使用3台虚拟机搭建Hadoop HA集群(2)
系列博客目录链接:Hadoop权威指南学习笔记:总章
基础环境搭建:使用3台虚拟机搭建Hadoop HA集群(1)
HA环境搭建:使用3台虚拟机搭建Hadoop HA集群(2)
本部分包含以下基本分内容
- 安装部署zookeeper
- 安装部署Hadoop相关组件
一. 部署zookeeper
1. zooKeeper 软件安装须知
鉴于 ZooKeeper 本身的特点,服务器集群的节点数推荐设置为奇数台。按照计划,此处规划三台。
2. zookeeper下载
操作节点:cloud2
官方下载链接如下:https://archive.apache.org/dist/zookeeper/ 。 选择合适版本下载。此处使用的是zookeeper 3.4.8版本。
3. 解压文件
操作节点:cloud2
tar -zxvf zookeeper-3.4.8.tar.gz
mv zookeeper-3.4.8 /home/hadoop/apps
cd /home/hadoop/apps
ln -s zookeeper-3.4.8 zookeeper
此处我将解压后的zookeeper文件夹统一放置于/home/hadoop/apps下,Hadoop同此,下面不再解释。
4. 编辑配置文件
操作节点:cloud2
hadoop@cloud2:~/apps$ cd zookeeper/conf
hadoop@cloud2:~/apps/zookeeper/conf$ ls
configuration.xsl log4j.properties zoo_sample.cfg
hadoop@cloud2:~/apps/zookeeper/conf$ cp zoo_sample.cfg zoo.cfg
原始配置文件内包含以下四个配置,进行以下简要说明:
- tickTime:心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
- initLimit:tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据非常大多时,同步时间相应可能会增加,那么这个值也需要相应增加。
- syncLimit:tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间。
- dataDir:内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上。
- clientPort:配置ZK监听客户端连接的端口
我们需要做的包含两项
a. 修改dataDir目录位置,我此处指定为/home/hadoop/data/zookeeper/data
b. 文件末尾追加:
dataLogDir=/home/hadoop/data/zookeeper/log
server.1=a.cloud.ha:2888:3888
server.2=b.cloud.ha:2888:3888
server.3=c.cloud.ha:2888:3888
其中dataLogDir为日志文件位置,后者格式如下:
server.serverid=host:tickpot:electionport
server:固定写法
serverid:每个服务器的指定ID(必须处于1-255之间,必须每一台机器不能重复)
host:主机名
tickpot:心跳通信端口
electionport:选举端口
5. 分发文件
操作节点:cloud1、cloud2、cloud3
将cloud2配置好的zookeeper文件发送至cloud1和cloud3,然后分别在对应节点创建数据目录及日志目录。步骤不再重复。
分发完文件后,我们需要在数据文件夹下创建一个名为myid的文件,内容为当前节点对应得serverid,如下图:

6. 配置环境变量
操作节点 cloud1、cloud2、cloud3
sudo vim /etc/profile
文末添加
export ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
加载环境变量
source /etc/profile
至此,zookeeper集群配置完成
二. 部署Hadoop
1. Hadoop的下载及安装
操作节点:cloud1
Hadoop各版本官方下载链接:https://archive.apache.org/dist/hadoop/common/,请选择合适的版本下载。本集群统一采用Hadoop-2.6.5版本。
2. 解压及创建连接文件
操作节点:cloud1
将下载后的压缩文件移到/home/hadoop/apps/目录下,执行解压命令:
cd /home/hadoop/apps/
tar -zxvf hadoop-2.6.5.tar.gz
创建连接文件:
ln -s hadoop-2.6.5 hadoop
3. 配置hadoop
操作节点:cloud1
hadoop的配置文件默认位于hadoop安装目录的etc/hadoop目录下,本例为/home/hadoop/apps/hadoop/etc/hadoop。
a. 修改hadoop-env.sh
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ echo $JAVA_HOME
/usr/java/jdk
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ vim hadoop-env.sh

b. 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://mycloud/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/data/hadoop/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>a.cloud.ha:2181,b.cloud.ha:2181,c.cloud.ha:2181value>
property>
<property>
<name>ha.zookeeper.session-timeout.msname>
<value>1000value>
<description>msdescription>
property>
configuration>
c. 配置hdfs-site.xml。按照计划,namenode配置在域名为a.cloud.ha和b.cloud.ha两台节点上。配置中设计到的相关目录需要自己根据自己情况创建。
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/hadoop/data/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/hadoop/data/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>mycloudvalue>
property>
<property>
<name>dfs.ha.namenodes.mycloudname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycloud.nn1name>
<value>a.cloud.ha:9000value>
property>
<property>
<name>dfs.namenode.http-address.mycloud.nn1name>
<value>a.cloud.ha:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.mycloud.nn2name>
<value>b.cloud.ha:9000value>
property>
<property>
<name>dfs.namenode.http-address.mycloud.nn2name>
<value>b.cloud.ha:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://a.cloud.ha:8485;b.cloud.ha:8485;c.cloud.ha:8485/mycloudvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/data/hadoop/journal/datavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.mycloudname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.msname>
<value>60000value>
property>
configuration>
d. 修改mapred-site.xml
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>a.cloud.ha:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>a.cloud.ha:19888value>
property>
configuration>
e. 修改yarn-site.xml。按照计划,ResourceManager配置在域名为a.cloud.ha和b.cloud.ha两台节点上。
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>b.cloud.havalue>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>c.cloud.havalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>a.cloud.ha:2181,b.cloud.ha:2181,c.cloud.ha:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>86400value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
f. 修改slave。按照计划,在域名为b.cloud.ha,c.cloud.ha的两台节点部署namenode和nodemanager。
b.cloud.ha
c.cloud.ha
g. 分发文件。此处将整个hadoop文件夹分发到剩余两台节点。所有节点hadoop文件夹皆在/home/hadoop/apps/目录下。
4. 配置环境变量
操作节点:cloud1、cloud2、cloud3
在/etc/profile末尾追加:
export HADOOP_HOME=/home/hadoop/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
加载环境变量
source /etc/profile
执行hadoop version验证环境变量配置,无异常表示配置完成
三. 初始化hadoop集群
请务必按步骤依次操作,需要在两个及以上节点操作的,一定要在所有节点操作进行完成后,再继续下一个步骤,否则会产生不可预知错误。
1. 初始化zookeeper集群
操作节点:cloud1、cloud2、cloud3
依次在所有节点手动执行zkServer.sh start来启动zookeeper节点。使用zkServer.sh status和jps命令查看启动状态。

2. 初始化journalNode
操作节点:cloud1、cloud2、cloud3
按照计划,我们会在所有节点启动journalNode,因此以下命令需要在三台节点分别执行。
hadoop-daemon.sh start journalnode
同理执行jps查看。

3. 格式化NameNode
操作节点:cloud1或cloud2
按照计划,我们会在cloud1和cloud2启动一主一备NameNode,任一节点操作即可。此处选用cloud1
hadoop namenode -format
如图表示格式化完成。

4. 格式化备用NameNode
第三步在cloud1进行了NameNode格式化,此处我们要在cloud2进行格式化。
hadoop@cloud1:hadoop namenode -bootstrapStandby
5. 格式化zkfc并启动zkfc
操作节点:cloud1、cloud2
按照计划,zkfc在cloud1、cloud2运行。事实上,zkfc也只能在NameNode上运行。启动之前,我们需要首先格式化zkfc。
a. 格式化zkfc,在任一NameNode节点操作即可。
hdfs zkfc -formatZK
b. 启动zkfc,此步骤需要在两个NameNode操作。
hadoop-daemon.sh start zkfc
启动完成后,使用jps命令应该可以看到DFSZKFailoverController进程。
四. 启动集群
1. 启动HDFS和Yarn
操作节点:cloud2
在cloud2执行以下命令启动HDFS及Yarn。启动相应服务需要在相应服务的主节点上启动。因为ResourceManager和Namenode在cloud2上皆有服务,故在cloud2启动
start-dfs.sh;start-yarn.sh
2. 启动MapReduce历史作业服务器
操作节点:cloud1
mr-jobhistory-daemon.sh start historyserver
3. 检查
操作节点:任一节点即可
a. 经过以上所有步骤之后,各个节点包含的服务应该如下图:分别与计划中规划的服务对应
- cloud1

- cloud2

- cloud3

对于任意节点没有起来的进程,可通过hadoop-daemon.sh启动HDFS系列组件或通过yarn-daemon.sh启动Yarn相关组件,但启动之前应该首先将错误排除。
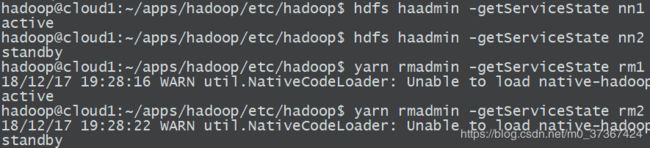
b. 命令行检查主服务节点状态:
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ hdfs haadmin -getServiceState nn1
active
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ hdfs haadmin -getServiceState nn2
standby
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ yarn rmadmin -getServiceState rm1
18/12/17 19:28:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
hadoop@cloud1:~/apps/hadoop/etc/hadoop$ yarn rmadmin -getServiceState rm2
18/12/17 19:28:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
c. 网页端检查
- HDFS

- YARN

至此,HA集群搭建完毕。关于集群的kill测试,可以根据以下几方面测试,此处不再叙述。
- 集群空闲时kill掉任意一台NM,测试文件写入
- 写入大文件时,kill掉任意一台NM,查看文件是否丢失
- 任务运行时,kill掉任意一台RM,查看任务是否失败
- 无任务运行时,kill掉任意一台RM,查看任务能否提交