【机器学习】SVR支持向量机回归
回归和分类从某种意义上讲,本质上是一回事。SVM分类,就是找到一个平面,让两个分类集合的支持向量或者所有的数据(LSSVM)离分类平面最远;SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。
我们来推导一下SVR。根据支持向量机二分类博客所述,数据集合归一化后,某个元素到回归平面的距离为 r=d(x)−g(x) 。另外,由于数据不可能都在回归平面上,距离之和还是挺大,因此所有数据到回归平面的距离可以给定一个容忍值ε防止过拟合。该参数是经验参数,需要人工给定。如果数据元素到回归平面的距离小于ε,则代价为0。SVR的代价函数可以表示为:
cost(x)=max(0,|d(x)−g(x)|−ε)
其中d是标准答案。考虑松弛变量 ξi,ξ∗i ,分别代表上下边界的松弛因子。有约束条件:
{d(xi)−g(xi)<ε+ξi,ξi≥0g(xi)−d(xi)<ε+ξ∗i,ξ∗i≥0
我们实际上是要最小化 ξi,ξ∗i 。我们为了获得w的稀疏解,且假设w的计算结果满足正态分布,根据贝叶斯线性回归模型,对w有L2范数约束。
SVR可以转变为最优化问题:
Φ(x)=∑i(ξi+ξ∗i)+12C′wTw→Φ(x)=C∑i(ξi+ξ∗i)+12wTw
其中C是惩罚因子,是人为给定的经验参数。考虑约束条件,引入拉格朗日算子 α,α∗,β,β∗ ,将最优化问题转化为对偶问题:
J=12wTw+C∑i(ξi+ξ∗i)+∑iαi[d(xi)−g(xi)−ε−ξi]+∑iα∗i[g(xi)−d(xi)−ε−ξ∗i]−∑iβiξi−∑iβ∗iξ∗i
然后分别求导得到:
∂J∂w=w−(∑iαixi−∑iα∗ixi)=0∂J∂b=∑i(αi−α∗i)=0∂J∂ξi=C−αi−βi=0∂J∂ξ∗i=C−α∗i−β∗i=0C=αi+βi=α∗i+β∗i
将上述式子代入J函数有:
J=12wTw−∑i(αi−α∗i)wxi−b∑i(αi−α∗i)−∑i(αi+α∗i)ε+∑i(αi−α∗i)d(xi)+C∑i(ξi+ξ∗i)−∑iαiξi−∑iα∗iξ∗i−∑i(C−αi)ξi−∑i(C−α∗i)ξ∗i=12(∑iαixi−∑iα∗ixi)(∑jαjxj−∑jα∗jxj)−(∑iαixi−∑iα∗ixi)(∑jαjxj−∑jα∗jxj)−∑i(αi+α∗i)ε+∑i(αi−α∗i)d(xi)=−12∑i∑j(αi−α∗i)(αj−α∗j)xixj−∑i(αi+α∗i)ε+∑i(αi−α∗i)d(xi)subject to 0≤αi,α∗i≤C
其中 ξ,ξ∗,β,β∗ 都在计算过程中抵消了,非常神奇。 ε,C 则是人为给定的参数,是常量。如果要使用核函数,可以将上式写成:
J=−12∑i∑j(αi−α∗i)(αj−α∗j)k(xixj)−∑i(αi+α∗i)ε+∑i(αi−α∗i)d(xi)
SVR的代价函数和SVM的很相似,但是最优化的对象却不同,对偶式有很大不同,解法同样都是基于拉格朗日的最优化问题解法。求解这类问题的早期解法非常复杂,后来出来很多新的较为简单的解法,对数学和编程水平要求高,对大部分工程学人士来说还是颇为复杂和难以实现,因此大牛们推出了一些SVM库。比较出名的有libSVM,该库同时实现了SVM和SVR。
我们来看一个简单的例子,数据为[-5.0,9.0]的随机数组,函数为 y=12x2+3x+5+noise ,我分别使用三种核SVR:两种惩罚系数rbf和一种poly。结果如下:
from sklearn import svm
import numpy as np
from matplotlib import pyplot as plt
X = np.arange(-5.,9.,0.1)
X=np.random.permutation(X)
X_=[[i] for i in X]
#print X
b=5.
y=0.5 * X ** 2.0 +3. * X + b + np.random.random(X.shape)* 10.
y_=[i for i in y]
rbf1=svm.SVR(kernel='rbf',C=1, )#degree=2,,gamma=, coef0=
rbf2=svm.SVR(kernel='rbf',C=20, )#degree=2,,gamma=, coef0=
poly=svm.SVR(kernel='poly',C=1,degree=2)
rbf1.fit(X_,y_)
rbf2.fit(X_,y_)
poly.fit(X_,y_)
result1 = rbf1.predict(X_)
result2 = rbf2.predict(X_)
result3 = poly.predict(X_)
plt.hold(True)
plt.plot(X,y,'bo',fillstyle='none')
plt.plot(X,result1,'r.')
plt.plot(X,result2,'g.')
plt.plot(X,result3,'c.')
plt.show()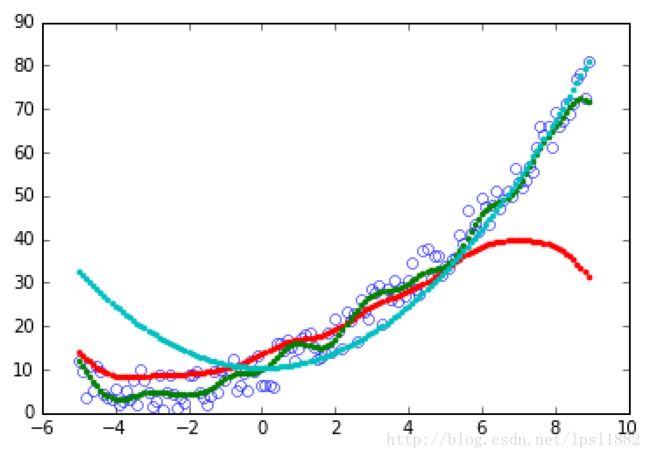
蓝色是poly,红色是c=1的rbf,绿色是c=20的rbf。其中效果最好的是c=20的rbf。如果我们知道函数的表达式,线性规划的效果更好,但是大部分情况下我们不知道数据的函数表达式,因此只能慢慢试验,SVM的作用就在这里了。就我来看,SVR的回归效果不如神经网络。
csdn的blog不知为何抽风了,只好重新写了一下。