知识图谱—关系抽取—远程监督—OpenNRE(一)
一、远程监督简介
远程监督的英文名称Distant Supervision,是目前关系抽取中比较常见的一类做法。该方法由 M Mintz 大佬于ACL2009上首次提出,它既不是单纯的传统意义上的监督语料,当然也不是无监督。它是一种用KB去对齐朴素文本的标注方法(Distant supervision for relation extraction without labeled data )。
KB中已经存在实体-关系-实体的三元组,只需要把这三元组付给朴素文本中相应的句子就可以了。这时候z大佬就提出了一个非常大的假设:如果一个句子中含有一个关系涉及的实体对,那这个句子就是描述的这个关系。也就是说,报纸里所有含有中国和北京的句子,全都假设说的是北京是中国的首都。然后把这些句子全都提取出来作为首都这个关系的训练语料,直接批量打个标签,实体识别和标注一举两得。然后把一个关系对应的所有句子打个包,称作一个bag,干脆一个bag一个标签。这就是后来又有的工作,被叫做多示例学习。
上述方法有很多不严谨的地方,例如乔布斯是苹果的创始人,和乔布斯吃了一个苹果,表达的完全不是一个关系。这就说明远程监督的数据里存在大量的噪声,我们把真正含有指定关系的句子叫做real instance ,实际上不含任何关系的句子叫NA,其余的就都是反例。这个噪声问题被叫做wrong label 问题。这是远程监督方法第一个需要解决的大问题。
二、远程监督优化
下面主要介绍三种远程监督的优化方法:
1、dynamic-transition matrix(动态转移矩阵),它能很好的拟合由 distant supervision 所带来的噪声。通过该矩阵,我们能够大大提高 relation extraction 的效果。
2、rule learning(规则学习),通过定义规则,定义否定模式(negative pattern)过滤掉一些噪音数据,可以很大程度提高性能。缺点是规则依赖人工定义,通用性差,但是方法本身简单有效。
3、清华刘知远团队的NER,利用了包含实体对的所有的句子信息,提出了attention机制,去解决远程监督的wrong label的问题。
三、dynamic-transition matrix(动态转移矩阵)
本文中,作者使用一种对噪音数据显式建模(拟合噪音)的方法。尽管噪音数据是不可避免的,但是用一种统一的框架对噪音数据模式进行描述是可能的。作者的出发点是,远程监督数据集中通常会有对噪音模式有用的线索。比如说,一个人的工作地点和出生地点很有可能是同一个地点,这种情形下远程监督数据集就很有可能把born-in和work-in这两个关系标签打错。本文使用的方法是,对于每一个训练样本,对应一个动态生成的跃迁矩阵(transition matrix)。这个矩阵的作用是:
- 对标签出错的概率进行描述
- 标示噪音模式
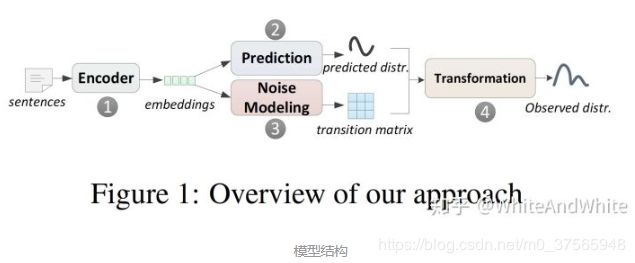
模型如图所示,1,2跟以前的方法一致:对一个句子encode, 然后分类,得到一个句子的关系distribution。同时,3为模型动态地产生一个transition matrix T, 用来描述噪音模式。4就是将2,3的结果相乘,得到最终结果。
换句话说,在训练阶段,使用4的输出结果,作为加噪输出和标签匹配,也就是training loss使用的是4的输出结果和训练数据的标签进行计算。
Global transition matrix 在关系层面上定义一个特定的转移矩阵,比如:
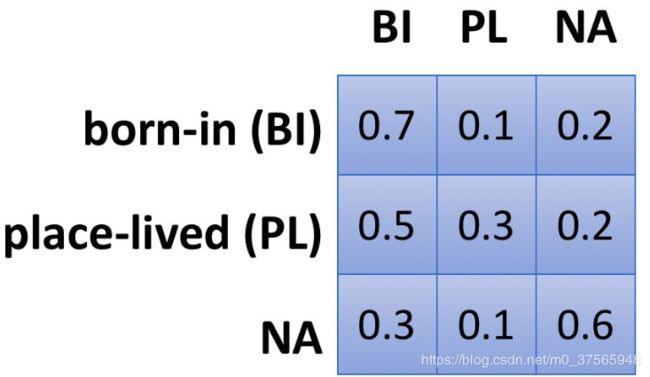
属于 A 关系的句子,被误判为 B 关系的概率是恒定的。Dynamic transition matrix 是在句子层面上定义的,即使同属于 A 关系,a1 句子和 b1 句子被误判成 B 关系的概率也不同。比如下面两句话,带有 old house 的被误判成 born-in 的概率更大。
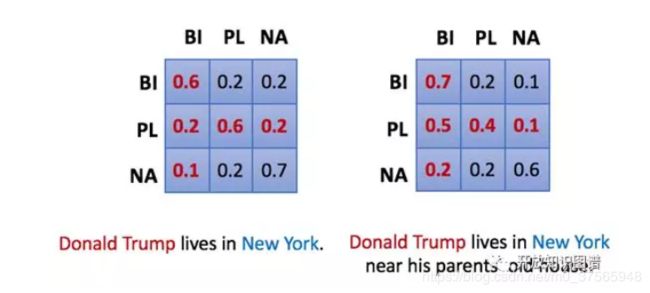
动态转移矩阵更有优势,粒度更细。
PS:
时间实体粒度越细,数据越可靠。例如:
如果一句话Alphabet含有October-2-2015则很有可能描述了inception-time of(创立)这种关系。如果一句话含有Alphabet和2015,那么描述的关系可能性就会变多,例如发布财报,聘用新的CEO等等。利用这种启发式想法,本文将该数据集根据时间详细粒度分为三部分,分别代表三个不同可靠性的数据集。
分数据集的方式是:带有年月日,带有年月,带有年,以及其他时间(Wikidata中没有的三元组)的样本作为负样本。
本节详情1、本节详情2
四、rule learning(规则学习)
在关系提取方面,远程监督试图通过使用知识库(如Freebase)作为监督来源,从文本中提取实体之间的关系。当一个句子和一个知识库引用同一个实体对时,这种方法试图用知识库中的对应关系来启发式地标注句子。 然而,这种启发式可能会导致一些句子被错误地标记。 这种嘈杂的标记数据导致较差的抽取性能。在本文中,我们提出了一种减少错误标签数量的方法。 我们提出了一个新的生成模型,直接模拟远程监督的启发式标签过程。 该模型通过其隐藏变量来预测分配的标签是正确的还是错误的。在实验中,我们也发现错误的标签减少提高了关系抽取的性能。

NegPat(r)即为事先定义的对于r的否定模式(negative pattern)。在我们的方法中,我们按如下所示去除错误标签:
(i)给定一个已标注的语料库,我们首先验证其中的模式是否表达一种relation
(ii)使用否定模式列表(NegPat)去除错误的标签, 即该模式被定义为不表示relation的模式。
第一步,我们引入新的生成模型,直接模拟DS的标注过程并进行预测。 第二步在算法1中描述,见上图。对于关系提取,我们使用上述得到的标注数据来训练分类器(给定实体对,该分类器预测所属关系)。
PS:
现阶段该方式应用较多,对于单一关系的抽取,考虑成本问题,建议采取该方式。
五、thunlp-NRE
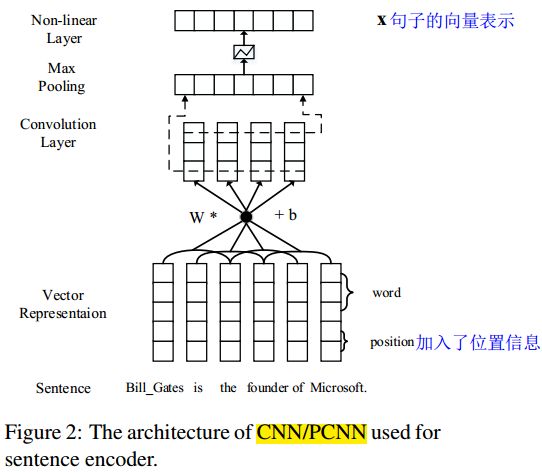
- 把一句话中的每一个字,用word2vec中的向量表示出来;把每个字距离2个实体的距离作为位置信息加入到刚刚的向量的末尾2位上。这样,每个字都有一个短向量表示;
- 对上面的短向量进行Convolution, Max-pooling and Non-linear Layers的操作,生成最后的整个句子的表示。 这个过程相当于提取每个句子的特征。
- 对包含某对实体对的所有句子,采用attention机制进行选择,将最能表达这种关系的句子们挑选出来。
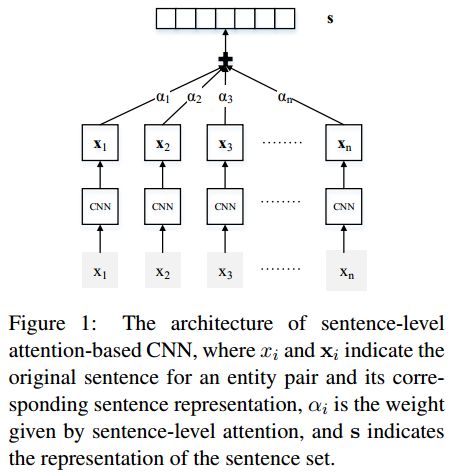
论文贡献如下:
(1)与以往的神经网络关系抽取模型相比,本文利用了包含实体对的所有的句子信息。
(2)提出了attention机制,去解决远程监督的wrong label的问题。
(3)attention机制对于2中关系抽取的神经网络模型都是管用的:CNN, PCNN。
PS:
为什么有RNN、LSTM还用CNN处理NLP任务:
CNN就是一个超级N-Gram,而N-Gram就是考虑局部统计信息的语言模型,CNN相当于在低维向量空间中实现了它。
如果我们用一个滑动窗口(比如宽度是2)滑过一个句子,那么,我们便可以提取到句子中的所有2-gram。假设句子中的字都是用向量 表示的,那么,如果用卷积核 跟这个序列卷积就得到了向量序列也就是对句子中的每个2-gram 构造了个向量表示。
不过这种向量表示真的合理吗?构造出的向量真能表达2-gram的语义吗?假设句子中包括这样两个2-gram,“吃饭”和“美丽”。有什么理由认为“吃”和“饭”的加权方式应该跟“美“和”丽“的加权方式一样?注意前者是动宾结构,后者是并列结构,分别对应于不同意义上的语义组合。所以这其实是卷积类的语义表达面临的问题。
最近attention 有取代卷积的趋势,变成"all you need" 的了。attention详情
thunlp-NRE提供了开源的代码,我们可以在上面训练自己的model。链接1、链接2。