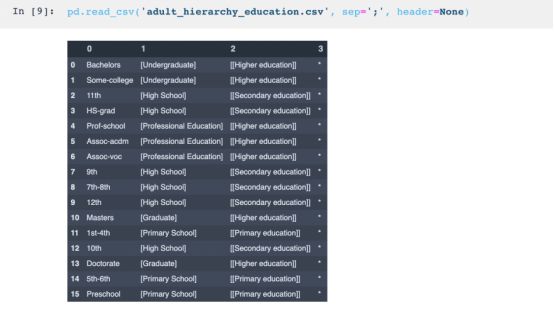
剩下的层级可以通过.csv文档中的数据框架进行分类。接下来展示的是教育层级。每一列指定了一种概括程度,第一列包含了所有可能的原始数据值,连续的每一列都代表更深入的概括程度。最后一个级别表示列的完全移除。请注意,本文用括号注明了何种程度的概括曾被使用,在实践中无需如此。
所有参数都已设置完毕,现在将运用保护目标上的protect()进行转化。结果显示了符合隐私模型标准的匿名数据框架(只要数据框架尚存的话)。要注意的是,其形状仍与原本的一样,因为被移除或被概括的单元格均直接用*表示。

再看看一些重要数据:
信息损失表明被编辑信息的比重,这是经过优化的值。
最高风险指的是数据集的隐私风险。数据集里一个个体被重新识别的可能性为20%。
最小种类大小即k值。本文早些时候将其设为5.

接下来将进行两项逻辑回归分析,以比较隐私保护的应用会如何影响数据集的分析价值。
首先对原始(初始)数据进行分析:
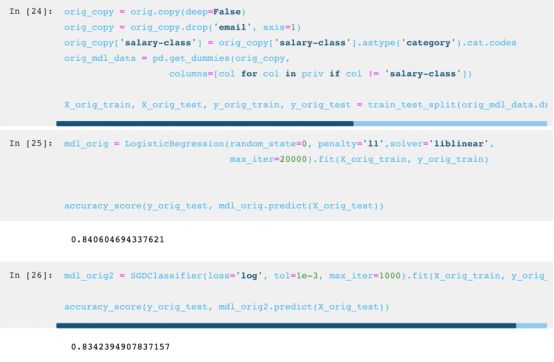
最后对隐私保护的数据进行分析:

如图所示,尽管最后出现了极小的精度损失(0.26%),但潜在数据的隐私得到了保护。
在实践中,数据集越大性能就越好:观察结果越多,意味着更多的机会观察值会被分到等值种类中(k群),因而满足隐私模型的约束条件也就更容易。这表明,数据集变大,精确度会提高。

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你