zookeeper是如何进行维护offset
zookeeper是如何进行维护offset
引言:
SparkStreaming消费kafka有两种方式,分别是Receiver方式和Direct方式,Receiver可以自己去维护偏移量offset,Direct方式是Executer直接对接kafka进行消费数据,即用即读即丢,sparkStream会产生和topic中partition相同多的RDD,提高了效率,节省了资源,需要手动去维护offset,可以用zookeeper、mysql、checkpoint、Hbase等等,在公司中用的比较多的还是zookeeper,就粗略的探究了一下zookeeper如何维护offset进行,没有太底层的东西,只为了理解过程。
zookeeper节点结构:
先了解一下zookeeper的节点结构吧。
启动zookeeper后,启动zookeeper的客户端,查看里面的节点
执行zkCli.sh -server localhost:2181打开客户端
执行ls /查看所有的节点
![]()
可以看到有我们比较熟悉的brokers(kafka的集群节点)、yarn-leader-election、hadoop—ha,consumers,hbase。
既然要维护kafka的offset,那么就一定去查看consumers(kafka的消费者)

可以看到一堆消费者,这些消费者,有的是自己命名的,有的是自定义的(不去定义groupid,自动分配),
再打开我们需要的消费者给g001
![]()
只有一个目录offsets,这是zookeeper自己给创建的,而其他的消费者目录里有可能还有ids, owners
ids记录该消费组下正在运行的消费者列表
owners记录该消费组消费的主题列表
offsets记录该消费组下每个消费者所消费主题的各个分区的偏移量
继续打开offset来看一下各个分区行偏移量
![]()
里面有两个topic目录,没错,就是kafka中的topic,topic下就是partition了
![]()
那分区中储存的是什么呢?
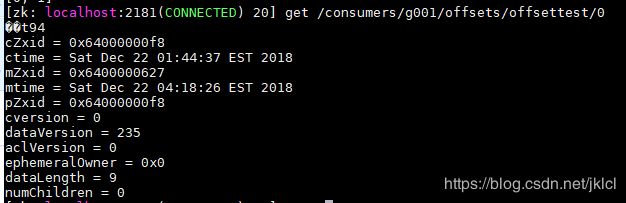
最先的是分区0储存的行偏移量,为94
到目前为止,可以知道了是那个消费者,消费的那个topic,有几个分区,每个分区消费到了第几条
所以zookeeper维护行偏移量,就是在更新这个值96.
节点信息:
cZxid:节点创建时的zxid
ctime:节点创建时间
mZxid:节点最近一次更新时的zxid
mtime:节点最近一次更新的时间
cversion:子节点数据更新次数
dataVersion:本节点数据更新次数
aclVersion:节点ACL(授权信息)的更新次数
ephemeralOwner:如果该节点为临时节点,ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是临时节点,ephemeralOwner值为0
dataLength:节点数据长度,本例中为hello world的长度
numChildren:子节点个数
如何进行维护
kafka的准备工作,主要是消费者名,消费哪个topic,kafka节点地址,kafka参数配置
//指定组名
val group = "g001"
//创建SparkConf
val conf = new SparkConf().setAppName(this.getClass.getName).setMaster("local")
//创建SparkStreaming,并设置间隔时间
val ssc = new StreamingContext(conf, Duration(5000))
//使用updateStateByKey会用到
ssc.checkpoint("f:/bigdata/cmcc/out")
//指定消费的 topic 名字
val topic = "offsettest"
//指定kafka的broker地址(sparkStream的Task直连到kafka的分区上,用更加底层的API消费,效率更高)
val brokerList = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
//创建 stream 时使用的 topic 名字集合,SparkStreaming可同时消费多个topic
val topics: Set[String] = Set(topic)
//准备kafka的参数
val kafkaParams = Map(
"metadata.broker.list" -> brokerList,
"group.id" -> group,
//从头开始读取数据
"auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString
)
zookeeper的准备工作和创建目录
zookeeper节点地址,zookeeper地址对象,zookeeper客户端对象,储存DStream的对象
//指定zk的地址,后期更新消费的偏移量时使用(以后可以使用Redis、MySQL来记录偏移量)
val zkQuorum = "hadoop01:2181,hadoop02:2181,hadoop03:2181"
//创建一个 ZKGroupTopicDirs 对象,其实是指定往zk中写入数据的目录,用于保存偏移量
//对应着zookeeper的节点结构,创建目录,其本身就是一个地址
val topicDirs = new ZKGroupTopicDirs(group, topic)
//是zookeeper的客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//储存从kafka上获取的DStream
var kafkaStream: InputDStream[(String, String)] = null
//如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
var fromOffsets: Map[TopicAndPartition, Long] = Map()
查找目录中的分区数
//获取 zookeeper 中的路径 "/g001/offsets/offsettest/"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//查询该路径下是否字节点
//其实就是topic下的分区个数,上文提到的有0和1两个分区,int类型
val children = zkClient.countChildren(zkTopicPath)
根据分区的个数来判断是否是从头读,还是根据各分区的偏移量来获取数据
if (children > 0) {//有分区
for (i <- 0 until children) {
//获取目录下的partition,就是之前看的partition0的值--94
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
//将topic和partition对应到TopicAndPartition中,即(offsettest/0)....
val tp = TopicAndPartition(topic, i)
//以key-value的形式放入map,即(offsettest/0):94
fromOffsets += (tp -> partitionOffset.toLong)
}
//这个会将 kafka 的消息进行 transform,最终 kafak 的数据都会变成 (kafka的key, message) 这样的 tuple,其实就是规定一下格式
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message())
//通过KafkaUtils创建直连的DStream(fromOffsets参数的作用是:按照前面计算好了的偏移量继续消费数据)
//[String, String, StringDecoder, StringDecoder, (String, String)]
// key value key的解码方式 value的解码方式
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
} else {
//如果未保存,根据 kafkaParam 的配置使用最新(largest)或者最旧的(smallest) offset
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
维护更新offset
//偏移量的范围
var offsetRanges = Array[OffsetRange]()
//直连方式只有在KafkaDStream的RDD中才能获取偏移量,那么就不能到调用DStream的Transformation
//所以只能子在kafkaStream调用foreachRDD,获取RDD的偏移量,然后就是对RDD进行操作了
//依次迭代KafkaDStream中的KafkaRDD
kafkaStream.foreachRDD { kafkaRDD =>
//定义zk客户端对象和zk目录对象,因为在算子中,在work端执行,所以要重新定义,不让会出现序列化的问题
val zkClient = new ZkClient(zkQuorum)
val topicDirs = new ZKGroupTopicDirs(group, topic)
//只有KafkaRDD可以强转成HasOffsetRanges,并获取到偏移量,多个分区-->list
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
for (o <- offsetRanges) {
//offset的存在目录
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 更新到 zookeeper
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
}
上面代码中o有几个属性
o.untilOffset//消费到了第几行,行偏移量
o.fromOffset//之前的行偏移量
o.partition//所在的分区
o.topic//所在的topic