接着上篇 CS231n : Assignment 1 继续:
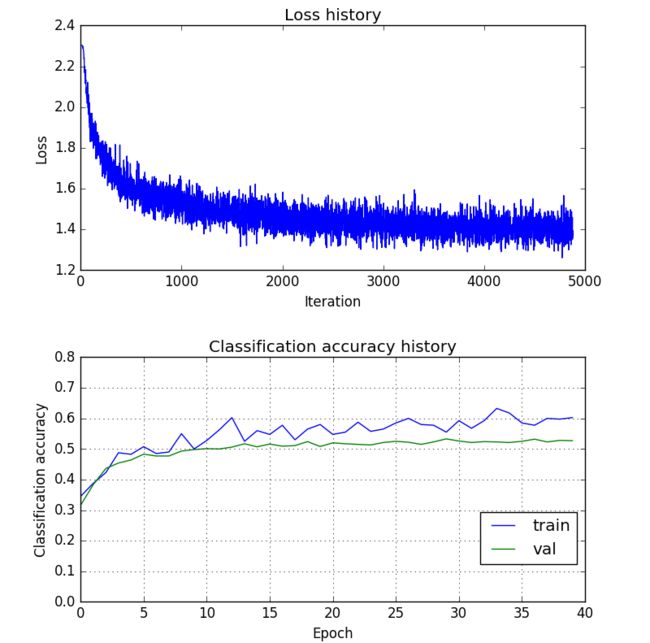
这里,我给出我的最优模型代码和第一层权重W1的可视化结果,识别率还有上升空间,欢迎小伙伴贴出更高的识别率。
nn_twolayer_best.py 代码如下:
__coauthor__ = 'Deeplayer'
# 6.16.2016
import numpy as np
import matplotlib.pyplot as plt
from neural_net import TwoLayerNet
from data_utils import load_CIFAR10
from vis_utils import visualize_grid
# Load the data
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000):
"""
Load the CIFAR-10 dataset from disk and perform preprocessing to prepare
it for the two-layer neural net classifier. These are the same steps as
we used for the SVM, but condensed to a single function.
"""
# Load the raw CIFAR-10 data
cifar10_dir = 'E:/PycharmProjects/ML/CS231n/cifar-10-batches-py' # make a change
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# Subsample the data
mask = range(num_training, num_training + num_validation)
X_val = X_train[mask] # (1000,32,32,3)
y_val = y_train[mask] # (1000L,)
mask = range(num_training)
X_train = X_train[mask] # (49000,32,32,3)
y_train = y_train[mask] # (49000L,)
mask = range(num_test)
X_test = X_test[mask] # (1000,32,32,3)
y_test = y_test[mask] # (1000L,)
# preprocessing: subtract the mean image
mean_image = np.mean(X_train, axis=0)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
# Reshape data to rows
X_train = X_train.reshape(num_training, -1) # (49000,3072)
X_val = X_val.reshape(num_validation, -1) # (1000,3072)
X_test = X_test.reshape(num_test, -1) # (1000,3072)
return X_train, y_train, X_val, y_val, X_test, y_test
# Invoke the above function to get our data.
X_train, y_train, X_val, y_val, X_test, y_test = get_CIFAR10_data()
print 'Train data shape: ', X_train.shape
print 'Train labels shape: ', y_train.shape
print 'Validation data shape: ', X_val.shape
print 'Validation labels shape: ', y_val.shape
print 'Test data shape: ', X_test.shape
print 'Test labels shape: ', y_test.shape
# Look for the best net
best_net = None # store the best model into this
input_size = 32 * 32 * 3
hidden_size = 100
num_classes = 10
net = TwoLayerNet(input_size, hidden_size, num_classes)
"""
max_count = 100
for count in xrange(1, max_count + 1):
reg = 10 ** np.random.uniform(-4, 1)
lr = 10 ** np.random.uniform(-5, -3)
stats = net.train(X_train, y_train, X_val, y_val, num_epochs=5,
batch_size=200, mu=0.5, mu_increase=1.0, learning_rate=lr,
learning_rate_decay=0.95, reg=reg, verbose=True)
print 'val_acc: %f, lr: %s, reg: %s, (%d / %d)' %
(stats['val_acc_history'][-1], format(lr, 'e'), format(reg, 'e'), count, max_count)
# according to the above experiment, reg ~= 0.9, lr ~= 5e-4
"""
stats = net.train(X_train, y_train, X_val, y_val,
num_epochs=40, batch_size=400, mu=0.5,
mu_increase=1.0, learning_rate=5e-4,
learning_rate_decay=0.95, reg=0.9, verbose=True)
# Predict on the validation set
val_acc = (net.predict(X_val) == y_val).mean()
print 'Validation accuracy: ', val_acc # about 52.7%
# Plot the loss function and train / validation accuracies
plt.subplot(2, 1, 1)
plt.plot(stats['loss_history'])
plt.title('Loss history')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.subplot(2, 1, 2)
plt.plot(stats['train_acc_history'], label='train')
plt.plot(stats['val_acc_history'], label='val')
plt.ylim([0, 0.8])
plt.title('Classification accuracy history')
plt.xlabel('Epoch')
plt.ylabel('Classification accuracy')
plt.legend(bbox_to_anchor=(1.0, 0.4))
plt.grid(True)
plt.show()
best_net = net
# Run on the test set
test_acc = (best_net.predict(X_test) == y_test).mean()
print 'Test accuracy: ', test_acc # about 54.6%
# Visualize the weights of the best network
def show_net_weights(net):
W1 = net.params['W1']
W1 = W1.reshape(32, 32, 3, -1).transpose(3, 0, 1, 2)
plt.imshow(visualize_grid(W1, padding=3).astype('uint8'))
plt.gca().axis('off')
plt.show()
show_net_weights(best_net)

最后再说两句,神经网络和线性分类器(SVM and Softmax)有什么区别与联系?神经网络可以看成是非线性分类器(不仅仅如此),其实对于分类问题,还有一个更重要的步骤我们没讲,就是特征提取 (feature extraction),好的特征提取,可以使我们的分类水平大大提高。前面的线性分类器做的只是在原始像素(预处理后的)上进行分类,所以效果并不好。而神经网络(全连接)隐藏层的作用可以看成是进行(全局)特征提取,实际上基本没有提取到什么特征(更像是一个模板)。但好在这些特征不需要人工选择,完全是神经网络自己学习到的!所以,对于分类问题的神经网络,可以分成两个部分:特征提取+线性分类器。严格来讲,卷积神经网络才真正做到了这一点。
遗憾的是,随着神经网络层数的加深,损失函数越来越容易陷入局部最优解,并且这个“陷阱”越来越偏离真正的全局最优(因为我们的权重都是随机初始化的)。所以利用有限数据训练的(全连接)深度神经网络(DNN),性能还不如层数较浅的网络;此外,随着层数的增加,“梯度消失”现象也会越发严重。不过这两个问题都已经得到了很大缓解:
1、2006年,Hinton发表的两篇论文Reducing the Dimensionality of Data with Neural Networks、A Fast Learning Algorithm for Deep Belief Nets利用预训练方法缓解了局部最优解问题,具体思想就是:利用无监督的逐层贪婪学习算法,一层一层地预训练神经网络的权重(每一层通过一个稀疏自编码器完成训练),最后再用有标签的数据通过反向传播微调所有权重。
2、我们之前讲过的ReLU、Maxout等激活函数,可以很好地克服“梯度消失”现象,而后来的Batch Normalization更是凶猛。
2012年ImageNet比赛中,CNN以压倒性的优势取得胜利,深度学习的巨大浪潮才正式开始。而自那之后,预训练方法已经被完全抛弃了,大概是因为数据量足够大了。
卷积神经网络(CNNs)的强大是因为它有着非常强大的(局部)特征提取能力,而且这些特征是逐层抽象化的,即下一层的特征是上一层的组合。层数越深,特征组合就越多、越深刻。
---> CS231n : Assignment 2
---> CS231n : Assignment 3