三、 Hive 逻辑算子及其生成(中)
3.2 Hive主要算子功能实现
3.2.1 TS、SEL以及FIL算子的实现
1、TS算子的实现
TS算子(TableScanOperator)在逻辑上表示table扫描功能,实际table数据的读取由底层的计算引擎完成。如在Map-Reduce框架中,table数据的读取由Hadoop提供的InputFormat类完成。TS内部实现仅仅将从底层计算引擎输入的数据输出给子节点处理。
2、SEL算子的实现
SEL算子(SelectOperator)实现了关系代数中投影运算,从输入的每条表记录中筛选指定的列进行计算。例如:
select a.c1+1 as o1,a.c2*2 as o2 from a表a数据如下:
表3-1 table a字段及数据
| c1 |
c2 |
c3 |
| 1 |
2 |
3 |
| 4 |
5 |
6 |
| 7 |
8 |
9 |
SEL算子从记录中提取c1,c2字段,然后计算select表达式的值,得到结果如下:
| o1 |
o2 |
| 2 |
4 |
| 5 |
10 |
| 8 |
16 |
3、FIL算子的实现
FIL(FilterOperator)实现过滤运算,对应HiveQL的where语句。FIL对输入的记录进行过滤,将不符合where表达式的记录过滤掉,剩下的记录输出给子节点。
以表3-1的数据为例,给定HiveQL语句:
select a.c1+1 as o1,a.c2*2 as o2 from awhere a.c1%2=1该语句生成的算子DAG如下:

TS算子读取表a中的数据,输出给FIL节点,FIL算子将a.c1%2=1的记录输出给SEL算子,其他记录被过滤掉,SEL算子做投影运算,计算a.c1+1和a.c2*2的值,然后输出给FS算子,FS算子将结果输出到临时文件中,最终的计算结果如下:
| o1 |
o2 |
| 2 |
4 |
| 8 |
16 |
可见,a.c1等于4的记录被过滤掉,剩下的记录最终计算输出。
Hive在生成算子DAG时总是将FIL算子放在TS算子的后面,这样做的好处是可以提前过滤数据,减少后续算子处理的数据量。
3.2.2 RS算子的实现
在分布式计算系统中,通常计算过程包括两个阶段:map阶段和reduce阶段。map阶段会将数据分割成若干个数据块,给每个数据块创建一个map任务处理该数据块,处理完成后将中间结果输出;接着创建若干个reduce任务,reduce任务会按照一定规则收集各map任务产生的中间结果,并排序,然后做下一步的处理。
以wordcount程序为例进行说明。wordcount是一个统计文件单词个数的程序。下图给出了wordcount的计算流程。

图3-4 wordcount计算过程
输入数据分两个数据块,分别对应两个map任务,map任务统计数据块中单词的个数,以(key,value)形式输出。reduce阶段,创建了2个reduce任务,分别采集map任务生成的中间数据,采集按照key.hashcode()%reduce_num的值进行;reduce0采集值为0的kv对,reduce1采集值为1的kv对。然后reudce按照key对数据进行排序,最后,对采集到的数据做求和运算,得到每个单词的数量。
reduce采集map中间数据并排序的过程称为shuffle。Hadoop和Spark平台各自实现了shuffle过程。Hive中RS算子(ReduceSinkOperator)则是对shuffle过程的逻辑抽象,它定义了shuffle过程的数据采集规则、排序方式并使用平台相关的OuputCollector对象输出数据。
在介绍RS算子之前,先介绍两个术语:数据分发(partition)VS数据采集。数据分发是从map端的角度来描述数据从map端到reduce端的流动,即数据由map端”主动”分发到了reduce端(实际情况则是数据由reduce端采集过去)。这两个概念事实上等价,一般情况下,我们使用数据分发这个术语。
1)数据分发规则
RS算子以(key,value)的形式输出数据,其中key使用HiveKey对象表示。Hive使用计算平台默认的数据分发规则—HashPartitoner进行数据分发。HashPartitioner使用key.hashcode()%reduce_num的值进行数据分发,数据被分发给对应编号的reduce任务(0对应reduce0,1对应reduce1,以此类推)。HiveKey中定义了数据分发的表达式列表(partitonEval),表达式列表的hashcode作为HiveKey的hashcode,计算代码如下:
for (int i = 0; i < partitionEval.length; i++) {
Object o = partitionEval[i].evaluate(row);
keyHashCode = keyHashCode * 31
+ ObjectInspectorUtils.hashCode(o, partitionObjectInspectors[i]);
}
}当partitionEval列表为空时,Hive将随机分发数据,这种情况下HiveKey的hashcode为随机值。这样可以确保数据分布的均匀性,防止出现数据倾斜。
partitionEval表达式列表由具体的HiveQL语句确定,对于group by语句,partitionEval表达式列表为group by表达式;对于join语句,partitionEval表达式为join on表达式。此外,还可以通过distribute by,cluster by语句指定partition表达式。
2)排序
分布式计算引擎对RS算子输出的(key,value)按照key进行排序。RS中使用keyEval列表存放需要排序的表达式,keyEval被序列化后以二进制形式存放在HiveKey对象中。HiveKey注册Comparator对象,定义排序规则:按照字典序方式对二进制数据进行升序排序。RS使用BinarySortableSerDe对(key,value)进行序列化。BinarySortableSerDe是一种可以排序二进制序列化实现,默认按照升序排序。当需要降序排列时BinarySortableSerDe会先对序列化后的二进制进行反序运算,再按照反序结果进行排序,最后反序列化时再进行一次反序运算,从而实现降序排列。见下面例子:
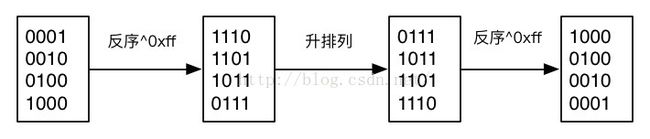
对输入数据0001~1000进行降排序,BinarySortableSerDe先反序运算(通过异或运算符^实现),在按照Comparator默认的升序规则字典排序,反序列化时,再进行反序运算,最终得到降序排列的结果。
RS的keyEval列表也是由具体的HiveQL语句确定。对于group by语句,keyEval为group by表达式;对于join语句,keyEval为join表达式。
3.2.3 GBY算子的实现
GBY算子(GroupByOperator)实现了groupby运算。groupby是sql语句的基本运算功能,通过对数据按照特定字段分组聚合,对分组进行聚合运算。
3.2.3.1 数据聚合方式
Hive中实现数据聚合的方式有两种:hash聚合和sort聚合。hash聚合是基于hash表的聚合方式,将group by key相同的表达式记录聚合在一起,进行聚合运算。这种聚合方式不需要shuffle过程,减少shuffle过程中的网络数据传输。缺点是只能对数据做局部聚合,无法对整个数据进行聚合,一般用于map端分组聚合运算,减少map端的数据输出,类似于map-reduce的combine操作。 sort聚合方式是通过RS算子对数据进行分组排序(partiton和sort),所有groupby key相同的记录被分成一组,然后对每组数据进行聚合运算,这种方式可以得到聚合函数的最终结果。Hive中group by运算都会包含sort聚合方式,hash聚合方式则可以通过配置hive.map.aggr开启/关闭该功能,默认开启。
3.2.3.2 GBY算子实现分析
前文,我们介绍了Hive的数据聚合方式。下面,我们将具体介绍GBY算子的实现,首先介绍GBY算子的主要数据结构,然后介绍GBY算子的两种实现方式:基于hash聚合的GBY和基于sort的GBY。
(1)GBY算子主要数据结构
GBY算子主要数据结构如下:
ExprNodeEvaluator[] keyFields;
ExprNodeEvaluator[][] aggregationParameterFields;
boolean[] aggregationIsDistinct其中:
keyFields:groupby key数组,包含group by表达式和distinct表达式。如语句select id,count(distinctname) from a group by id;keyFields为id和name。ExprNodeEvaluator类用于计算表达式的值。
aggregationParameterFields:二维数组,表示第i个聚合函数的第j个参数表达式。
aggregationIsDistinct:bool数组,表示第i个聚合函数是否含有distinct关键字。
GBY算子的两种实现均在GroupByOperator类中,上面是这两种实现的公共数据结构。
(2)基于hash聚合的GBY实现
基于hash聚合的GBY算子通过hash方式实现数据聚合并计算聚合函数的局部值。除了上面介绍的公共数据结构,与该实现方式相关的数据结构还有如下:
HashMap hashAggregations;
long numRowsInput;
long numRowsHashTbl;
float minReductionHashAggr; hashAggregations是一张hash表,key是group by key的值,封装成KeyWrap对象(group by key的值通过keyFields表达式计算得到);value是每个聚合函数局部聚合结果,聚合结果用对象AggregationBuffer表示。聚合函数的计算是一个迭代过程,AggregationBuffer对象存放每次聚合函数的迭代结果。
numRowsInput用于记录处理的记录条数,numRowsHashTble记录hash表(key,value)条数,minReductionHashAggr是一个Hive配置参数(hive.map.aggr.hash.min.reduction),表示hash表的最小散列因子,默认值为0.5。散列因子计算公式为:numRowsHashTble/numRowsInput,即hash表数据条数/总记录条数。散列因子越大,说明记录中key大部分都不相同,hash表的聚合度很低。极端情况下,散列因子为1,这时记录中的所有key都不相同,hash表没有起到任何聚合作用。Hive中,当hash表的散列因子大于配置的最小值时,表示hash表的聚合作用太弱,这时会取消hash聚合方式。
hash聚合的GBY数据计算流程(代码在process方法中)如下:
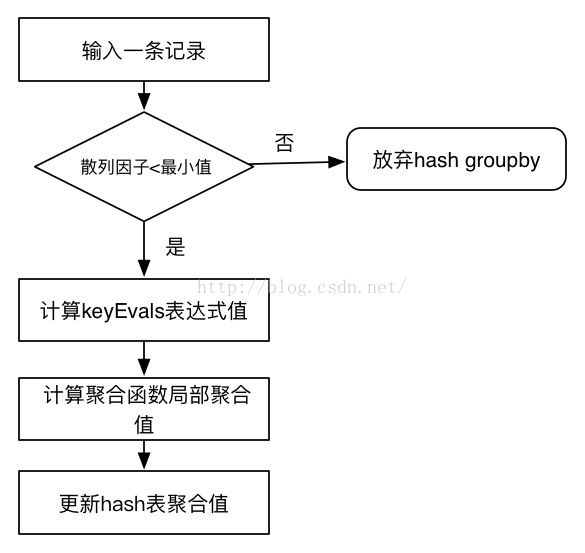
图3-5 hash GBY计算流程
1)GBY的父节点输出一条记录给GBY,GBY先计算散列因子,判断散列因子是否小于设置的最小值。如果大于,放弃hashgroupby,否则执行下一步。
2)计算该记录的group by key的值,通过keyEvals表达式数组进行计算,并封装成KeyWrap对象。如果groupby key的值不在hashAggregations表中,将该KeyWrap对象放入到hashAggregations表中,value值为初始化的AggregationBuffer数组。
3)计算所有聚合函数的局部聚合值。调用聚合函数的iterator()方法,对每条记录进行迭代,计算聚合局部值。注意,如果聚合函数包含distinct参数,那么只有当参数值发生变化的情况下才会对记录做迭代计算,相同的参数只计算一次。例如:count(distinct name)对于相同的name只调用一次count的iterator()方法。
4)更新hashAggregations表。实际上,步骤(3)中计算结果直接保存在AggregationBuffer对象中,AggregationBuffer在初始化时已经存入hash表中,因此,这一步不需要额外操作。
(3)基于sort的GBY实现
基于sort的GBY通过sort聚合方式实现数据分组,并计算每组数据上的聚合函数的最终聚合结果。除了(1)中介绍的公共数据结构,还包含主要数据结构如下:
KeyWrapper currentKeys;
KeyWrapper newKeys;
AggregationBuffer[] aggregations;
Object[][] aggregationsParametersLastInvoke;其中currentKeys表示当前处理的分组的groupby key的值(这里不包含distinct表达式),newKeys表示为每条记录新建的groupby key的值。aggregations存放每条记录处理后聚合函数的计算结果。aggregationsParametersLastInvoke存放上条记录处理的各个聚合函数的参数值。
基于sort GBY算子的数据计算流程如下:
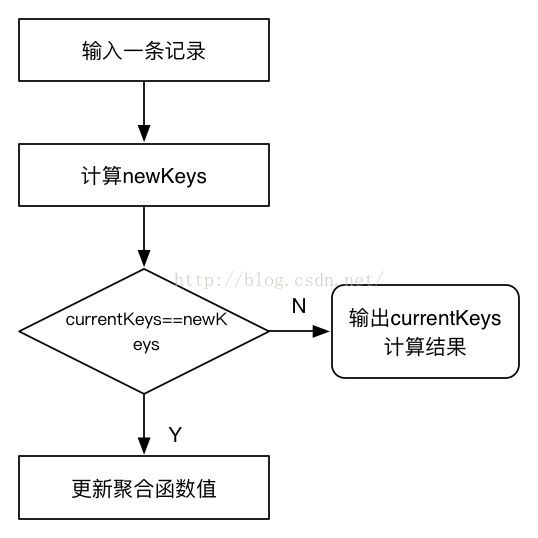
图3-5 hash GBY计算流程
1) 父节点输入一条记录给GBY算子,调用keyEvals表达式计算该记录的groupby key的值,存放到newKeys。
2)比较currentKeys和当前newKeys是否变化。由于sort GBY处理的记录按照groupby key排序,如果发生变化,说明当前分组已经结束,这是输出当前分组的计算结果,否则下一步。
3)更新聚合函数的值。调用聚合函数的merge()方法,合并当前groupby key的局部聚合值。
3.2.3.3 wordcount GBY实现
下面以wordcount为例子,介绍GBY的实现过程。
给定HiveQL语句:
select id,count(word) from a group by idtable a的数据如下表:
| id |
word |
| 0 |
a |
| 1 |
b |
| 0 |
c |
|
|
|
| 0 |
d |
| 1 |
e |
| 1 |
f |
table a包含id和word两个字段,表中数据分成两个数据块,每个数据块3条数据。HiveQL语句按照id分组统计word的数量。该语句对应的算子DAG如下:

下图给出了该DAG的计算过程,map端包含两个map任务,分别处理对应数据分块中的数据,处理流程如下:TS算子顺序读取表记录,输出给SEL算子;SEL算子从记录中帅选id和word字段输出给hash based GBY算子(SEL算子筛选过程图中省略);GBY算子统计数据块内各id的单词个数。RS算子将各map任务的中间结果输出,然后按照group by key,即id排序。排序后,id相同的记录分成一组,输出给sort based GBY进行处理;GBY算子计算每个分组内单词总和,最后通过FS算子输出结果。
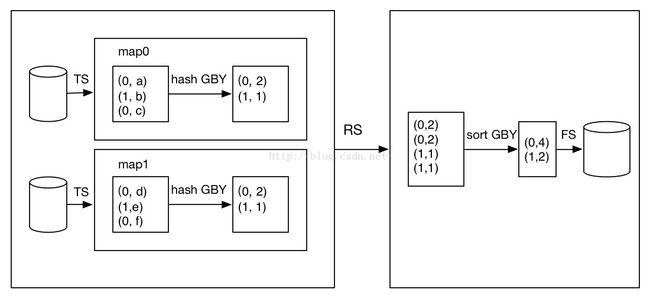
图3-6 wordcount数据处理流程
3.2.4 JOIN算子介绍
JOIN算子(JoinOperator)实现了多张表的join运算。
对于给定HiveQL语句:
select a.*,b.*,c.* from a join b on a.id=b.id join c onb.id=c.id
其算子DAG如图3-7所示。
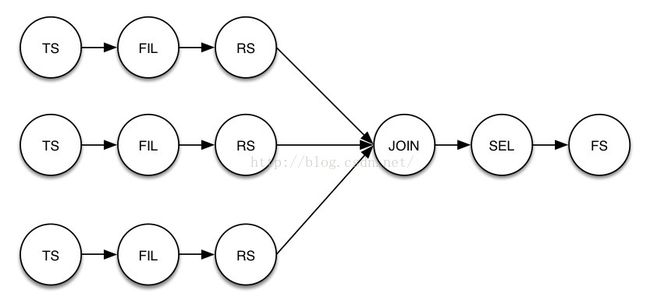
图3-7 join语句算子DAG
DAG图中RS算子左边有三个分支,分别对应三张表a,b,c的运算。其中FIL算子用于过滤掉id为null的记录;RS算子按照id进行数据分发(partition)和排序(sort),并对数据进行打标(tag)。数据打标指对每条记录添加一个tag标示,用于区分数据来自那张表。tag标是一个整数,例如表a的记录会加上tag标记0,表b的记录会加上tag标1,表c则是2,依次递增。JOIN算子对RS分组排序后的数据进行Join运算。数据的具体处理流程如下
图3-8所示:

图3-8 join数据处理流程
表a,b,c的数据分别经过TS,FIL算子进行扫描、过滤处理,然后通
过RS算子进行数据分发和排序。RS算子按照join on表达式字段进行数据分发和排序并给每条记录打标(tag)。这里按照id进行数据分发和排序,表a,b,c的记录分别添加0,1,2做为tag。在reduce端,排序后的数据按照id进行分组,每组数据中包含多张表的数据,不同表的数据根据tag来区分。JOIN算子对分组中多张表的数据做笛卡尔乘积,得到每个id的join结果。