HashSet源码解析(基于JDK1.8)
HashSet是Java中经常被用到的集合,弄清它的底层实现,有利于我们更好地使用它,又是这句话….. 不过HashSet相对于其他集合框架简单了不少。
老规矩,还是先看看它的UML图:
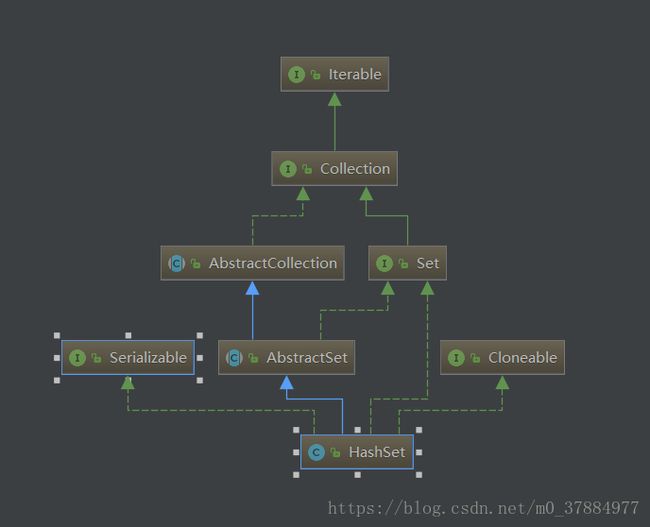
①:实现了Serializable接口,表明它支持序列化。
②:实现了Cloneable接口,表明它支持克隆,可以调用超类的clone()方法进行浅拷贝。
③继承了AbstractSet抽象类,和ArrayList和LinkedList一样,在他们的抽象父类中,都提供了equals()方法和hashCode()方法。它们自身并不实现这两个方法,(但是ArrayList和LinkedList的equals()实现不同。你可以看我的关于ArrayList这一块的源码解析)这就意味着诸如和HashSet一样继承自AbstractSet抽象类的TreeSet、LinkedHashSet等,他们只要元素的个数和集合中元素相同,即使他们是AbstractSet不同的子类,他们equals()相互比较的后的结果仍然是true。下面给出的代码是JDK中的equals()代码:
从JDK源码可以看出,底层并没有使用我们常规认为的利用hashcode()方法求的值进行比较,而是通过调用AbstractCollection的containsAll()方法,如果他们中元素完全相同(与顺序无关),则他们的equals()方法的比较结果就为true。
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection c = (Collection) o;
//必须保证元素的个数相等。
if (c.size() != size())
return false;
try {
//调用了AbstractCollection的方法。
return containsAll(c);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public boolean containsAll(Collection c) {
//只需要逐个判断集合是否包含其中的元素。
for (Object e : c)
if (!contains(e))
return false;
return true;
}④实现了Set接口。
老规矩还是先把总结放到上面:
①HashSet内部通过使用HashMap的键来存储集合中的元素,而且内部的HashMap的所有值
都是null。(因为在为HashSet添加元素的时候,内部HashMap的值都是PRESENT),而PRESENT在实例域的地方直接初始化了,而且不允许改变。
②HashSet对外提供的所有方法内部都是通过HashMap操作完成的,所以,要真正理解HashSet的实现,只需要把HashMap的原理理解即可。我也对HashMap做了分析。传送门:
③所以,如果你对HashMap很熟悉的话,学习HastSet的源码轻而易举!
1:首先我们先看看HashSet的有哪些实例域:(是不是少了很多,而且还简单(⊙o⊙)…)
//序列化ID
static final long serialVersionUID = -5024744406713321676L;
//底层使用了HashMap存储数据。
private transient HashMap map;
//用来填充底层数据结构HashMap中的value,因为HashSet只用key存储数据。
private static final Object PRESENT = new Object(); 2:老规矩,还是先看一下它们的构造方法:
构造器的实现基本都是使用HashMap,所以不懂的可用去看看我的另一篇关于HashMap源码解析的文章。
//其实只是实例化了HashMap (⊙o⊙)…(不懂的童鞋,可以看我的另一篇关于HashMap的源码解析)
public HashSet() {
map = new HashMap<>();
}//还是关于
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//调用的AbstractCollection中的方法。然后调用HashSet的add()方法把集合中的
//所有元素添加到了集合中。(因为)
public boolean addAll(Collection c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
//底层并不支持直接在AbstractCollection类中调用add()方法,而是调用add()方法
//的自身实现。
public boolean add(E e) {
throw new UnsupportedOperationException();
}//初始化HashSet仍然是关于HashMap的知识。
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}//初始化HashSet仍然是关于HashMap的知识。
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}//这次初始化底层使用了LinkedHashMap实现。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}3:添加新的元素:
//底层仍然利用了HashMap键进行了元素的添加。
//在HashMap的put()方法中,该方法的返回值是对应HashMap中键值对中的值,而值总是PRESENT,
//该PRESENT一直都是private static final Object PRESENT = new Object();
//PRESENT只是初始化了,并不能改变,所以PRESENT的值一直为null。
//所以只要插入成功了,put()方法返回的值总是null。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}4:删除一个元素:
//该方法底层实现了仍然使用了map的remove()方法。
//map的remove()方法的返回的是被删除键对应的值。(在HashSet的底层HashMap中的所有
//键值对的值都是PRESENT)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}5:清空方法
public void clear() {
map.clear();
}6:克隆方法(浅克隆)
底层仍然使用了Object的clone()方法,得到的Object对象,并把它强制转化为HashSet,然后把它的底层的HashMap也克隆一份(调用的HashMap的clone()方法),并把它赋值给newSet,最后返回newSet即可。
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet newSet = (HashSet) super.clone();
newSet.map = (HashMap) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
} 7:是否包含某个元素
底层仍然使用了HashMap的containsKey()方法(因为HashSet只用到了HashMap的键)同样的话重复了好多遍 ……….(艹皿艹 )
public boolean contains(Object o) {
return map.containsKey(o);
}
8:判断是否为空
仍然调用HashMap的方法。
public boolean isEmpty() {
return map.isEmpty();
}9:生成一个迭代器
仍然使用了HashMap的键的迭代器
public Iterator iterator() {
return map.keySet().iterator();
} 10: 统计HashSet中包含元素的个数
还是调用HashMap的实现。
public int size() {
return map.size();
}11:把HashSet写入流中(也就是序列化)
在HashSet序列化实现中,仍然是把HashMap中的属性写入流中。(因为HashSet中真正存储数据的数据结构是HashMap。)
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
//把HashMap的容量写入流中。
s.writeInt(map.capacity());
//把HashMap的装载因子写入流中。
s.writeFloat(map.loadFactor());
//把HashMap中键值对的个数写入流中。
s.writeInt(map.size());
// 按正确的顺序把集合中的所有元素写入流中。
for (E e : map.keySet())
s.writeObject(e);
}12:从流中读取数据,组装HashSet(反序列化)
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read capacity and verify non-negative.
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
// Read load factor and verify positive and non NaN.
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
// Read size and verify non-negative.
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
//HashMap中构建哈希桶数组是在第一个元素被添加的时候才构建,所以在构建之前检查它,
// 调用HashMap.tableSizeFor来计算实际分配的大小,
// 检查Map.Entry []类,因为它是最接近的公共类型实际创建的内容。
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class,HashMap.tableSizeFor(capacity));
//创建HashMap。
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap(capacity, loadFactor) :
new HashMap(capacity, loadFactor));
// 按写入流中的顺序再把元素依次读取出来放到map中。
for (int i=0; i@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}