轻量化网络mobileNet与ShuffleNet
摘要
最近出了一篇旷视科技的孙剑团队出了一篇关于利用Channel Shuffle实现的卷积网络优化——ShuffleNet。我关注了一下,原理相当简单。它只是为了解决分组卷积时,不同feature maps分组之间的channels信息交互问题,而提出Channel Shuffle操作为不同分组提供channels信息的通信的渠道。然而,当我读到ShuffleNet Unit和Network Architecture的章节,考虑如何复现作者的实验网络时,总感觉看透这个网络的实现,尤其是我验算Table 1的结果时,总出现各种不对。因此我将作者引用的最近几个比较火的网络优化结构(MobileNet,Xception,ResNeXt)学习了一下,终于在ResNeXt的引导下,把作者的整个实现搞清楚了。顺带着,我也把这项技术的发展情况屡了一下,产生了一些个人看法,就写下这篇学习笔记。
关键词: MobileNet,Xception,ResNeXt,ShuffleNet, MobileID
一、前言
1.背景概述
自从2016年3月,谷歌用一场围棋比赛把人工智能(AI, Artificial Intelligence)正式推上了风口。深度学习突然间成为了整个IT行业的必备知识,不掌握也需要去了解。然而,在2014年我刚毕业的时候,这项技术并没有现在那么火。当时概念大家都还是比较模糊,我也只是在实习听报告时,听邵岭博士提了一下,却没想到现在已经成为模式识别界的一枚巨星。尽管我后悔当时没在这块狠下功夫,但庆幸还能赶上末班船的站票。
CNN的提出其实很早,在1985年Hinton就提出了BP(反向传播算法),1998年LeCun就基于这项工作发表了LeNet用于解决手写邮政编码的识别问题。之后这项技术很少人去接触,有观点认为当时并没有资源能承担CNN的计算消耗。而它的转折点却是十多年后,在ImageNet比赛中,Alex在Nvidia的两GPU上跑他设计的AlexNet架构,成功在众人面前秀了一把CNN的并行计算操作并一举夺冠,吸引了少量学者眼球。两年过去,VGG和GoogLeNet在ImageNet上展开冠军争夺战,标志着深度学习正式起跑,业界开始关注并尝试利用CNN解决一些过去的难题,比如目标跟踪,目标检测,人脸识别等,它这些领域也得到了不少突破。
然而,CNN的这些突破大多都是在计算代价巨大的条件下产生的,比方说令人目瞪狗呆的千层网络—ResNet。其实这并不利于深度学习在消费类产业的推广,毕竟消费类产品很多是嵌入式的终端产品,而且嵌入式芯片的计算性能并不很强。即使我们考虑云计算,也需要消耗大量的带宽资源和计算资源。因此,CNN的优化已成为深度学习产品能否在消费市场落脚生根的一个重要课题之一。所以,有不少学者着手研究CNN的网络优化,如韩松的SqueezeNet,Deep Compression,LeCun的SVD,Google的MobileNet以及这个孙剑的ShuffleNet等。
其实,网络压缩优化的方法有两个发展方向,一个是迁移学习,另一个是网络稀疏。迁移学习是指一种学习对另一种学习的影响,好比我们常说的举一反三行为,以减少模型对数据量的依赖。不过,它也可以通过知识蒸馏实现大模型到小模型的迁移,这方面的工作有港中文汤晓鸥组的MobileID。他们运用模型压缩技术和domain knowledge,用小的网络去拟合大量的数据,并以大型teacher network的知识作为监督,训练了一个小而紧凑的student network打算将DeepID迁移到移动终端与嵌入式设备中。本文先不对这项工作进行详细介绍,后面打算再补充一篇相关博文。网络稀疏是现在比较主流的压缩优化方向,这方面的工作主要是以网络结构的剪枝和调整卷积方式为主。比如之前提到深度压缩,它先通过dropout,L1/L2-regularization等能产生权重稀疏性的方法训练体积和密度都很大的网络,然后把网络中贡献小(也就是被稀疏过的)的权重裁剪掉,相当于去除了一些冗余连接,最后对模型做一下fine-tune就得到他所说的30%压缩率的效果。但它在效率上的提高并不适合大多数的通用CPU,因为它的存储不连续,索引权重时容易发生Cache Miss,反而得不偿失。下面介绍的MobileNet在这方面更有优势。
2.论文解读
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
原文地址:MobileNetV1
代码:
- TensorFlow官方
- github-Tensorflow
- github-Caffe
Abstract
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。
论文介绍了两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。
Introduction
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
Related Work
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
-
压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
-
直接训练小型模型。 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
本文提出的MobileNet网络架构,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
Architecture
Depthwise Separable Convolution
MobileNet是基于深度可分离卷积的。通俗的来说,深度可分离卷积干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处是可以大幅度降低参数量和计算量。分解过程示意图如下:
输入的特征映射F
尺寸为(DF,DF,M),采用的标准卷积K为(DK,DK,M,N)(如图(a)所示),输出的特征映射为G尺寸为(DG,DG,N)
标准卷积的卷积计算公式为:
Gk,l,n=∑i,j,mKi,j,m,n⋅Fk+i−1,l+j−1,m
输入的通道数为M,输出的通道数为N。对应的计算量为:DK⋅DK⋅M⋅N⋅DF⋅DF
可将标准卷积(DK,DK,M,N)
拆分为深度卷积和逐点卷积:
- 深度卷积负责滤波作用,尺寸为(DK,DK,1,M)
如图(b)所示。输出特征为(DG,DG,M)
- 逐点卷积负责转换通道,尺寸为(1,1,M,N)
- 如图(c)所示。得到最终输出为(DG,DG,N)
深度卷积的卷积公式为:
G^k,l,n=∑i,jK^i,j,m⋅Fk+i−1,l+j−1,m
其中K^是深度卷积,卷积核为(DK,DK,1,M),其中mth个卷积核应用在F中第mth个通道上,产生G^上第mth个通道输出.深度卷积和逐点卷积计算量:DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF
计算量减少了:
DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DFDK⋅DK⋅M⋅N⋅DF⋅DF=1N+1D2K
深度分类卷积示例
输入图片的大小为(6,6,3)
,原卷积操作是用(4,4,3,5)的卷积(4×4是卷积核大小,3是卷积核通道数,5个卷积核数量),stride=1,无padding。输出的特征尺寸为6−41+1=3,即输出的特征映射为(3,3,5)将标准卷积中选取序号为n
的卷积核,大小为(4,4,3),标准卷积过程示意图如下(注意省略了偏置单元):
黑色的输入为(6,6,3)
与第n个卷积核对应,每个通道对应每个卷积核通道卷积得到输出,最终输出为2+0+1=3。(这是常见的卷积操作,注意这里卷积核要和输入的通道数相同,即图中表示的3个通道~)
对于深度分离卷积,把标准卷积(4,4,3,5)
分解为:
,作用在输入的每个通道上,输出特征映射为(3,3,3)- 深度卷积部分:大小为(4,4,1,3)
-
可视化结果:
Conclusion
论文提出了一种基于深度可分离卷积的新模型MobileNet,同时提出了两个超参数用于快速调节模型适配到特定环境。实验部分将MobileNet与许多先进模型做对比,展现出MobileNet的在尺寸、计算量、速度上的优越性。
代码分析
这里参考的代码是mobilenet.py文件(当然也可以参考TensoeFlow官方的MobileNet)
TensorFlow有实现好的深度卷积API,所以整个代码非常整洁的~
''' 100% Mobilenet V1 (base) with input size 224x224: See mobilenet_v1() Layer params macs -------------------------------------------------------------------------------- MobilenetV1/Conv2d_0/Conv2D: 864 10,838,016 MobilenetV1/Conv2d_1_depthwise/depthwise: 288 3,612,672 MobilenetV1/Conv2d_1_pointwise/Conv2D: 2,048 25,690,112 MobilenetV1/Conv2d_2_depthwise/depthwise: 576 1,806,336 MobilenetV1/Conv2d_2_pointwise/Conv2D: 8,192 25,690,112 MobilenetV1/Conv2d_3_depthwise/depthwise: 1,152 3,612,672 MobilenetV1/Conv2d_3_pointwise/Conv2D: 16,384 51,380,224 MobilenetV1/Conv2d_4_depthwise/depthwise: 1,152 903,168 MobilenetV1/Conv2d_4_pointwise/Conv2D: 32,768 25,690,112 MobilenetV1/Conv2d_5_depthwise/depthwise: 2,304 1,806,336 MobilenetV1/Conv2d_5_pointwise/Conv2D: 65,536 51,380,224 MobilenetV1/Conv2d_6_depthwise/depthwise: 2,304 451,584 MobilenetV1/Conv2d_6_pointwise/Conv2D: 131,072 25,690,112 MobilenetV1/Conv2d_7_depthwise/depthwise: 4,608 903,168 MobilenetV1/Conv2d_7_pointwise/Conv2D: 262,144 51,380,224 MobilenetV1/Conv2d_8_depthwise/depthwise: 4,608 903,168 MobilenetV1/Conv2d_8_pointwise/Conv2D: 262,144 51,380,224 MobilenetV1/Conv2d_9_depthwise/depthwise: 4,608 903,168 MobilenetV1/Conv2d_9_pointwise/Conv2D: 262,144 51,380,224 MobilenetV1/Conv2d_10_depthwise/depthwise: 4,608 903,168 MobilenetV1/Conv2d_10_pointwise/Conv2D: 262,144 51,380,224 MobilenetV1/Conv2d_11_depthwise/depthwise: 4,608 903,168 MobilenetV1/Conv2d_11_pointwise/Conv2D: 262,144 51,380,224 MobilenetV1/Conv2d_12_depthwise/depthwise: 4,608 225,792 MobilenetV1/Conv2d_12_pointwise/Conv2D: 524,288 25,690,112 MobilenetV1/Conv2d_13_depthwise/depthwise: 9,216 451,584 MobilenetV1/Conv2d_13_pointwise/Conv2D: 1,048,576 51,380,224 -------------------------------------------------------------------------------- Total: 3,185,088 567,716,352 ''' def mobilenet(inputs, num_classes=1000, is_training=True, width_multiplier=1, scope='MobileNet'): """ MobileNet More detail, please refer to Google's paper(https://arxiv.org/abs/1704.04861). Args: inputs: a tensor of size [batch_size, height, width, channels]. num_classes: number of predicted classes. is_training: whether or not the model is being trained. scope: Optional scope for the variables. Returns: logits: the pre-softmax activations, a tensor of size [batch_size, `num_classes`] end_points: a dictionary from components of the network to the corresponding activation. """ # depthwise_separable_conv内包含深度卷积和逐点卷积 def _depthwise_separable_conv(inputs, num_pwc_filters, width_multiplier, sc, downsample=False): """ Helper function to build the depth-wise separable convolution layer. """ num_pwc_filters = round(num_pwc_filters * width_multiplier) _stride = 2 if downsample else 1 # 设置num_outputs=None跳过逐点卷积 depthwise_conv = slim.separable_convolution2d(inputs, num_outputs=None, stride=_stride, depth_multiplier=1, kernel_size=[3, 3], scope=sc+'/depthwise_conv') bn = slim.batch_norm(depthwise_conv, scope=sc+'/dw_batch_norm') # 逐点卷积变换通道 pointwise_conv = slim.convolution2d(bn, num_pwc_filters, kernel_size=[1, 1], scope=sc+'/pointwise_conv') bn = slim.batch_norm(pointwise_conv, scope=sc+'/pw_batch_norm') return bn with tf.variable_scope(scope) as sc: end_points_collection = sc.name + '_end_points' with slim.arg_scope([slim.convolution2d, slim.separable_convolution2d], activation_fn=None, outputs_collections=[end_points_collection]): with slim.arg_scope([slim.batch_norm], is_training=is_training, activation_fn=tf.nn.relu, fused=True): # 定义整体结构 net = slim.convolution2d(inputs, round(32 * width_multiplier), [3, 3], stride=2, padding='SAME', scope='conv_1') net = slim.batch_norm(net, scope='conv_1/batch_norm') net = _depthwise_separable_conv(net, 64, width_multiplier, sc='conv_ds_2') net = _depthwise_separable_conv(net, 128, width_multiplier, downsample=True, sc='conv_ds_3') net = _depthwise_separable_conv(net, 128, width_multiplier, sc='conv_ds_4') net = _depthwise_separable_conv(net, 256, width_multiplier, downsample=True, sc='conv_ds_5') net = _depthwise_separable_conv(net, 256, width_multiplier, sc='conv_ds_6') net = _depthwise_separable_conv(net, 512, width_multiplier, downsample=True, sc='conv_ds_7') net = _depthwise_separable_conv(net, 512, width_multiplier, sc='conv_ds_8') net = _depthwise_separable_conv(net, 512, width_multiplier, sc='conv_ds_9') net = _depthwise_separable_conv(net, 512, width_multiplier, sc='conv_ds_10') net = _depthwise_separable_conv(net, 512, width_multiplier, sc='conv_ds_11') net = _depthwise_separable_conv(net, 512, width_multiplier, sc='conv_ds_12') net = _depthwise_separable_conv(net, 1024, width_multiplier, downsample=True, sc='conv_ds_13') net = _depthwise_separable_conv(net, 1024, width_multiplier, sc='conv_ds_14') net = slim.avg_pool2d(net, [7, 7], scope='avg_pool_15') end_points = slim.utils.convert_collection_to_dict(end_points_collection) net = tf.squeeze(net, [1, 2], name='SpatialSqueeze') end_points['squeeze'] = net # 接FC再接Softmax logits = slim.fully_connected(net, num_classes, activation_fn=None, scope='fc_16') predictions = slim.softmax(logits, scope='Predictions') end_points['Logits'] = logits end_points['Predictions'] = predictions return logits, end_points mobilenet.default_image_size = 224
下个章节就到本博客的主要讨论对象ShuffleNet了。这里我想穿插一段关于论文的题外话,由于受论文审评流程等影响,一般follow到一篇工作的时间会比writer做这篇文章(包括找点、实验、成文等,实验报告可以认为是成果)的时间晚个半年到一年左右,甚至再有的保密成果,两年也是有可能的。因此arxiv的论文基本很前沿了,能看到初稿,那基本可认为是两三月前的设计成果。为何说到这,因为我们能看到 ShuffleNet 在 arxiv 上的日期是 2017.7.4 ,而 ResNeXt 的日期是 2016.11.6-2017.4.11 ,所以 ShuffleNet 是很有眼光的,在ResNeXt 未被正式接受的时候就 follow 了,不然三个月搞一篇高水平估计挺折腾的。看来每一篇 Popular Paper 都有它的雏型,越早 follow 越能找到主动性观点。
二、ShuffleNet
由于本人近段时间患上拖延症,当我写到这里的时候,出一段与 ShuffleNet 相关的行业新闻。新闻的内容是雷总在小米发布会上,展现了新款手机小米MIX2,它自带的 0.5 秒人脸识别自动解锁功能让我很是感兴趣。因为合作方貌似就是本博主角 ShuffleNet 的作者团队 Face++ ,所以小米MIX2该功能的技术基础很有可能就是我正在介绍的 ShuffleNet。小米发布会的时间是 2017.9.11 ,也就是 ShuffleNet 挂在 arxiv 后的两个月,做一个应用落地这个时间很充足。而且,据我对 FaceNet 的了解,其实人脸识别用时很少的,尤其这种解锁应用,基本是需要足够近的情况下实做识别,输入图像分辨率不需要很大。再是,与用户交互实现解锁,因此可以不做人脸定位,一般人脸定位比识别时耗更高。最后,一部手机最多3个主人,再多就没必要上锁,也就是anchor特别少,匹配次数不多。所以,500ms 基本全是 ShuffleNet 在跑了。我再补充点人脸识别算法知识,现在深度学习做的人脸识别流程,比过去简单很多,可以不需要 landmarks,大致就是输入图先进入 CNN 得到出特征向量,再跟用户录入的特征向量做直接匹配,匹配成功解锁就好。最后,我认为这个 ShuffleNet 应该很深,因为我用小米 Note5A 跑 MobileNet 也到不了 300ms,除非 Face++ 团队在CPU上优化不到位,不然直接使用 ShuffleNet 不会这么慢。
开始进入正题,因为有前面三个网络的知识储备,所以我只对 ShuffleNet 的一些让我关注的点做介绍,打算详细了解它的读者,可以把原文好好读读。首先,还是介绍ShuffleNet的主要工作,而我认为它的主要贡献是相比 MobileNet 提高了准确率,还就如前文所述,突显了分组卷积在运算效率上的优势。
然后,我们分析一下 Xception 与 ResNeXt 的问题。先说效率,Xception 和 ResNeXt 所引入的 depthwise separable convolution 和 group convolution 虽然能协调模型的能力与计算量,但被发现它们的 pointwise convolution 占据着很大的计算量。因此ShuffleNet考虑引入 pointwise group convolution 来解决这个问题,后文有例子能看出这点。再说准确率,前面也提到过 ResNeXt 的 CC 参数是有极限的,也就是说给 ResNeXt 调参是没有前途的,仅有的参数还有极限。而且 group convolution 用 groups 数来协调模型效果与计算量,这本身就是一对技术矛盾。TRIZ理论告诉我们遇到技术矛盾,一定要打消协调的念头,并深入挖掘矛盾本质,寻找机会消除矛盾。我认为 ShuffleNet 解决这两个问题的思路是,先引入 pointwise group convolution 解决效率问题,再想办法把它所带来的次级问题与原来的效果问题合在一起解决,原因是次级问题也是group的调整。实际上,引入 pointwise group convolution 可以认为利用 TRIZ 的 STC 算子或提前做原则,这跟 Xception 把 groups 分到最小变成 depthwise 的极限思路也像。既然 ResNeXt 在瓶颈模块中间采用了 splitting 策略,为何就不在输入就采用这种策略呢?这样不网络整体就分离了么?然而,这个分组数 gg 跟 CardinalityCardinality 一样影响着模型的能力,由此 pointwise group convolution 带来了次级问题。而这个问题的本质是什么呢?对比分组卷积和常规卷积的运算规则,我们能够发现根本矛盾可能是分组卷积没有 Channel Correlation,那么需要解决的矛盾就变成如何让分组卷积也有 Channel Correlation。Face++ 用 Channel Shuffle 来解决这个问题。
如上图(b)所示,Input 分成 3 组并分别做了对应的变换(3x3 GConv1),然后在下一次变换(3x3 GConv2)之前做了一次分组间的 Channel Shuffle。如此一来,每个分组就含有了 其它分组的局部 Channel Correlation 了。如果 Channel Shuffle 次数足够多,我觉着就可以认为这完全等效于常规卷积运算了。这是一个不错的创新点,只是效率看起来并不那么完美,原因是 Channels Shuffle 操作会导致内存不连续这个影响有待评估。另外,即使两个分组的大小不一样,Channel Shuffle 仍然是可以做的。
ShuffleNet 以 Channel Shuffle 为基础构造出 ShuffleNet Unit,最后我们看一下这个 ShuffleNet Unit。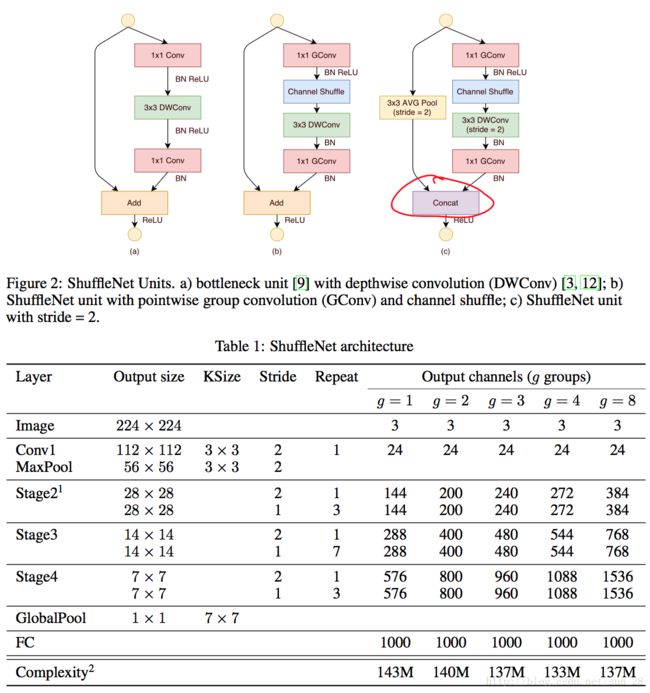
对于上图 Figure2(a) 的ResNet瓶颈模块,比如输入大小为 c×h×wc×h×w 与 瓶颈channels数为 mm 的情况,ResNet 模块的计算量是 hw(2cm+9m2)hw(2cm+9m2) FLOPs,ResNeXt 模块的计算量是 hw(2cm+9m2/g)hw(2cm+9m2/g) FLOPs, 而 ShuffleNet 模块是 hw(2cm/g+9m)hw(2cm/g+9m) FLOPs,其中 gg 代表分组数。可以看出,ShuffleNet 确实比 ResNeXt 要少些计算量。另外,我之前在验算上图 Table1 的时候,犯了个概念性错误。这里给大家指出一下,就是上图 Figure2 的 1×11×1 GConv 跟 ResNeXt 的并不一样,ResNeXt 的输入卷积组可以等效成一个常规的 1×11×1 卷积,但1×11×1 GConv 完全不能等效,因为对于不同分组的 GConv 的输入维度是不一样的。下面我给出 Table1 Stage3(g=2)的流程笔记。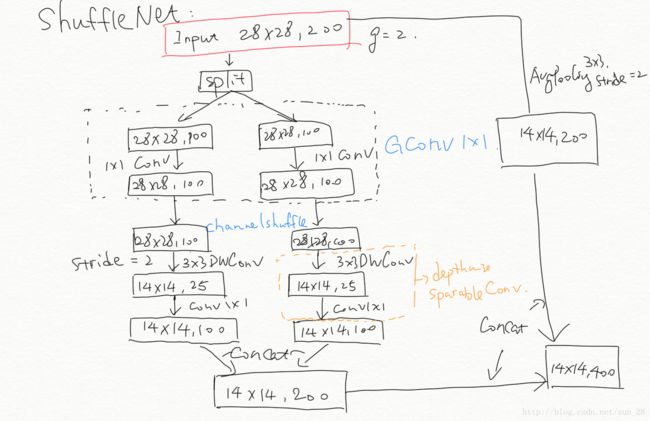
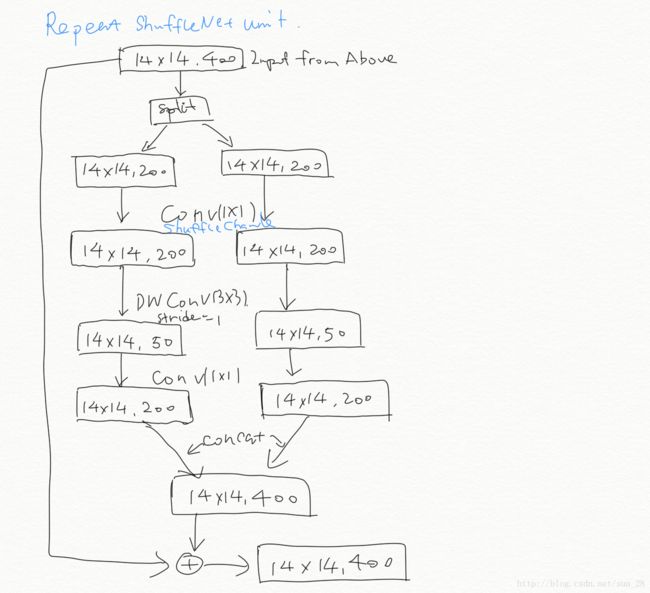
Repeat ShuffleNet unit 用的是 Figure2(b) 结构,Stage之间的过渡会用 Figure2(c) 结构。顺着笔记结构的思路去验证Table 1,我们会发现 Complexity 基本一致,那么复现 ShuffleNet 是完全有可能的。值得一提的是,ShuffleNet 虽然引入了 Channel Shuffle,但是它还是留了分组数 gg 用来控制 pointwise convolution 的稀疏性,这个参数跟 ResNeXt 的 CC 一样。
小结一下 ShuffleNet,通过引入 Channel Shuffle 解决分组卷积的 Channel Correlation 问题,并充分验证它的有效性,同时具备理论创新与实用性。理论上,用了一种轻量级的方法解决了 AlexNet 原有的分组并行信息交互问题。而且这个网络的效率很高,适合嵌入式产品,我怀疑小米 MIX2 的人脸解锁用了这个网络。美中不足的是,Channel Shuffle 看起来对现有 CPU 不大友好,毕竟破坏了数据存储的连续性,使得 SIMD 的发挥不是特别理想,估计在实现上需要再下点功夫。
三、最后总结
其实现在网络优化的思路是,数据的密集连续性和连接的稀疏性。这是一个密集连续性与稀疏性的矛盾。现代计算架构的Cache预取机制更擅长存储密集型的数据读取,大多的密集型数据会带来高昂的计算量,因此我们希望数据稀疏一些,来减少计算量。但稀疏的数据又恰恰带来了一个相当不友好的访存方式,引入cache miss问题,CPU性能得不到充分利用。而韩松的工作相当于放弃了现代计算架构访存的优势,打算将这个问题转用专用的稀疏访存硬件解决,毕竟计算量是有本质上的下降。而ShuffleNet等人们是从分离物理矛盾情景解决这个问题,数据存储依然密集,但采用了极限的分组卷积,是的数据的计算相对稀疏,所以他们是一条分组卷积的思路。