keras入门 ---用预训练好网络模型的bottleneck特征
在深度学习的学习过程中,我们可能会用到一些已经训练好的模型,比如 Alex Net, google net, VGG net, ResNet等,那我们怎么使用这些已经训练好的模型呢?
在这篇博客中,我们使用已经训练好的VGG16模型来帮助我们进行这个分类任务,因为我们要分类的是猫,狗这类物体,而VGG net是在imageNet上训练的,而imageNet实际上已经包含了这2中物体。
我们的方法是这样的,我们将利用网络的卷积层部分,把全连接以上的部分抛掉。然后在我们的训练集和测试集上跑一遍,将得到的输出(即“bottleneck feature”,网络在全连接之前的最后一层激活的feature map)记录在两个numpy array里。然后我们基于记录下来的特征训练一个全连接网络。 然后我们把这个已经feature在我们自己定义的很小的模型上跑一遍,这样速度会快很多.
VGG16模型结果如下:
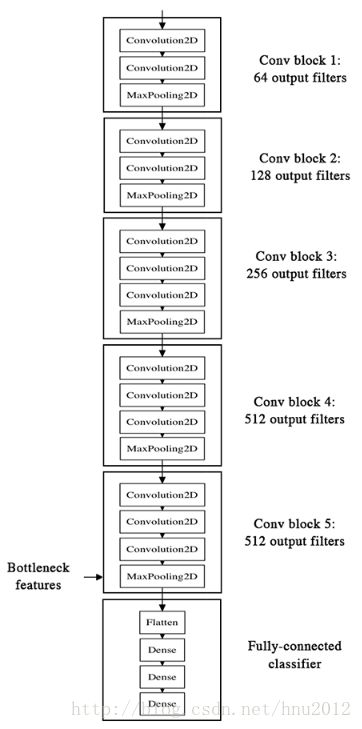
通过VGG16获取bottleneck 特征:
# build the VGG16 network
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=(3, img_width, img_height)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
# load the weights of the VGG16 networks
# (trained on ImageNet, won the ILSVRC competition in 2014)
# note: when there is a complete match between your model definition
# and your weight savefile, you can simply call model.load_weights(filename)
assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
# we don't look at the last (fully-connected) layers in the savefile
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
bottleneck_features_train = model.predict_generator(generator, nb_train_samples)
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)然后用得到的bottleneck特征来进行训练:
train_data = np.load(open('bottleneck_features_train.npy'))
train_labels = np.array([0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * (nb_validation_samples / 2) + [1] * (nb_validation_samples / 2))
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels,
nb_epoch=nb_epoch, batch_size=32,
validation_data=(validation_data, validation_labels))
model.save_weights(top_model_weights_path)这样一个很简单的模型50个epoch后就可以达到一个接近0.9的auc,并且时间很快.
源代码和数据库在code and dataset.
参考文档:https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html