Hive中压缩设置 和 Hive文件存储格式及使用
Hive中压缩设置 和 Hive文件存储格式及使用
(一)Hive文件存储格式
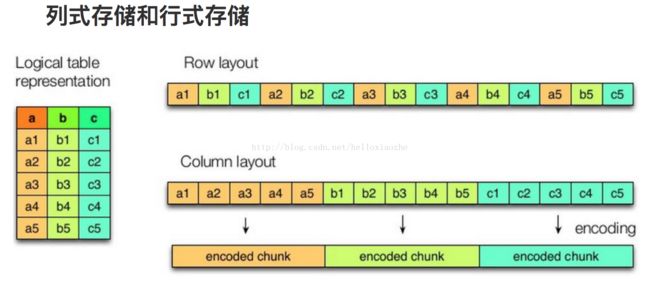
上图左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
(1)Hive中常用的存储格式
1.1 textfile
textfile为默认格式,存储方式为行存储。
1.2 ORCFile
hive/spark都支持这种存储格式,它存储的方式是采用数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。特点是数据压缩率非常高。
1.3 Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
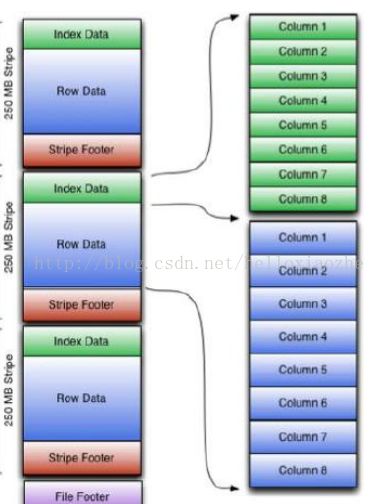
(2)根据不同的格式创建表
2.1 textfile创建表
create table textfile(
...
...
...
)
row format delimited fields terminated by '\t'
stored as textfile;
insert into table textfile select * from source_log;查看占用的磁盘空间
hadoop dfs -du -h hdfs://localhost:9002/user/hive/warehouse/yyz_workdb.db/textfile2.2 orc创建表
create table orc(
...
...
...
)
row format delimited fields terminated by '\t'
stored as orc;
insert into table orc select * from source_log;hadoop dfs -du -h hdfs://localhost:9002/user/hive/warehouse/yyz_workdb.db/orc
2.3 parquet创建表
create table parquet(
...
...
...
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table parquet select * from source_log;hadoop dfs -du -h hdfs://localhost:9002/user/hive/warehouse/yyz_workdb.db/parquet
磁盘空间占用大小比较
orc
这个大小趋势适用于较大的数据,在数据量较小的情况下,可能会出现与之相悖的结论
(4) 查询语句的比较
4.1 textfile表
hive (count_log)> select id from textfile limit 30;
4.2 orc表
hive (count_log)> select id from orc limit 30;
4.3 parquet表
hive (count_log)> select id from parquet limit 30;
查询语句运行时间大小比较
orc
这个大小趋势适用于较大的数据,在数据量较小的情况下,可能会出现与之相悖的结论
把设置存储格式和压缩结合使用,可以最大的减少存储空间。
(二)Hive中压缩设置
1. Hive中间数据压缩
hive.exec.compress.intermediate:默认该值为false,设置为true为激活中间数据压缩功能。HiveQL语句最终会被编译成Hadoop的Mapreduce job,开启Hive的中间数据压缩功能,就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩。在这个阶段,优先选择一个低CPU开销的算法。
mapred.map.output.compression.codec:该参数是具体的压缩算法的配置参数,SnappyCodec比较适合在这种场景中编解码器,该算法会带来很好的压缩性能和较低的CPU开销。设置如下:
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;2. Hive最终数据压缩
hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。
mapred.output.compression.codec:将hive.exec.compress.output参数设置成true后,然后选择一个合适的编解码器,如选择SnappyCodec。设置如下:
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec3.Hive中文件格式说明
常见的hive文件存储格式包括以下几类:TEXTFILE、SEQUENCEFILE、RCFILE、ORC。其中TEXTFILE为默认格式,建表时默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。SequenceFile、RCFile、ORC格式的表不能直接从本地文件导入数据,数据要先导入到TextFile格式的表中,然后再从TextFile表中用insert导入到SequenceFile、RCFile表中。
3.1 TextFile
- Hive数据表的默认格式,存储方式:行存储。
- 可以使用Gzip压缩算法,但压缩后的文件不支持split
- 在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
建表代码
${建表语句}
stored as textfile;
##########################################插入数据########################################
set hive.exec.compress.output=true; --启用压缩格式
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定输出的压缩格式为Gzip
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from T_Name;3.2 Sequence Files
- 压缩数据文件可以节省磁盘空间,但Hadoop中有些原生压缩文件的缺点之一就是不支持分割。支持分割的文件可以并行的有多个mapper程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。Sequence File是可分割的文件格式,支持Hadoop的block级压缩。
- Hadoop API提供的一种二进制文件,以key-value的形式序列化到文件中。存储方式:行存储。
- sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能。
- 优势是文件和hadoop api中的MapFile是相互兼容的
建表代码
${建表语句}
SORTED AS SEQUENCEFILE; --将Hive表存储定义成SEQUENCEFILE
##########################################插入数据########################################
set hive.exec.compress.output=true; --启用压缩格式
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定输出的压缩格式为Gzip
set mapred.output.compression.type=BLOCK; --压缩选项设置为BLOCK
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from T_Name;3.3 RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
- 首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低
- 其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取
- 数据追加:RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的 HDFS当前仅仅支持数据追加写文件尾部。
- 行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。 考虑到存储空间和查询效率两个方面,Facebook 选择 4MB 作为默认的行组大小,当然也允许用户自行选择参数进行配置。
建表代码
${建表语句}
stored as rcfile;
-插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from T_Name;3.4 ORCFile
存储方式:数据按行分块,每块按照列存储。
压缩快,快速列存取。效率比rcfile高,是rcfile的改良版本。
小结
- TextFile默认格式,加载速度最快,可以采用Gzip进行压缩,压缩后的文件无法split,即并行处理。
- SequenceFile压缩率最低,查询速度一般,将数据存放到sequenceFile格式的hive表中,这时数据就会压缩存储。三种压缩格式NONE,RECORD,BLOCK。是可分割的文件格式。
- RCfile压缩率最高,查询速度最快,数据加载最慢。
- 相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
- 在hive中使用压缩需要灵活的方式,如果是数据源的话,采用RCFile+bz或RCFile+gz的方式,这样可以很大程度上节省磁盘空间;而在计算的过程中,为了不影响执行的速度,可以浪费一点磁盘空间,建议采用RCFile+snappy的方式,这样可以整体提升hive的执行速度。至于lzo的方式,也可以在计算过程中使用,只不过综合考虑(速度和压缩比)还是考虑snappy适宜。
(三)为什么要压缩
在Hive中对中间数据或最终数据做压缩,是提高数据吞吐量和性能的一种手段。对数据做压缩,可以大量减少磁盘的存储空间,比如基于文本的数据文件,可以将文件压缩40%或更多。同时压缩后的文件在磁盘间传输和I/O也会大大减少;当然压缩和解压缩也会带来额外的CPU开销,但是却可以节省更多的I/O和使用更少的内存开销。
压缩模式说明
1. 压缩模式评价
可使用以下三种标准对压缩方式进行评价:
- 压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好。
- 压缩时间:越快越好。
- 已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化。
2. 压缩模式对比
- BZip2有最高的压缩比但也会带来更高的CPU开销,Gzip较BZip2次之。如果基于磁盘利用率和I/O考虑,这两个压缩算法都是比较有吸引力的算法。
- LZO和Snappy算法有更快的解压缩速度,如果更关注压缩、解压速度,它们都是不错的选择。 LZO和Snappy在压缩数据上的速度大致相当,但Snappy算法在解压速度上要较LZO更快。
- Hadoop的会将大文件分割成HDFS block(默认64MB)大小的splits分片,每个分片对应一个Mapper程序。在这几个压缩算法中 BZip2、LZO、Snappy压缩是可分割的,Gzip则不支持分割。
3. 常见压缩格式

Hadoop编码/解码器方式,如下表所示 
4. 什么是可分割
在考虑如何压缩那些将由MapReduce处理的数据时,考虑压缩格式是否支持分割是很重要的。考虑存储在HDFS中的未压缩的文件,其大小为1GB,HDFS的块大小为64MB,所以该文件将被存储为16块,将此文件用作输入的MapReduce作业会创建1个输人分片(split,也称为“分块”。对于block,我们统一称为“块”。)每个分片都被作为一个独立map任务的输入单独进行处理。
现在假设,该文件是一个gzip格式的压缩文件,压缩后的大小为1GB。和前面一样,HDFS将此文件存储为16块。然而,针对每一块创建一个分块是没有用的,因为不可能从gzip数据流中的任意点开始读取,map任务也不可能独立于其他分块只读取一个分块中的数据。gzip格式使用DEFLATE来存储压缩过的数据,DEFLATE将数据作为一系列压缩过的块进行存储。问题是,每块的开始没有指定用户在数据流中任意点定位到下一个块的起始位置,而是其自身与数据流同步。因此,gzip不支持分割(块)机制。
在这种情况下,MapReduce不分割gzip格式的文件,因为它知道输入是gzip压缩格式的(通过文件扩展名得知),而gzip压缩机制不支持分割机制。因此一个map任务将处理16个HDFS块,且大都不是map的本地数据。与此同时,因为map任务少,所以作业分割的粒度不够细,从而导致运行时间变长。
(四)Hive文件格式使用
hive文件存储格式包括以下几类:
1、TEXTFILE
2、SEQUENCEFILE
3、RCFILE
4、ORCFILE(0.11以后出现)
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入SequenceFile,RCFile,ORCFile表中。
前提创建环境:
hive 0.8
创建一张testfile_table表,格式为textfile。
create table if not exists testfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as textfile;
load data local inpath '/app/weibo.txt' overwrite into table testfile_table;
1、TEXTFILE
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,
从而无法对数据进行并行操作。
示例:
create table if not exists textfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as textfile; 插入数据操作: set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table textfile_table select * from testfile_table;
2、SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
示例:
create table if not exists seqfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as sequencefile; 插入数据操作: set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; SET mapred.output.compression.type=BLOCK; insert overwrite table seqfile_table select * from testfile_table;
3、RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
RCFILE文件示例:
create table if not exists rcfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as rcfile; 插入数据操作: set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table rcfile_table select * from testfile_table;
四、ORCFILE()
ORCFILE文件示例:
create table if not exists orcfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as orc; 插入数据操作: set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table orcfile_table select * from testfile_table;
五、再看TEXTFILE、SEQUENCEFILE、RCFILE三种文件的存储情况:
[hadoop@node3 ~]$ hadoop dfs -dus /user/hive/warehouse/* hdfs://node1:19000/user/hive/warehouse/hbase_table_1 0 hdfs://node1:19000/user/hive/warehouse/hbase_table_2 0 hdfs://node1:19000/user/hive/warehouse/orcfile_table 0 hdfs://node1:19000/user/hive/warehouse/rcfile_table 102638073 hdfs://node1:19000/user/hive/warehouse/seqfile_table 112497695 hdfs://node1:19000/user/hive/warehouse/testfile_table 536799616 hdfs://node1:19000/user/hive/warehouse/textfile_table 107308067 [hadoop@node3 ~]$ hadoop dfs -ls /user/hive/warehouse/*/ -rw-r--r-- 2 hadoop supergroup 51328177 2014-03-20 00:42 /user/hive/warehouse/rcfile_table/000000_0 -rw-r--r-- 2 hadoop supergroup 51309896 2014-03-20 00:43 /user/hive/warehouse/rcfile_table/000001_0 -rw-r--r-- 2 hadoop supergroup 56263711 2014-03-20 01:20 /user/hive/warehouse/seqfile_table/000000_0 -rw-r--r-- 2 hadoop supergroup 56233984 2014-03-20 01:21 /user/hive/warehouse/seqfile_table/000001_0 -rw-r--r-- 2 hadoop supergroup 536799616 2014-03-19 23:15 /user/hive/warehouse/testfile_table/weibo.txt -rw-r--r-- 2 hadoop supergroup 53659758 2014-03-19 23:24 /user/hive/warehouse/textfile_table/000000_0.gz -rw-r--r-- 2 hadoop supergroup 53648309 2014-03-19 23:26 /user/hive/warehouse/textfile_table/000001_1.gz
总结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
http://www.jianshu.com/p/694f044d1c34
http://blog.csdn.net/xsdxs/article/details/53152599
http://www.cnblogs.com/Richardzhu/p/3613661.html