笔记-hadoop本地模式、伪分布式、分布式的搭建
目录
hadoop运行环境搭建
VM虚拟机安装centos,Linux系统配置
安装Java和hadoop
JAVA安装
Hadoop安装
hadoop本地模式
本地模式grep案例
本地模式Wordcount案例
hadoop伪分布式搭建
启动HDFS并运行MapReduce程序
伪分布式下Wordcount案例
启动YARN并运行MapReduce程序
yarn下运行Wordcount
配置历史服务器
配置日志的聚集
hadoop完全分布式
集群部署规划
SSH无密登录配置
xsync集群分发脚本
修改hadoop配置文件
核心配置文件
HDFS配置文件
YARN配置文件
MapReduce配置文件
通过xsync向集群分发配置好的Hadoop配置文件
启动集群
配置slaves
启动HDFS
启动YARN
hadoop运行环境搭建
VM虚拟机安装centos,Linux系统配置
- 网卡设置
vim /etc/udev/rules.d/70-persistent-net.rules删除第一个网卡,将第二条eth1改为eth0,复制ATTR{address}物理地址
修改前
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:8b:4e:8b", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:17:d4:e6", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1"修改后如下
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:17:d4:e6", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
复制ATTR{address}中的物理地址"00:0c:29:17:d4:e6",后面会用 -
设置静态IP,修改物理地址HWADDR,ONBOOT改成yes,BOOTPROTO改成static,添加ip地址,网关和dns
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改后内容
DEVICE=eth0
HWADDR=00:0c:29:17:d4:e6
TYPE=Ethernet
UUID=48f8d581-9014-4d85-b367-05f08b46875f
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=staticIPADDR=192.168.12.101
GATEWAY=192.168.12.2
DNS1=192.168.12.2
HWADDR中的物理地址是/etc/udev/rules.d/70-persistent-net.rules中ATTR{address}的数据 -
修改主机名,将主机名修改为hadoop101
vim /etc/sysconfig/network修改为:
NETWORKING=yes
HOSTNAME=hadoop101 -
修改/etc/hosts文件
vim /etc/hosts末尾添加
192.168.12.101 hadoop101
192.168.12.102 hadoop102
192.168.12.103 hadoop103本地Windows系统hosts也添加相同信息
-
关闭防火墙
service iptables stop设置开机时关闭防火墙
chkconfig iptables off -
添加用户并设置密码
useradd liun passwd liun -
给新创建用户root权限
vim /etc/sudoers找到“root ALL=(ALL) ALL”,在下一行添加“liun ALL=(ALL) ALL”。
reboot命令重启系统
/opt创建两个文件夹module和software,software存放压缩包,module存放解压后文件
sudo mkdir /opt/module /opt/software设置文件夹所属用户和组
sudo chown -R liun:liun /opt/module/ /opt/software/安装Java和hadoop
通过工具上传jdk和hadoop到software目录
JAVA安装
- jdk解压到module
tar -zxvf /opt/software/jdk-8u144-linux-x64.tar.gz -C /opt/module/ - 配置java环境变量
sudo vim /etc/profile末尾添加:
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin -
使修改立即生效
source /etc/profilejava -version 查看是否配置成功
Hadoop安装
- 将上传的hadoop包解压到module目录下
tar -zxvf /opt/software/hadoop-2.7.2.tar.gz -C /opt/module/ -
配置hadoop环境变量
sudo vim /etc/profile末尾添加:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin -
使修改立即生效
source /etc/profile
hadoop本地模式
官方网站:https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
本地模式grep案例
hadoop目录下创建input目录
cd /opt/module/hadoop-2.7.2
mkdir input
cp etc/hadoop/*.xml input/
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output 'dfs[a-z.]+'查看输出数据
cat output/*output输出数据
1 dfsadmin
本地模式Wordcount案例
创建wcinput目录
cd /opt/module/hadoop-2.7.2
mkdir wcinput创建测试文本
cd wcinput
touch wc.input
vim wc.input输入网上随意找的英文文章
Life is full of confusing and disordering Particular time,a particular location,Do the arranged thing of ten million time in the brain,Step by step ,the life is hard to avoid delicacy and stiffness No enthusiasm forever,No unexpected happening of surprising and pleasing So,only silently ask myself in mind Next happiness,when will come?
返回hadoop-2.7.2目录,测试Wordcount
cd ..
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput查看输出数据
cat wcoutput/*wcoutput部分输出数据
,the 1
Life 1
Next 1
No 1
Particular 1
So,only 1
and 3
官方examples的wordcount并没有过滤标点
hadoop伪分布式搭建
启动HDFS并运行MapReduce程序
- 配置:core-site.xml,在hadoop-2.7.2目录下
vim etc/hadoop/core-site.xml添加
fs.defaultFS hdfs://hadoop101:9000 hadoop.tmp.dir /opt/module/hadoop-2.7.2/data/tmp -
修改hadoop-env.sh,设置JAVA_HOME
vim etc/hadoop/hadoop-env.sh可以用 echo $JAVA_HOME 查看JAVA_HOME
修改为export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置:hdfs-site.xml,指定副本数为1(默认值为3)
vim etc/hadoop/hdfs-site.xml添加
dfs.replication 1 -
格式化NameNode(第一次启动时格式化)
bin/hdfs namenode -format -
启动namenode和datanode
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanodejps命令查看进程是否运行
网页访问hadoop101:50070
伪分布式下Wordcount案例
hdfs创建/user/liun/input文件夹
bin/hdfs dfs -mkdir -p /user/liun/input上传本地文件到hdfs
bin/hdfs dfs -put wcinput/wc.input /user/liun/input可在hadoop101:50070网页Utilities ->Browse the file system->Browse Directory输入/user/liun/input查看到
执行Wordcount案例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/liun/input /user/liun/output查看执行结果
bin/hdfs dfs -cat /user/liun/output/*启动YARN并运行MapReduce程序
配置YARN
- 配置yarn-env.sh
vim etc/hadoop/yarn-env.sh配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置yarn-site.xml
vim etc/hadoop/yarn-site.xml添加:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop101 -
配置:mapred-env.sh
vim etc/hadoop/mapred-env.sh配置JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置:mapred-site.xml
mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml vim etc/hadoop/mapred-site.xml添加
mapreduce.framework.name yarn
启动集群
启动前必须保证NameNode和DataNode已经启动
启动resourcemanager和nodemanager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanagerjps查看进程是否成功启动
网页输入hadoop101:8088
yarn下运行Wordcount
先删除hdfs上/user/liun/output目录
bin/hdfs dfs -rm -r /user/liun/output执行Wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/liun/input /user/liun/outputhadoop101:8088查看进度
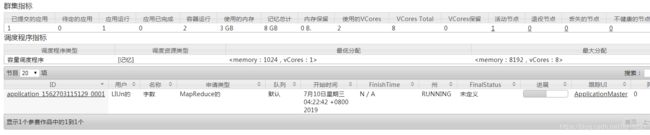
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
配置mapred-site.xml
vim etc/hadoop/mapred-site.xml添加以下信息:
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserverjps查看进程是否启动
hadoop101:19888/jobhistory查看JobHistory
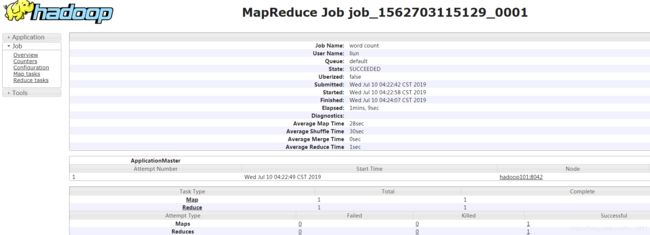
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager配置yarn-site.xml
vim etc/hadoop/yarn-site.xml添加
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
重新启动NodeManager 、ResourceManager和HistoryManager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver删除hdfs上/user/liun/output目录
bin/hdfs dfs -rm -r /user/liun/output重新运行Wordcount案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/liun/input /user/liun/output在JobHistory点击logs查看日志
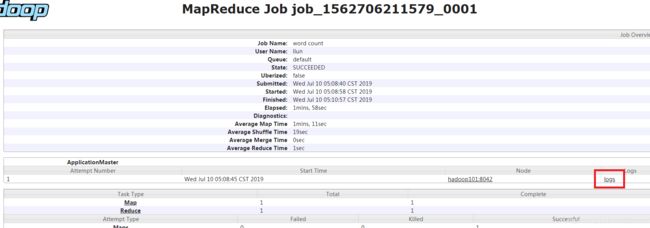

hadoop完全分布式
按照hadoop环境搭建步骤准备准备三台客户机hadoop101,hadoop102,hadoop103。直接克隆hadoop101,修改主机名和IP地址
集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
NameNode,SecondaryNameNode和ResourceManager需要内存资源大,尽量避免在同一台机器
为了方便集群部署,编写集群分发脚本xsync,设置ssh免密登陆,方便集群通信。
SSH无密登录配置
- 生成公钥和私钥(hadoop101,liun用户)
ssh-keygen -t rsa一直回车就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
-
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop101 ssh-copy-id hadoop102 ssh-copy-id hadoop103因为集群部署规划是NameNode在hadoop101,ResourceManager在hadoop102,所以:
还需要在hadoop101上采用root账号,配置一下无密登录到hadoop101、hadoop102、hadoop103;
还需要在hadoop102上采用liun账号配置一下无密登录到hadoop101、hadoop102、hadoop103服务器上。
xsync集群分发脚本
- 在/home/liun路径下新建文件夹bin,并在bin目录下xsync创建文件
说明:在/home/liun/bin这个目录下存放的脚本,liun用户可以在系统任何地方直接执行。cd /home/liun mkdir bin cd bin touch xsync vim xsync - 在该文件中编写如下代码
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=102; host<104; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done -
修改脚本 xsync 权限
chmod 777 xsync
分发/etc/profile和/opt/和 /opt/module/
xsync /etc/profile
xsync /opt/module/
修改hadoop配置文件
核心配置文件
配置core-site.xml,根据集群规划设置NameNode地址hadoop101节点
在该文件中编写如下配置
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
HDFS配置文件
配置hadoop-env.sh(配置JAVA_HOME,在伪分布式时已经配置过)
配置hdfs-site.xml
增加如下配置,也可以直接删除dfs.replication,删除默认为3
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop103:50090
YARN配置文件
配置yarn-env.sh(配置JAVA_HOME,在伪分布式时已经配置过)
配置yarn-site.xml
增加如下配置,根据集群规划设置YARN的ResourceManager的地址hadoop102节点
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102
MapReduce配置文件
配置mapred-env.sh(配置JAVA_HOME,在伪分布式时已经配置过)
配置mapred-site.xml(指定MR运行在Yarn上,在伪分布式时已经配置过)
通过xsync向集群分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-2.7.2/格式化NameNode,格式化之前删除所有节点hadoop-2.7.2目录下的data和logs
rm -rf /opt/module/hadoop-2.7.2/data/ /opt/module/hadoop-2.7.2/logs/所有节点删除后格式化NameNode
bin/hdfs namenode -format启动集群
配置slaves
vim /opt/module/hadoop-2.7.2/etc/hadoop/slaves添加
hadoop101
hadoop102
hadoop103注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
像所有节点分发slaves
xsync /opt/module/hadoop-2.7.2/etc/hadoop/slaves如果集群是第一次启动,需要格式化NameNode
启动HDFS
NameNode配置在hadoop101节点,在hadoop101执行
sbin/start-dfs.sh启动YARN
YARN的ResourceManager配置在hadoop102节点,在hadoop102执行
sbin/start-yarn.shjps查看各个节点进程是否启动
以上内容学习尚硅谷视频课程整理
2019-07-12
因为笔记本性能过低,准备了三台云服务器,部署完遇到的坑
NameNode无法启动
查看日志报错信息java.net.BindException: Problem binding to [hadoop101:9000] java.net.BindException:
删除了data和logs NameNode -format了好几次都不行
最后找的原因是云服务器公网ip不能用端口
解决办法:
hosts设置本机映射为私有网络ip,可以用ifconfig查看,其他节点映射用公网ip
NameNode 重新format
启动集群ok
云服务器8088端口访问不了
云服务器一定要设置好安全组规则,否则无法访问服务器端口