ES脑裂问题分析及优化
脑裂问题,就是同一个集群中的不同节点,对于集群的状态,有了不一样的理解。
由于并发访问量的提高,导致了我们两个节点的集群(分片数默认为5,副本为1,没有固定的master,都是集群中的节点又做data又做master)状态变成了red,出现了大量的坏片,并且坏掉的都是主分片及其副本。分析发现,是ES集群出现了脑裂问题(俗称精神分裂),即集群中不同的节点对于master的选择出现了分歧,出现了多个master竞争,导致主分片和副本的识别也发生了分歧,对一些分歧中的分片标识为了坏片。
“脑裂”问题可能的成因
1.网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片
2.节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
3.内存回收:data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
脑裂问题解决方案:
1.减少误判:discovery.zen.ping_timeout节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如6s,discovery.zen.ping_timeout:6),可适当减少误判。
2.选举触发 discovery.zen.minimum_master_nodes:1
该参数是用于控制选举行为发生的最小集群主节点数量。
当备选主节点的个数大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n/2)+1,n为主节点个数(即有资格成为主节点的节点个数)
增大该参数,当该值为2时,我们可以设置master的数量为3,这样,挂掉一台,其他两台都认为主节点挂掉了,才进行主节点选举。
3.角色分离:即master节点与data节点分离,限制角色
主节点配置为:
node.master: true node.data: false
从节点配置为:
node.master: false node.data: true
实际解决办法
最终考虑到资源有限,解决方案如下:
增加一台物理机,这样,一共有了三台物理机。在这三台物理机上,搭建了6个ES的节点,三个data节点,三个master节点(每台物理机分别起了一个data和一个master),3个master节点,目的是达到(n/2)+1等于2的要求,这样挂掉一台master后(不考虑data),n等于2,满足参数,其他两个master节点都认为master挂掉之后开始重新选举,
master节点上
node.master = true
node.data = false
discovery.zen.minimum_master_nodes = 2data节点上
node.master = false
node.data = true方案分析
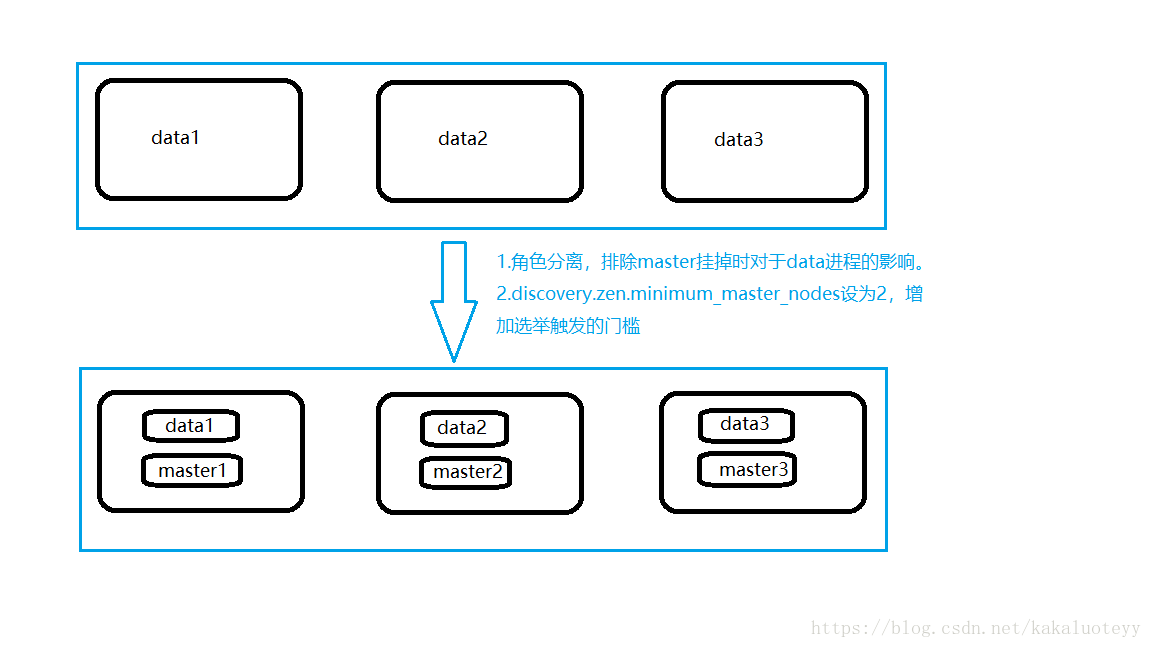
1.角色分离后,当集群中某一台节点的master进程意外挂掉了,或者因负载过高停止响应,终止掉的master进程很大程度上不会影响到同一台机器上的data进程,即减小了数据丢失的可能性。
2.discovery.zen.minimum_master_nodes设置成了2(3/2+1)当集群中两台机器都挂了或者并没有挂掉而是处于高负载的假死状态时,仅剩一台备选master节点,小于2无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
而图一,两台节点假死,仅剩一台节点,选举自己为master,当真正的master苏醒后,出现了多个master,并且造成查询不同机器,查到了结果不同的情况。
脑裂问题相关文章:https://blog.trifork.com/2013/10/24/how-to-avoid-the-split-brain-problem-in-elasticsearch/