欢迎关注我的微信公众号:FunnyBigData
作为打着 “内存计算” 旗号出道的 Spark,内存管理是其非常重要的模块。作为使用者,搞清楚 Spark 是如何管理内存的,对我们编码、调试及优化过程会有很大帮助。本文之所以取名为 "Spark 内存管理的前世今生" 是因为在 Spark 1.6 中引入了新的内存管理方案,而在之前一直使用旧方案。
刚刚提到自 1.6 版本引入了新的内存管理方案,但并不是说在 1.6 及之后的版本中不能使用旧的方案,而是默认使用新方案。我们可以通过设置 spark.memory.userLegacyMode 值来选择,该值为 false 表示使用新方案,true 表示使用旧方案,默认为 false。该值是如何发挥作用的呢?如下:
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
根据 spark.memory.useLegacyMode 值的不同,会创建 MemoryManager 不同子类的实例:
- 值为
false:创建UnifiedMemoryManager类实例,为新的内存管理的实现 - 值为
true:创建StaticMemoryManager类实例,为旧的内存管理的实现
不管是在新方案中还是旧方案中,都根据内存的不同用途,都包含三大块。
- storage 内存:用于缓存 RDD、展开 partition、存放 Direct Task Result、存放广播变量。在 Spark Streaming receiver 模式中,也用来存放每个 batch 的 blocks
- execution 内存:用于 shuffle、join、sort、aggregation 中的缓存、buffer
storage 和 execution 内存都通过 MemoryManager 来申请和管理,而另一块内存则不受 MemoryManager 管理,主要有两个作用:
- 在 spark 运行过程中使用:比如序列化及反序列化使用的内存,各个对象、元数据、临时变量使用的内存,函数调用使用的堆栈等
- 作为误差缓冲:由于 storage 和 execution 中有很多内存的使用是估算的,存在误差。当 storage 或 execution 内存使用超出其最大限制时,有这样一个安全的误差缓冲在可以大大减小 OOM 的概率
这块不受 MemoryManager 管理的内存,由系统预留以及 storage 和 execution 安全系数之外的内存组成,这个会在下文中详述。
接下来,让我们先来看看 “前世”
前世
旧方案的内存结构如下图所示:
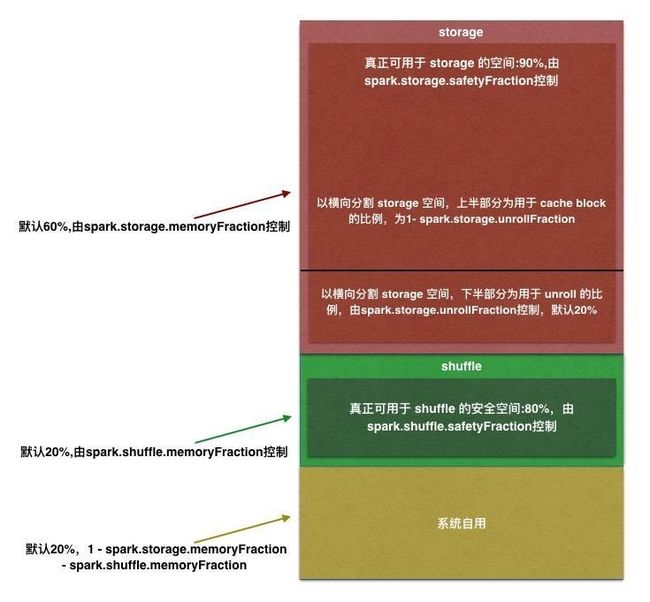
让我们结合上图做进一步说明:
execution 内存
execution 最大可用内存为 jvm space * spark.storage.memoryFraction * spark.storage.safetyFraction,默认为 jvm space * 0.2 * 0.8。
spark.shuffle.memoryFraction 很大程度上影响了 spill 的频率,如果 spill 过于频繁,可以适当增大 spark.shuffle.memoryFraction 的值,增加用于 shuffle 的内存,减少Spill的次数。这样一来为了避免内存溢出,可能需要减少 storage 的内存,即减小spark.storage.memoryFraction 的值,这样 RDD cache 的容量减少,在某些场景下可能会对性能造成影响。
由于 shuffle 数据的大小是估算出来的(这主要为了减少计算数据大小的时间消耗),会存在误差,当实际使用的内存比估算大的时候,这里 spark.shuffle.safetyFraction 用来作为一个保险系数,增加一定的误差缓冲,降低实际内存占用超过用户配置值的可能性。所以 execution 真是最大可用的内存为 0.2*0.8=0.16。shuffle 时,一旦 execution 内存使用超过该比例,就会进行 spill。
storage 内存
storage 最大可用内存为 jvm space * spark.storage.memoryFraction * spark.storage.safetyFraction,默认为 jvm space * 0.6 * 0.9。
由于在 cache block 时大小也是估算的,所以也需要一个保险系数用来防止误差引起 OOM,即 spark.storage.safetyFraction,所以真实能用来进行 memory cache block 的内存大小的比例为 0.6*0.9=0.54。一旦 storage 使用内存超过该比例,将根据 StorageLevel 决定不缓存 block 还是 OOM 或是存储到磁盘。
storage 内存中有 spark.shuffle.unrollFraction 的部分是用来 unroll,即用于 “展开” 一个 partition 的数据,这部分默认为 0.2
不由 MemoryManager 管理的内存
系统预留的大小为:1 - spark.storage.memoryFraction - spark.shuffle.memoryFraction,默认为 0.2。另一部分是 storage 和 execution 保险系数之外的内存大小,默认为 0.1。
存在的问题
旧方案最大的问题是 storage 和 execution 的内存大小都是固定的,不可改变,即使 execution 有大量的空闲内存且 storage 内存不足,storage 也无法使用 execution 的内存,只能进行 spill,反之亦然。所以,在很多情况下存在资源浪费。
另外,旧方案中,只有 execution 内存支持 off heap,storage 内存不支持 off heap。
今生
上面我们提到旧方案的两个不足之处,在新方案中都得到了解决,即:
- 新方案 storage 和 execution 内存可以互相借用,当一方内存不足可以向另一方借用内存,提高了整体的资源利用率
- 新方案中 execution 内存和 storage 内存均支持 off heap
这两点将在后文中进一步展开,我们先来看看新方案中,默认的内存结构是怎样的?依旧分为三块(这里将 storage 和 execution 内存放在一起讲):
- 不受 MemoryManager 管理内存,由以下两部分组成:
- 系统预留:大小默认为
RESERVED_SYSTEM_MEMORY_BYTES,即 300M,可以通过设置spark.testing.reservedMemory改变,一般只有测试的时候才会设置该配置,所以我们可以认为系统预留大小为 300M。另外,executor 的最小内存限制为系统预留内存的 1.5 倍,即 450M,若 executor 的总内存大小小于 450M,则会抛出异常 - storage、execution 安全系数外的内存:大小为
(heap space - RESERVED_SYSTEM_MEMORY_BYTES)*(1 - spark.memory.fraction),默认为(heap space - 300M)* 0.4
- 系统预留:大小默认为
- storage + execution:storage、execution 内存之和又叫 usableMemory,总大小为
(heap space - 300) * spark.memory.fraction,spark.memory.fraction默认为 0.6。该值越小,发生 spill 和 block 踢除的频率就越高。其中:- storage 内存:默认占其中 50%(包含 unroll 部分)
- execution 内存:默认同样占其中 50%
由于新方案是 1.6 后默认的内存管理方案,也是目前绝大部分 spark 用户使用的方案,所以我们有必要更深入且详细的展开分析。
初探统一内存管理类
在最开始我们提到,新方案是由 UnifiedMemoryManager 实现的,我们先来看看该类的成员及方法,类图如下:

通过这个类图,我想告诉你这几点:
- UnifiedMemoryManager 具有 4 个 MemoryPool,分别是堆内的 onHeapStorageMemoryPool 和 onHeapExecutionMemoryPool 以及堆外的 offHeapStorageMemoryPool 和 offHeapExecutionMemoryPool(其中,execution 和 storage 使用堆外内存的方式不同,后面会讲到)
- UnifiedMemoryManager 申请、释放 storage、execution、unroll 内存的方法(看起来像废话)
- tungstenMemoryAllocator 会根据不同的 MemoryMode 来生成不同的 MemoryAllocator
- 若 MemoryMode 为 ON_HEAP 为 HeapMemoryAllocator
- 若 MemoryMode 为 OFF_HEAP 则为 UnsafeMemoryAllocator(使用 unsafe api 来申请堆外内存)
如何申请 storage 内存
有了上面的这些基础知识,再来看看是怎么申请 storage 内存的。申请 storage 内存是通过调用
UnifiedMemoryManager#acquireStorageMemory(blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean
更具体的说法应该是为某个 block(blockId 指定)以那种内存模式(on heap 或 off heap)申请多少字节(numBytes)的 storage 内存,该函数的主要流程如下图:
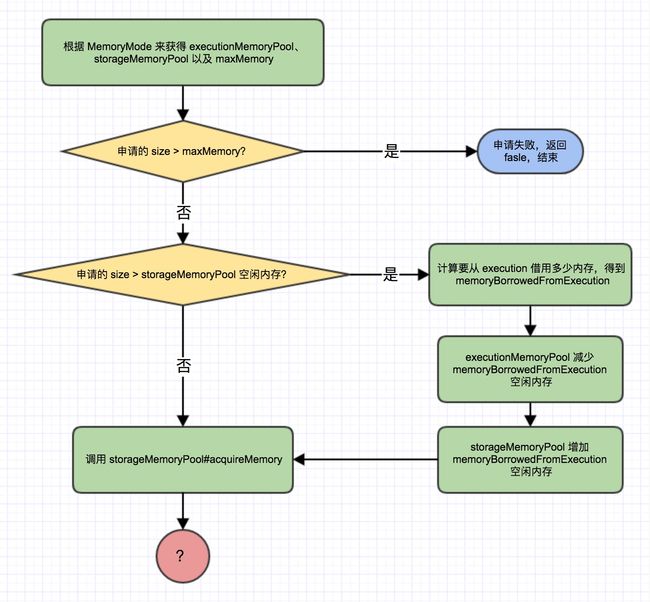
对于上图,还需要做一些补充来更好理解:
MemoryMode
- 如果 MemoryMode 是 ON_HEAP,那么 executionMemoryPool 为 onHeapExecutionMemoryPool、storageMemoryPool 为 onHeapStorageMemoryPool。maxMemory 为
(jvm space - 300M)* spark.memory.fraction,如果你还记得的话,这在文章最开始的时候有介绍 - 如果 MemoryMode 是 OFF_HEAP,那么 executionMemoryPool 为 offHeapExecutionMemoryPool、storageMemoryPool 为 offHeapMemoryPool。maxMemory 为 maxOffHeapMemory,由
spark.memory.offHeap.size指定,由 execution 和 storage 共享
要向 execution 借用多少?
计算要向 execution 借用多少内存的代码如下:
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree, numBytes)
为 execution 空闲内存和申请内存 size 的较小值,这说明了两点:
- 能借用到的内存大小可能是小于申请的内存大小的(当
executionPool.memoryFree < numBytes),更进一步说,成功借用到的内存加上 storage 原本空闲的内存之和有可能还是小于要申请的内存大小 - execution 只可能把自己当前空闲的内存借给 storage,即使在这之前 execution 已经从 storage 借来了大量内存,也不会释放自己已经使用的内存来 “还” 给 storage。execution 这么不讲道理是因为要实现释放 execution 内存来归还给 storage 复杂度太高,难以实现
还有一点需要注意的是,借用是发生在相同 MemoryMode 的 storageMemoryPool 和 executionMemoryPool 之间,不能在不同的 MemoryMode 间进行借用
借到了就万事大吉?
当 storage 空闲内存不足以分配申请的内存时,从上面的分析我们知道会向 execution 借用,借来后是不是就万事大吉了?当然······不是,前面也提到了即使借到了内存也可能还不够,这也是上图中红色圆框中问号的含义,在我们再进一步跟进到 StorageMemoryPool#acquireMemory(blockId: BlockId, numBytes: Long): Boolean 中一探究竟,该函数主要流程如下:
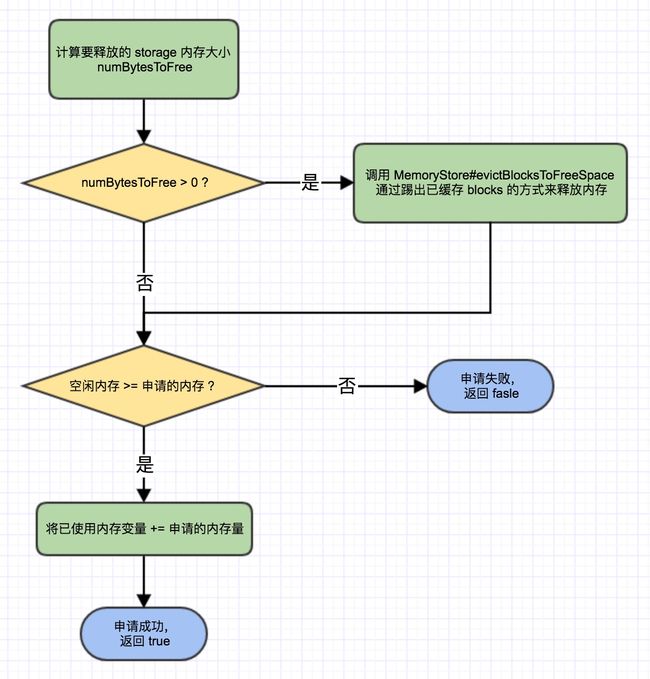
同样,对于上面这个流程图需要做一些说明:
计算要释放的内存量
val numBytesToFree = math.max(0, numAcquireBytes - memoryFree)
如上,要释放的内存大小为再从 execution 借用了内存,使得 storage 空闲内存增大 n(n>=0) 后,还比申请的内存少的那部分内存,若借用后 storage 空闲内存足以满足申请的大小,则 numBytesToFree 为 0,无需进行释放
如何释放 storage 内存?
释放的方式是踢除已缓存的 blocks,实现为 evictBlocksToFreeSpace(blockId: Option[BlockId], space: Long, memoryMode: MemoryMode): Long,有以下几个原则:
- 只能踢除相同 MemoryMode 的 block
- 不能踢除属于同一个 RDD 的另一个 block
首先会进行预踢除(所谓预踢除就是计算假设踢除该 block 能释放多少内存),预踢除的具体逻辑是:遍历一个已缓存到内存的 blocks 列表(该列表按照缓存的时间进行排列,约早缓存的在越前面),逐个计算预踢除符合原则的 block 是否满足以下条件之一:
- 预踢除的累计总大小满足要踢除的大小
- 所有的符合原则的 blocks 都被预踢除
若最终预踢除的结果是可以满足要提取的大小,则对预踢除中记录的要踢除的 blocks 进行真正的踢除。具体的方式是:如果从内存中踢除后,还具有其他 StorageLevel 或在其他节点有备份,依然保留该 block 信息;若无,则删除该 block 信息。最终,返回踢除的总大小(可能稍大于要踢除的大小)。
若最终预踢除的结果是无法满足要提取的大小,则不进行任何实质性的踢除,直接返回踢除size 为 0。需要再次提醒的是,只能踢除相同 MemoryMode 的 block。
以上,结合两幅流程图及相应的说明,相信你已经搞清楚如何申请 storage 内存了。我们再来看看 execution 内存是如何申请的
如何申请 execution 内存
我们知道,申请 storage 内存是为了 cache 一个 numBytes 的 block,结果要么是申请成功、要么是申请失败,不存在申请到的内存数比 numBytes 少的情况,这是因为不能将 block 一部分放内存,一部分 spill 到磁盘。但申请 execution 内存则不同,申请 execution 内存是通过调用
UnifiedMemoryManager#acquireExecutionMemory(numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long
来实现的,这里的 numBytes 是指至多 numBytes,最终申请的内存数比 numBytes 少也是成功的,比如在 shuffle write 的时候使用的时候,如果申请Å的内存不够,则进行 spill。
另一个特点是,申请 execution 时可能会一直阻塞,这是为了能确保每个 task 在进行 spill 之前都能占用至少 1/2N 的 execution pool 内存数(N 为 active tasks 数)。当然,这也不是能完全确保的,比如 tasks 数激增但老的 tasks 还没释放内存就不能满足。
接下来,我们来看看如何申请 execution 内存,流程图如下:
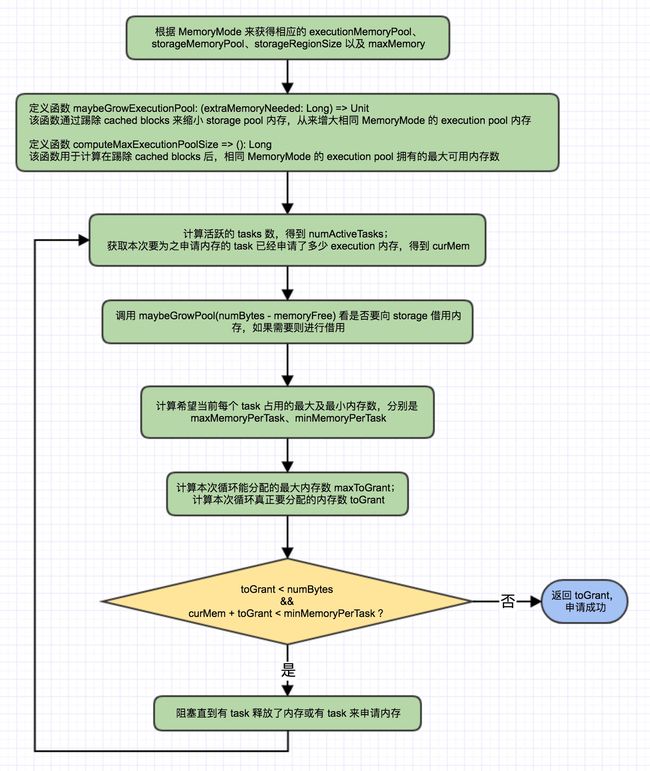
从上图可以看到,整个流程还是挺复杂的。首先,我先对上图中的一些环节进行进一步说明以帮助理解,最后再以简洁的语言来概括一下整个过程。
MemoryMode
同样,不同的 MemoryMode 的情况是不同的,如下:
- 如果 MemoryMode 为 ON_HEAP:
- executionMemoryPool 为 onHeapExecutionMemoryPool
- storageMemoryPool 为 onHeapStorageMemoryPool
- storageRegionSize 为 onHeapStorageRegionSize,即
(heap space - 300M) * spark.memory.storageFraction - maxMemory 为 maxHeapMemory,即
(heap space - 300M)
- 如果 MemoryMode 为 OFF_HEAP:
- executionMemoryPool 为 offHeapExecutionMemoryPool
- storageMemoryPool 为 offHeapStorageMemoryPool
- maxMemory 为 maxOffHeapMemory,即
spark.memory.offHeap.size - storageRegionSize 为 offHeapStorageRegionSize,即
maxOffHeapMemory * spark.memory.storageFraction
这一小节描述的内容非常重要,因为之后所有的流程都是基于此,看到后面的流程时,还记着会有 ON_HEAP 和 OFF_HEAP 两种情况
maybeGrowExecutionPool(向 storage 借用内存)
只有当 executionMemoryPool 的空闲内存不足以满足申请的 numBytes 时,该函数才会生效。那这个函数是怎么向 storage 借用内存的呢?流程如下:
- 计算可从 storage 回收的内存 memoryReclaimableFromStorage,为 storage 当前的空闲内存和之前 storage 从 execution 借走的内存中较大的那个
- 如果 memoryReclaimableFromStorage 为 0,说明之前 storage 没有从 execution 这边借用过内存并且 storage 自己已经把内存用完了,没有任何内存可以借给 execution,那么本次借用就失败,直接返回;如果 memoryReclaimableFromStorage 大于 0,则进入下一步
- 计算本次真正要借用的内存 spaceToReclaim,即 execution 不足的内存(申请的内存减去 execution 的空闲内存)与 memoryReclaimableFromStorage 中的较小值。原则是即使能借更多,也只借够用的就行
- 执行借用操作,如果需要 storage 的空闲内存和之前 storage 从 execution 借用的的内存加起来才能满足,则会进行踢除 cached blocks
以上就是整个 execution 向 storage 借用内存的过程,与 storage 向 execution 借用最大的不同是:execution 会踢除 storage 已经使用的向 execution 的内存,踢除的流程在文章的前面有描述。这是因为,这本来就是属于 execution 的内存并且通过踢除来实现归还实现上也不复杂
一个 task 能使用多少 execution 内存?
也就是流程图中的 maxMemoryPerTask 和 minMemoryPerTask 是如何计算的,如下:
val maxPoolSize = computeMaxExecutionPoolSize()
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
maxPoolSize 为从 storage 借用了内存后,executionMemoryPool 的最大可用内存,maxMemoryPerTask 和 minMemoryPerTask 的计算方式也如代码所示。这样做是为了使得每个 task 使用的内存都能维持在 1/2*numActiveTasks ~ 1/numActiveTasks 范围内,使得在整体上能保持各个 task 资源占用比较均衡并且一定程度上允许需要更多资源的 task 在一定范围内能分配到更多资源,也照顾到了个性化的需求
最后到底分配多少 execution 内存?
首先要计算两个值:
- 最大可以分配多少,即 maxToGrant:是申请的内存量与
(maxMemoryPerTask-已为该 task 分配的内存值)中的较小值,如果maxMemoryPerTask < 已为该 task 分配的内存值,则直接为 0,也就是之前已经给该 task 分配的够多了 - 本次循环真正可以分配多少,即 toGrant:maxToGrant 与当前 executionMemoryPool 空闲内存(注意是借用后)的较小值
所以,本次最终能分配的量也就是 toGrant,如果 toGrant 加上已经为该 task 分配的内存量之和 还小于 minMemoryPerTask 并且 toGrant 小于申请的量,则就会触发阻塞。否则,分配 toGrant 成功,函数返回。
阻塞释放的条件有两个,如下:
- 有 task 释放了内存:更具体的说是有 task 释放了相同 MemoryMode 的 execution 内存,这时空闲的 execution 内存变多了
- 有新 task 申请了内存:同样,更具体的说是有新 task 申请了相同 MemoryMode 的 execution 内存,这时 numActiveTasks 变大了,minMemoryPerTask 则变小了
用简短的话描述整个过程如下:
- 申请 execution 内存时,会循环不停的尝试,每次尝试都会看是否需要从 storage 中借用或回收之前借给 storage 的内存(这可能会触发踢除 cached blocks),如果需要则进行借用或回收;
- 之后计算本次循环能分配的内存,
- 如果能分配的不够申请的且该 task 累计分配的(包括本次)小于每个 task 应该获得的最小值(1/2*numActiveTasks),则会阻塞,直到有新的 task 申请内存或有 task 释放内存为止,然后进入下一次循环;
- 否则,直接返回本次分配的值
使用建议
首先,建议使用新模式,所以接下来的配置建议都是基于新模式的。
-
spark.memory.fraction:如果 application spill 或踢除 block 发生的频率过高(可通过日志观察),可以适当调大该值,这样 execution 和 storage 的总可用内存变大,能有效减少发生 spill 和踢除 block 的频率 -
spark.memory.storageFraction:为 storage 占 storage、execution 内存总和的比例。虽然新方案中 storage 和 execution 之间可以发生内存借用,但总的来说,spark.memory.storageFraction越大,运行过程中,storage 能用的内存就会越多。所以,如果你的 app 是更吃 storage 内存的,把这个值调大一点;如果是更吃 execution 内存的,把这个值调小一点 -
spark.memory.offHeap.enabled:堆外内存最大的好处就是可以避免 GC,如果你希望使用堆外内存,将该值置为 true 并设置堆外内存的大小,即设置spark.memory.offHeap.size,这是必须的
另外,需要特别注意的是,堆外内存的大小不会算在 executor memory 中,也就是说加入你设置了 --executor memory 10G 和 spark.memory.offHeap.size=10G,那总共可以使用 20G 内存,堆内和堆外分别 10G。
总结&引子
到这里,已经比较笼统的介绍了 Spark 内存管理的 “前世”,也比较细致的介绍了 “今生”。篇幅比较长,但没有一大段一大段的代码,应该还算比较好懂。如果看到这里,希望你多少能有所收获。
然后,请你在大致回顾下这篇文章,有没有觉得缺了点什么?是的,是缺了点东西,所谓 “内存管理” 怎么就没看到具体是怎么分配内存的呢?是怎么使用的堆外内存?storage 和 execution 的堆外内存使用方式会不会不同?execution 和 storage 又是怎么使用堆内内存的呢?以怎么样的数据结构呢?
如果你想搞清楚这些问题,关注公众号并回复 “内存管理下”。
欢迎关注我的微信公众号:FunnyBigData
