基于ElasticSearch的问答系统(KBQA)
在上一篇博客中,我们已经大概了解了KBQA的概念,也大概知道KBQA的流程,但是针对上篇博客提出的问题,修改数据,如何更简单的做到而对问答系统的影响效果最小呢?这里我就换成另一种方式,直接使用ElasticSearch来替换TDB存放数据。下图是与上文实现一样效果的demo:

1. ElasticSearch
Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎Apache Lucene™ 基础上的搜索引擎。但是Elasticsearch并不仅仅是Lucene那么简单,它不仅包括了全文搜索功能,还可以进行下面的工作:
1.分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
2.实时分析的分布式搜索引擎。
3.可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
ElasticSearch安装使用比较简单,可以根据官方文档Elasticsearch Reference自己安装与学习。
这里重点需要提出的是,ElasticSearch 中处理分词的部分被称作分词器,它决定了分词的规则,默认是Standard,即将中文分为单个的字,如“我爱北京天安门“就会被分为“我/爱/北/京/天/安/门”,明显不符合我们的要求“我/爱/北京/天安门”,所以这个时候就需要我们自己制定分词器,实现分词规则,最常见的为ik分词器。
根据不同的功能,可能大家需要不同的ElasticSearch插件,大家可以在ES官网下载,但必须注意的是,插件需要与ElasticSearch版本对应,否则无法使用。如果有哪些看官不知道如何使用ES,稍后我会在后面的继续贴上博客。
2. 实例分析
- 数据准备
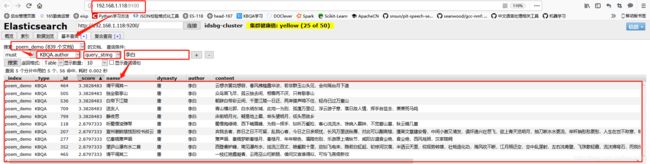
数据我们依然使用上一篇博客的数据,这里需要注意的是,将数据插入到ElasticSearch的时候,必须指定分词器和分词方式,否则功能无法实现。如何使用ElasticSearch,后续我会慢慢写出来。这里我主要分为四个字段插入:name(诗词名)、author(作者)、dynasty(朝代)、content(内容),分词分别为:ik_smart、ik_max_word、ik_smart、ik_smart。数据插入完成后,可以使用head插件查看,如下图所示:

- 数据查询
数据插入完成后,我们就可以直接查询数据库了,ElasticSearch使用的是相似度查询,所以很大程度上减轻了我们的搜索任务,我们可以通过head插件直接在浏览器上进行搜索,十分方便,如下图所示:
from elasticsearch import Elasticsearch
values = []
es = Elasticsearch(hosts=['192.168.1.118'], timeout=50000) # 数据库IP
query = {'query': {'bool': {'must': [{'query_string': {'default_field': 'author', 'query': '李白'}}]}}, 'size': 100} # 查询语句
response = es.search(index="poem_demo", body=query)
for hit in response['hits']['hits']: # 结果解析
value = hit['_source']['name']
values.append(value)
print(values)
其中host为ElasticSearch为数据库存放的机器IP,default_field为查询领域,query为问句。最终查询出来的结果为:
['清平调其一', '独坐敬亭山', '白帝下江陵', '送友人', '静夜思', '听蜀僧浚弹琴', '宣州谢眺楼饯别校书叔云', '忆秦娥箫声咽', '望庐山瀑布水二首', '清平调其二', '清平调名花倾国两相欢', '菩萨蛮平林漠漠烟如织', '蜀道难', '赠孟浩然', '长干行', '古朗月行', '子夜吴歌冬歌', '庐山谣寄卢侍御虚舟', '早发白帝城', '望天门山', '望庐山瀑布', '梦游天姥吟留别', '梦游天姥山别东鲁诸公', '登金陵凤凰台', '行路难', '长干行其一', '三五七言', '下终南山过斛斯山人宿置酒', '关山月', '夜泊牛渚怀古', '子夜吴歌', '怨情', '春夜洛城闻笛', '月下独酌', '渡荆门送别', '秋风词', '行路难其三', '长相思其一', '长相思其二', '塞下曲六首其一', '子夜吴歌夏歌', '子夜吴歌春歌', '子夜吴歌秋歌', '将进酒', '峨眉山月歌', '春夜洛阳城闻笛', '春思', '月下独酌四首其一', '清平调', '玉阶怨', '行路难其一', '行路难其二', '赠汪伦', '金陵酒肆留别', '闻王昌龄左迁龙标遥有此寄', '黄鹤楼送孟浩然之广陵']
查询《将进酒》内容:
from elasticsearch import Elasticsearch
values = []
es = Elasticsearch(hosts=['192.168.1.118'], timeout=50000) # 数据库IP
query = {'query': {'bool': {'must': [{'query_string': {'default_field': 'name', 'query': '将进酒'}}]}}, 'size': 5} # 查询语句
response = es.search(index="poem_demo", body=query)
for hit in response['hits']['hits']: # 结果解析
value = hit['_source']['content']
values.append(value)
print(values)
最终查询出来的结果为:
['君不见,黄河之水天上来,奔流到海不复回,君不见,高堂明镜悲白发,朝如青丝暮成雪,人生得意须尽欢,莫使金樽空对月,天生我材必有用,千金散尽还复来,烹羊宰牛且为乐,会须一饮三百杯,岑夫子,丹丘生,将进酒,杯莫停,与君歌一曲,请君为我倾耳听,钟鼓馔玉不足贵,但愿长醉不复醒,古来圣贤皆寂寞,惟有饮者留其名,陈王昔时宴平乐,斗酒十千恣欢谑,主人何为言少钱,径须沽取对君酌,五花马,千金裘,呼儿将出换美酒,与尔同销万古愁']
- 问答实践
这里我们demo的问答逻辑还是跟基于知识图谱的问答系统(KBQA)想同,这里就不阐述了。具体实现可以去基于ElasticSearch的问答系统查看源码。
3. 总结
使用ElasticSearch,进行数据更新,而不需要重新部署整个流程,只有在需要更新分词的时候,才需要重启ElasticSearch,但是时间非常短暂。而且ElasticSearch可以在多台机器上部署集群,这样就更方便项目的使用。但是同样也有缺点,如果一个知识有N个关系属性,就需要创建N个字段,这在使用的时候会有很多不便,同时如果几个实体相互之间有关系,推理从一个实体推理另一个实体就比较麻烦。所以需要使用哪种就需要仁者见仁智者见智了。