深度学习中的损失函数总结以及Center Loss函数笔记
 NVIDIA 深度学习学院 带你快速进入火热的DL领域
NVIDIA 深度学习学院 带你快速进入火热的DL领域
阅读全文 >
正文共5481个字,19张图,预计阅读时间14分钟。
图片分类里的center loss
损失函数度量的是预测值与真实值之间的差异.损失函数通常写做L(y_,y).y_代表了预测值,y代表了真实值.
目标函数可以看做是优化目标,优化模型的最后目标就是使得这个目标函数最大或者最小.
代价函数类似于目标函数.
区别:目标函数(代价函数)可以包含一些约束条件如正则化项.
一般不做严格区分.下面所言损失函数均不包含正则项.
以keras文档列出的几个为例
keras-loss
1、mse(mean_squared_error):均方误差损失.
K.mean(K.square(y_pred-y_true),axis=-1)
2、mae(mean_absolute_error):平均绝对值误差损失.
K.mean(K.abs(y_pred-y_true),axis=-1)
3、mape(mean_absolute_percentage_error):平均绝对百分误差.
K.abs((y_true - y_pred) / K.clip(K.abs(y_true),K.epsilon(),None))#clip(x,min,max)防止除0错误
4、msle(mean_squared_logarithmic_error):均方对数损失(mse的改进).
#mslefirst_log = K.log(K.clip(y_pred, K.epsilon(), None) + 1.)
second_log = K.log(K.clip(y_true, K.epsilon(), None) + 1.)
loss= K.mean(K.square(first_log - second_log), axis=-1)
#msefirst_log = K.clip(y_pred, K.epsilon(), None) + 1.
second_log = K.clip(y_true, K.epsilon(), None) + 1.
loss= K.mean(K.square(first_log - second_log), axis=-1)
msle相比与mse的改进:如果想要预测的值范围很大,mse会受到一些大的值的引导,即使小的值预测准也不行.假设如:
y_true:[1,2,3,100]
y_1:[1,2,3,110]
y_2:[2,3,4,100]
mse计算结果(y_1:100,y_2:3)会认为y_2优于y_1.
msle计算结果(有_1:0.047,0.27)通过预先将所有值取log缓解了这一情况,会认为y_1优于y_2.这比较合理.
5、logcosh烫烫烫.回归
def cosh(x): return (K.exp(x) + K.exp(-x)) / 2K.mean(K.log(cosh(y_pred - y_true)), axis=-1)
这个函数没见人用过,按照公式作图如下:

大致可以看出来如果y_pred与y_true差异越小则值越小.
6、kullback_leiber_divergence:KL散度.
两个概率分布P和Q差别的非对称性的度量. 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
y_true = K.clip(y_true, K.epsilon(), 1) y_pred = K.clip(y_pred, K.epsilon(), 1) K.sum(y_true * K.log(y_true / y_pred), axis=-1)
一种解释:KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。(熵,交叉熵,)
举例:假设现在有两个分布p和q,p为真实,q为模型预测的
熵的本质是信息量度量:
![]()
按照真实分布p来衡量识别一个样本所需要的平均编码长度:
![]()
按照错误分布q来表示来自真实分布p的平均编码长度(交叉熵):
![]()
举例:
4个字母,真实分布p=[0.5,0.5,0,0],q=[0.25,0.25,0.25,0.25],计算得到H(p)为1.H(p,q)为2.由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为KL散度.
![]()
KL散度wiki
KL散度zhihu
7、categorical_crossentropy:多类的对数损失.
一种解释:
softmax公式:

logistic regression的目标函数是根据最大似然来做的.也就是假设x属于类y,预测出概率为oy,那么需要最大化oy.
![]()
softmax_loss如下:
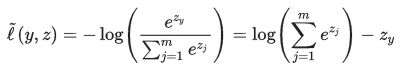
下面是二类分类交叉熵公式:
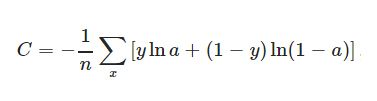
数值稳定性问题
center Loss损失函数
开始正题.
以mnist数据集为例.(手写数字,28*28图像,10分类问题)
categorical crossentropy(softmax loss)的问题
通常会使用softmax loss多分类损失函数.
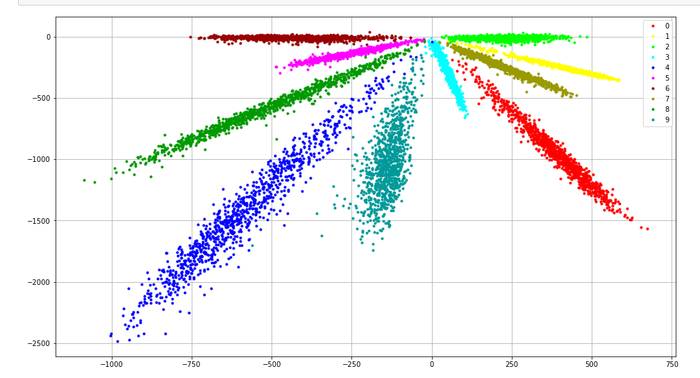
使用CNN网络(mnist分类容易达到较高的准确度,为了实验效果,网络设计的故意差了点,如没有使用BN,relu,dropout,L2等trick),选择在倒数第二层全连接层输出节点为2个,称为是特征,而后将这2个节点接到最后的的10节点全连接层.
正常的训练过程,到达较高准确度后将每个数据的倒数第二层的特征打印出来.
如下图:
缺点:
1、从聚类角度看,提取的特征并不好.很多情况下类内间距甚至要大于类间间距.我们期望特征不仅可分,而且要求差异大,特征学习需要保证提取的特征有识别度。
2、占据的面积有点大.通常情况下,我们希望每一类只占很小一部分.因为手写字符很多啊,这些数字就占了这么大地方,如果新来了英文字母呢...也就是我们期望模型能识别出在训练数据的标签中没有的分类。特征学习需要保证提取的特征具有普适性.
3、softmax会使得模型过度自信,分类结果基本非1即0,上图里有些点在边界但是softmax认为已经可以了,根本没必要再修正.同时softmax这种特性使得基本上没有办法去设置诸如可信度等度量.(场景?)
原因?举例:
最后一层全连接层输出V=[x1,x2,x3],真实标签是[1,0,0].那么假设V=[x1,x2,x3]是[3.1,3,3],那么softmax的公式使得其只需要V的模长增加倍数即可以降低loss损失.这太容易(只需要增大参数即可)使得网络往往就是这样做的.而不是我们通常想要的那样去努力降低x2,x3的相对于x1的值如[3.1,1,1]这样.这也是所以L2正则会缓解过拟合的一个原因.
解决办法:很多,如故意让softmax也去模拟下均匀分布输出而不仅仅是one_hot.这里只涉及其中一种也就是centerloss.
那么换一个损失函数吧.均方误差损失?如下图:
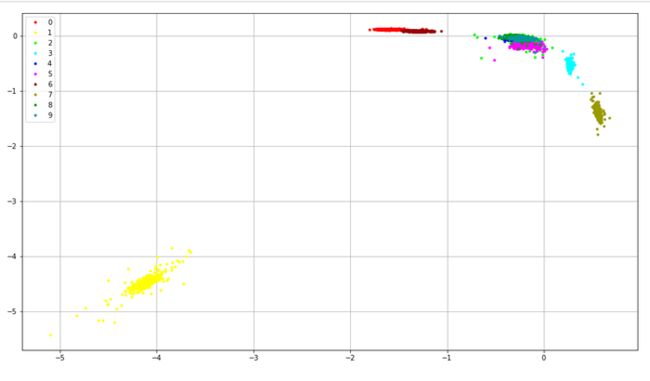
不但准确度下降到30%,而且互相直接还有了覆盖交集.
有趣的地方:
1、1和其他数字很明显的分开了.
2、2,4,5,8,9这几个炸了根本分不开.
在上述的几个损失函数上,softmax工作的是最好的了.
Center Loss
针对softmax表现出的问题针对性解决.--->类内间距太大了.
3、对每一个类都维护一个类中心c,而后在特征层如果该样本里类中心的特征太远就要惩罚.也就是所谓的centerloss.

类中心c:每一个样本的特征需要通过一个好的网络到达特征层获得,这样计算完后所有样本的特征的平均值为类中心c,而好的网络需要是在有类中心加入的情况下才能得到...
1、没法直接获得c,所以将其放到网络里自己生成,在每一个batch里更新center.即随机初始化center,而后每一个batch里计算当前数据与center的距离,而后将这个梯度形式的距离加到center上.类似于参数修正.同样的类似于梯度下降法,这里再增加一个scale度量a,使得center不会抖动.
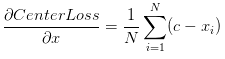
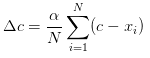
2、实验表明只使用centerloss效果很一般,所以一般是将centerloss与softmax结合起来,引入参数lambda.

总体结构如下:
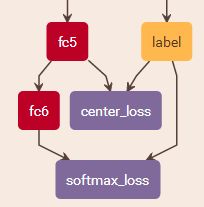
3、算法过程

4、实验结果
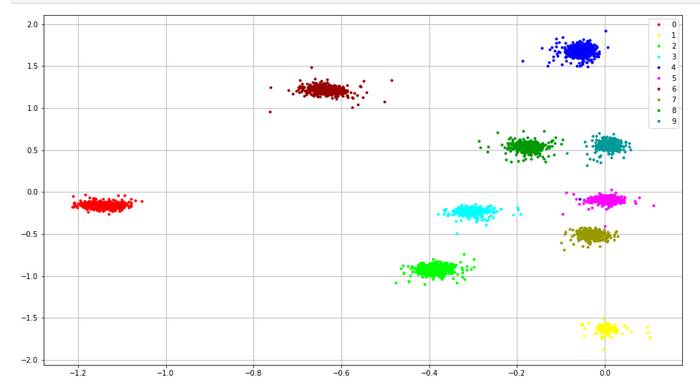
准确度提高约0.6%.
总结
1、一种新的loss函数,看起来效果不错,而且也更加符合认知,生成的模型鲁棒性可能更好.
2、本质是度量学习,经常应用在分类领域,原理简单,计算复杂度不大,经常能提升效果.
3、有点使用空间换取时间的意思.
4、属于一个trick.不一定适合所有场景.一般来说,如果同一类样本很类似如mnist手写数字,人脸数据,那么centerloss往往能够带来效果提升.而如果本身同一类样本就差异很大,如cifar100,那么则不一定.也可以理解成一个人的一堆脸取平均值仍然是他的脸,而一堆不同的狗取平均值则可能难以认出是什么.
5、参数设置:a一般取0.5,lambda则0.1-0.0001之间不等,需要实验调参.
6、参考论文 A Discriminative Feature Learning Approach for Deep Face Recognition
最后附上centerloss的使用代码.
def get_center_loss(features, labels, alpha, num_classes): """获取center loss及center的更新op features: Tensor,表征样本特征,一般使用某个fc层的输出,shape应该为[batch_size, feature_length]. labels: Tensor,表征样本label,非one-hot编码,shape应为[batch_size]. alpha: 0-1之间的数字,控制样本类别中心的学习率,细节参考原文. num_classes: 整数,表明总共有多少个类别,网络分类输出有多少个神经元这里就取多少. Return: loss: Tensor,可与softmax loss相加作为总的loss进行优化. centers_update_op: op,用于更新样本中心的op,在训练时需要同时运行该op,否则样本中心不会更新 """ # 获取特征的维数,例如256维 len_features = features.get_shape()[1] # 建立一个Variable,shape为[num_classes, len_features],用于存储整个网络的样本中心, # 设置trainable=False是因为样本中心不是由梯度进行更新的 centers = tf.get_variable('centers', [num_classes, len_features], dtype=tf.float32, initializer=tf.constant_initializer(0), trainable=False) # 将label展开为一维的,输入如果已经是一维的,则该动作其实无必要 labels = tf.reshape(labels, [-1]) # 根据样本label,获取mini-batch中每一个样本对应的中心值 centers_batch = tf.gather(centers, labels) # 计算loss loss = tf.div(tf.nn.l2_loss(features - centers_batch),int(len_features)) # 当前mini-batch的特征值与它们对应的中心值之间的差 diff = centers_batch - features # 获取mini-batch中同一类别样本出现的次数,了解原理请参考原文公式(4) unique_label, unique_idx, unique_count = tf.unique_with_counts(labels) appear_times = tf.gather(unique_count, unique_idx) appear_times = tf.reshape(appear_times, [-1, 1]) diff = diff / tf.cast((1 + appear_times), tf.float32) diff = alpha * diff centers_update_op = tf.scatter_sub(centers, labels, diff) return loss,centers_update_op# 损失函数定义with tf.variable_scope('loss_scope'): self.centerloss,self.centers_update_op = get_center_loss(self.features,self.y,0.5,self.CLASSNUM) #self.loss = tf.losses.softmax_cross_entropy(onehot_labels=util.makeonehot(self.y, self.CLASSNUM), logits=self.score) self.loss = tf.losses.sparse_softmax_cross_entropy(labels=self.y, logits=self.score)+0.05*self.centerloss # tf.summary.scalar('loss',self.loss) # 优化器 with tf.control_dependencies([self.centers_update_op]): self.train_op = tf.train.MomentumOptimizer(0.001, 0.9).minimize(self.loss)
原文链接:http://www.jianshu.com/p/fb6146fc7552
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
![]()