MobileNets的理解
注: 由于所写内容是读了文章之后,然后放在一边,用自己理解的话来写的,可能会与原paper不太一致,甚至可能理解的不对,敬请指正!
读了paper的前面的介绍之后,一个整体的印象是这个network的设计复杂度和计算量都降了不少,而且performance也是不错的,网络的结构也比较的thin,可能这对于做模型压缩是一个启发。
然后个人觉得这个paper的主要想法是做了一个分解,把以前正常的卷积,分解成了两步,并且在paper中作者还给出了具体计算量的公式。
大体的知识体系是这样的。

图a是standard cnn, 假设输入是(D_f,D_f,M)那么和一个(D_k,D_k,M)的kernel“卷积”之后,得到的是(D_f,D_f,1)的,那么和N个kernel作卷积的话得到的就是(D_f, D_f, N )的。
而这篇文章中提出可以作两部作,形象地理解的话,相当于把一个“大矩阵”分解了。
假设输入仍是(D_f, D_f,M)可以把它看成M个(D_f, D_f, 1)的输入粘在一块儿的,那么现在第一步对于这其中的每一个用(D_k,D_k,1)的去做卷积,得到的是(D_f, D_f,1)的,那么用M个的话, 看图b,得到的就是M个,再粘到一块儿的话就是(D_f, D_f, M)大小的,
然后进行第二步,上面得到的(D_f, D_f, M)大小的,和一个(1,1,M)的做“卷积”的话,得到的是(D_f,D_f,1)大小的,
如果和N个去做总面积的话,就得到N个(D_f, D_f,1)这样的,粘到一块儿还是(D_f, D_f, N )形状的,这和standard cnn出来的形状是一致的,但是计算量和复杂度却减少了很多。
具体的可以见下图
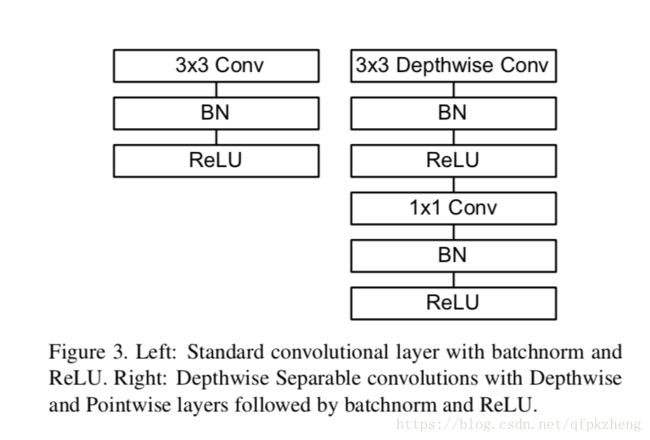
标准的CNN如左图,经过Conv->BN->Relu
而现在调成为, DepthwiseConv(就是第一步)->BN->Relu->1*1 Conv(第二步)->BN->Relu
也就是在BN-Relu之前分别把两步插入其中。
欢迎指正~