Win10配置CUDA10+cuDNN7(pytorch,tensorflow-gpu)记录
电脑:联系M4400,双显卡(集显和独显),开机过程长按F1进入BIOS,在设置显卡那里要选择独显类型(看英文提示选择)
环境:Python 3.6.5,pip方式安装包(使用的是winpython,轻便,Anoconda太大了,安装还特别慢)
CPU:I5 4200U @ 1.6GHz
RAM: 6GB
显卡:GTX GT 730M(Laptop),很老的显卡,2013年出的,显存2G,CUDA核384个
系统:win10 64位
cudnn下载地址(需要注册):https://developer.nvidia.com/rdp/cudnn-archive
cuda9.2下载地址:https://developer.nvidia.com/cuda-92-download-archive
cuda10下载地址:https://developer.nvidia.com/cuda-toolkit
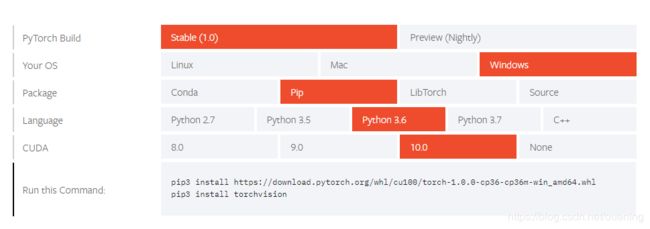
Pytorch安装包(可以单独使用IDM下载whl安装包再pip安装):https://pytorch.org/get-started/locally/
Visual Studio 2015下载地址(在线安装包,需要登陆微软账号):https://my.visualstudio.com/Downloads?q=visual studio 2015&wt.mc_id=omsftvscom~older-downloads
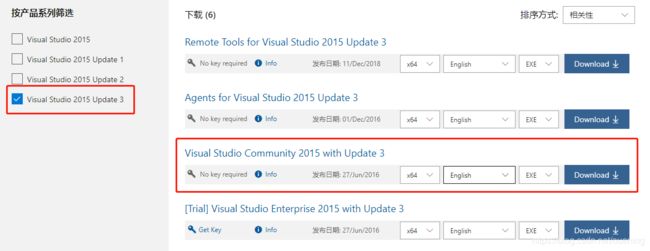
注意事项:网速和耐心!!!特别是安装巨无霸VS2015,可以自己找到安装包安装,使用在线安装受网速限制
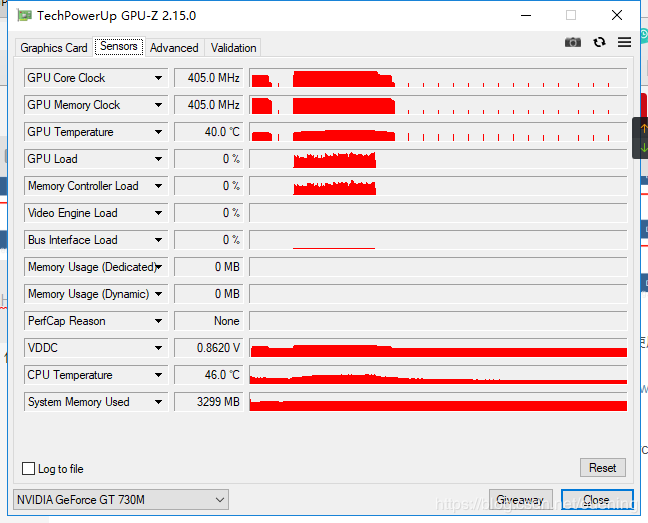
GPU-Z下载地址:查看GPU、CPU状态的有用软件,https://www.techpowerup.com/download/gpu-z/
占用容量:VS2015使用默认方式安装,全部安装完成(VS2015,cuda,cudnn,pytorch,tensorflow等)之后约占12G
下面是安装过程的记录:
1.首先在官网下载了适应本显卡的最新驱动:417.35-notebook-win10-64bit-international-whql.exe,417.35为驱动版本号。
2.安装完之后,桌面右键->NVIDIA控制面板->系统信息->组件,查看NVCUDA.DLL版本,显示是10;(这里说明可以直接下载cuda10安装的)
3.担心显卡太老的原因,下载了cuda_8.0.61.2_windows.exe及补丁cuda_8.0.61_win10.exe,还有cudnn7.1.4;
4.刚想起要安装VS巨无霸套餐Visual Studio 2015(这个版本比较折中,不会太新也不会太老),选择了在线安装版,开始了2小时的漫长安装;安装完VS 2015后继续安装cuda8和cudnn7,安装完cuda8之后发现驱动版本退回376.51了,应该是cuda8自带有相应的驱动,安装过程没有仔细看提示;最后手动添加了bin、lib和include文件夹的环境变量;
3.1 安装tensorflow-gpu,经测试1.5,1.6版本(更高版本更加不行了,看GitHub发布说明的时候1.7版本是最后一个支持cuda8和cudnn6的,不知道为什么这里1.5和1.6版本都报错了)均不能使用cuda8,提示找不到cudart_90.dll,按照错误来看需要cuda9,因为时间关系还没测试cuda9,下面测试了pytorch gpu版本;
3.2 官网下载pytorch1.0 gpu版本,选择stable,windows,pip,Python3.6,cuda8:https://download.pytorch.org/whl/cu80/torch-1.0.0-cp36-cp36m-win_amd64.whl,安装之后执行
import torch
print(torch.cuda.is_available())
如果返回True则可以使用,经测试可以正常使用,训练时用GPU-Z查看显存负载确实有变化。
3.3 安装tensorflow-gpu 1.4版本,安装之后导入,提示需要cudnn6,之前安装的是cudnn7版本,因此重新下载cudnn6,解压后将cuda文件夹下的桑文件夹复制替换到$CUDA安装目录,覆盖原来cudnn7的一些文件
3.4 使用cudnn6覆盖cudnn7之后,pytorch依然可以用,tensorflow可以正常导入,但是执行一些keras程序的时候会报错,因为接口已经发生了变化,1.4版本还是低了。
-
下载
cuda_9.2.148_win10.exe(备用),cuda_10.0.130_411.31_win10.exe,以及cudnn-9.2-windows10-x64-v7.4.1.5.zip(备用),cudnn-10.0-windows10-x64-v7.4.1.5.zip -
安装了
cuda10以及cudnn-10.0-windows10-x64-v7.4.1.5,安装完成后发现右键选项没有了NVIDIA控制面板,暂时无法查看版本号,成功安装了pytorch 1.0 cuda10 GPU版本,torch.cuda.is_available()返回True,说明可以调用gpu计算。
安装tensorflow-gpu 1.12版本,导入时报错:
ImportError: Traceback (most recent call last):
File "c:\applications\wpy-3661\python-3.6.6.amd64\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 58, in
from tensorflow.python.pywrap_tensorflow_internal import *
File "c:\applications\wpy-3661\python-3.6.6.amd64\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 28, in
_pywrap_tensorflow_internal = swig_import_helper()
File "c:\applications\wpy-3661\python-3.6.6.amd64\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
File "c:\applications\wpy-3661\python-3.6.6.amd64\lib\imp.py", line 243, in load_module
return load_dynamic(name, filename, file)
File "c:\applications\wpy-3661\python-3.6.6.amd64\lib\imp.py", line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: 找不到指定的模块。
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/errors
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
- 到此看到这个错误已经不想再折腾
tensorflow-gpu了,谷歌了一下没有查到有用的信息,让我感觉心累。之前实验室win7配置的cuda9(cudnn忘记版本了)最高只能使用tensorflow-gpu 1.6版本,再高版本就会报错。还是pytorch方便,下载安装简洁明了,尽管cuda和cudnn有那么多版本,但是pytorch最这些的兼容性做的很好,比如前面测试的cuda8要配合cudnn6版本时,tensorflow-gpu 1.4版本才能正常运行,但是我用最新的cudnn7.1.4配合cuda8在pytorch下一样可以正常运行,感觉tensorflow-gpu对cuda和cudnn的版本支持太乱了,已经快放弃tensorflow了,但是又需要用keras,真实折腾人。在自己的旧电脑测试的,110G固态硬盘只剩24G了~~~
最后给出莫烦的一个简单测试例子:
# -*- coding: utf-8 -*-
"""
View more, visit my tutorial page: https://morvanzhou.github.io/tutorials/
My Youtube Channel: https://www.youtube.com/user/MorvanZhou
Dependencies:
torch: 1.0
torchvision
"""
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import time
# torch.manual_seed(1)
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = True
#if torch.cuda.is_available():
# USE_CUDA = True
#else:
# USE_CUDA = False
USE_CUDA = False
train_data = torchvision.datasets.MNIST(root='./mnist/',
train=True,
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/',
train=False)
# !!!!!!!! Change in here !!!!!!!!! #
if USE_CUDA:
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
test_y = test_data.targets[:2000].cuda()
else:
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000]/255. # Tensor on GPU
test_y = test_data.targets[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
cnn = CNN()
# !!!!!!!! Change in here !!!!!!!!! #
if USE_CUDA:
cnn.cuda() # Moves all model parameters and buffers to the GPU.
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_func = nn.CrossEntropyLoss()
start = time.clock()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
# !!!!!!!! Change in here !!!!!!!!! #
if USE_CUDA:
b_x = x.cuda() # Tensor on GPU
b_y = y.cuda() # Tensor on GPU
else:
b_x = x
b_y = y
output = cnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
# !!!!!!!! Change in here !!!!!!!!! #
if USE_CUDA:
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
else:
pred_y = torch.max(test_output, 1)[1].data
accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(), '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
print("Time used: {} seconds".format(time.clock()-start))
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
使用CPU计算用时:345.0442833491752 seconds
使用GPU计算用时: 82.08966625165658 seconds