当当网高可用架构之道
声明:本文内容来自于TOP100Summit旗下技术沙龙品牌into100沙龙第17期:高可用高并发解决之道,如需转载请联系主办方进行授权。
嘉宾:史海峰,当当架构部总监。2012年加入当当,负责总体架构规划、技术规范制定,善于把握复杂业务需求,提出创新性解决方案,参与重点项目方案设计,对系统架构进行持续改造优化,推动技术革新,组织内外部技术交流。责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
以下为分享整理正文:
系统中的非功能性需求
今天我们的主题是当当高可用架构设计之道,高可用并不是功能性的需求,而是传统的IT当中非功能性需求的一部分。大家可以看到我这里罗列了很多非功能性需求,但是这当中并没有「高可用」这三个字。

举一个例子,比如说你买了一台苹果手机,无论是作为手机还是电脑,还是MP3,还是专门用来看视频的,都是功能;那么非功能性呢,比如说大家很崇拜乔布斯,产品设计极致体验,苹果手机只有1个键,简单好用,这就是一个非功能性需求。另外还有很多朋友买土豪金的手机,就是为了区分开,因为颜色不一样。这个颜色也是非功能性需求。
我们简单介绍几个非功能性需求。
扩展性,有一些类似的可以抽象成统一模型的东西,如果说做好的话就可以支持扩展。用一个以前的例子,我以前是做电信行业的,比如说有一个需求要在全球通上开一个5块钱的套餐,接着又要在动感地带开一个10块钱的套餐,那么我们就可以做成一个模型,做成一个套餐的产品,品牌是一个属性,价格也是一个属性。这样的话,神州行再来一个50块钱的套餐,我们就不需要改什么应用,增加一些配置,定义一些产品属性就可以了,这就是扩展性。
高效率是说你对现有的资源使用是不是足够高效。比如说有的人写的代码比较烂,一启动就百分之几十的CPU使用率,这就不太合理。
可测试,很多开发的同学不当回事,觉得开发好功能逻辑就够了。但是你做出来的东西是要保证质量的。开个玩笑,如果说测试的妹子很漂亮,你愿意手把手的教她如何来测试功能,但要是妹子走了,来了一个糙爷们还需要你还手把手的教,你就不愿意了。因此必须要有一个测试的完整方法、功能说明、测试用例。
这些非功能性的需求,是整个系统是不是正常稳定、可靠运转,以及被一个团队长期沿用下去的一个前提。
而可用性,涉及到很多方面。比如说伸缩性,是否能够在业务量增长的前提之下,通过水平扩展可以很容易支撑更多的业务。比如说安全性、可靠性,数据会不会丢失?所以这里面很多的点,最终都是决定了可用性。
那么可用性是什么呢?可用性就是这套系统最终是给用户用的,是有这些功能的,但是其他方面如果不能保障好,不能N个用户一直用,那你这个系统就无法体现它的价值。这是非常重要的,很多刚刚工作几年的,或者是一直在做产品研发的同学,对这方面没有切身的体会,没有在大晚上被人打电话说出了什么问题你赶紧来处理一下,没有这样切身的痛苦的体会。
「高可用」到底是什么
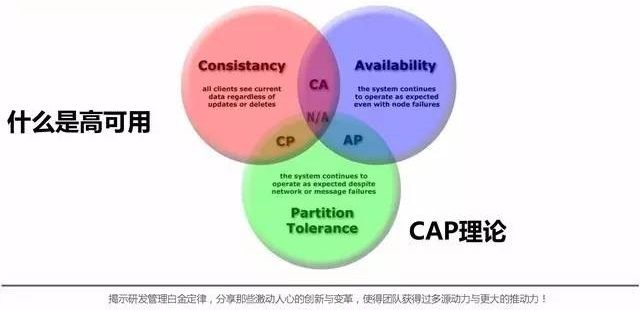
接下来我们说一下什么是高可用。CAP理论是指在分布式数据的场景来形容三者不可兼得,就是一致性、可用性和分区容忍性。在整个系统层面也可以这么理解,因为多数系统的核心就是数据,数据本身受限于这三个特性只能满足两个,不能三个一起满足,整个系统也是如此。
在互联网场景里,因为数据量大分区容忍性是必须要支持的。一致性可以稍微容忍一些,但是可用性是一定要保证的。所以最后多数的互联网公司多数的业务系统就是牺牲一致性,保证可用性和分区容忍性。
我们继续往下看,什么可以影响可用性。

首先是天灾,去年杭州发生了一起「惨案」,支付宝机房的光缆被挖掘机挖断了,这就算是一种天灾了。还有青云的广州机房被雷劈了,这也是一种天灾。以上的情况基本上是不可抗的。

其次是人祸,携程公司去年也发生了「惨案」,系统宕机一下午,一直到晚上才恢复;还有阿里云,去年上了一个云盾的功能,用户在执行可执行文件的时候,就把这个可执行文件给删了,回头用户再找这个可执行文件的时候就找不到了。还有是BUG,在某一些特定场景下系统出问题,这是很正常的。
设计缺陷是要重点说的,它比BUG更宏观一些,是结构上的问题,不是说你增加几个判断,改一下代码就可以解决的。基本上是属于一旦发现了,要么就是大改,要么就是重构,调整原来的设计,很难马上去解决。
至于说性能瓶颈和资源不足,大家知道就是这么多的服务器,如果代码性能写得好,可能能扛住更多请求,如果写得差,可能稍微增长一些就不行了。
性能瓶颈就是短板,比如说负责某个模块是一个没有什么经验的小同学,代码质量不太高,他就可能成为了整个系统的短板,这个模块出了问题,其他的代码写得再好,整个系统还是不能用。

最后还有一些未知的情况。大家做技术做的时间长会遇到很多无法解释的「未解之谜」,我们一般称之为「灵异事件」,这个是指经常发生的,你不知道问题在哪里,但是过段时间就来一次,就好象冥冥之中有人玩你一样,但是总归是可以找到原因解决的。
至于说黑天鹅的事件,则是以前从来没有出现过的情况,突然出现了,让你不知道应该怎么办,而且可能是一两年才出现一次,你会要考虑值不值得找它如何出现的。
还有一些以后就再也不出现了,谁也不知道是怎么回事,你就不知道怎么办了。最后一个是未知的,我们不知道会出现什么样的事情,出现的情况我们也不知道如何应对。科学告诉我们,已知的我们可以去努力解决,但是未知的,我们无法判断。

关于系统故障,有一个海因法则,意思是说出现一起严重的事故,都是由很多的隐患,很多的小问题,或者说一些问题没有暴露出来,最终引发特别大的事故。负责运维的同学都知道,公司对系统的可用性是有指标的,是99.9%还是99.99%,还是99.999%,如果说公司没有这个东西压着你作为KPI,那就太幸运了,出了问题不至于让你拿不到奖金。如果说你的公司有,我希望研发和架构的同学都要清楚,而不是只有运维的同学知道,否则就是公司管理不到位,举个例子如果可用性标准是99.99%,一年系统可以挂的时间是53分钟,99.999%则是5分钟,大家想想就知道,携程挂了一下午,整个可用指标就完不成了,KPI就完成不了。

高可用同时是一个概率的问题。一个复杂的系统,比如说很多模块或者子系统组成的系统,是可以通过一些方式大概去估算的。前些年云计算很火,很多人都说我们有一个云要自动运行,几万台服务器必须要有自动恢复的系统,最好是分钟级恢复,秒级恢复。这些都是一个概率,怎么去算呢?比如说我有两个手机,最近一个月内有3次差一点丢1台手机,这是未遂事件,那么基本上我丢失的概率就确定了,比如说是1/30。我有两个手机的话有什么好处,没有手机用的概率就是1/900。但是丢手机的概率增加了,我就要做好心理准备,没准哪天就会失去一个。
多数系统是几台或者是几十台服务器组成一个小的集群,还有很多跟它平行和上下依赖的系统。这种系统都可以用这种方式去算,大概是什么样的概率。
这个还涉及到容量评估,要考虑系统负载是多少?比如说像我们以前做企业级系统用小型机,小型机的可靠性非常高,平时就是50%左右的负载,这个时候三四台机器加在一起就够用了,因为挂一台基本上系统不会有太大影响。但是如果用不太可靠的PC服务器或者其他解决方式,因为担心可能出现的状况,所以现在很多互联网公司采取的是常年运行10%的CPU或者是20%的CPU状态。
我们可以考虑一个系统,比如说一台机器挂了,影响系统部分出现问题的概率有多高,多个系统总有一天会出问题,如果说系统足够大,大家可以想像,无论是Facebook、谷歌,还是BAT基本上每天都会有各种各样的小问题。所以越复杂的系统越是难以评估,我们要保证出现问题的时候可控。高可用并不是万无一失,我们是用更多出问题的概率去降低整个系统出问题的概率。
还有一个说法叫墨菲定律。基本上你想到的最坏的事情它总会发生的。上学的时候,数学老师会说,小概率事件基本上不会发生。但是在IT,在一个复杂环境当中,在上千台上万台服务器的集群中,几百人几千人做的系统,一定会有一天出问题的。所以人算不如天算,你算出来概率很低,你保证我出问题的概率哪怕是几十万分之一,你觉得这辈子就赶不上了?不见得的。
那么怎么办?就是时刻准备着。这是我做了这么多年开发最大的体会。我们做的是一个7×24小时对外服务的系统,不能停。不能停的概念不是说像有的公司那样,白天有人用,晚上没人用,晚上出事了,我们来得及修补修补。但是像电商是7×24小时的,半夜三四点都有下单的。人家在熬夜开心下单的时候,你出了问题,阻止人家的下单,要不然就是打电话投诉,要不然是找地方吐槽。
系统故障不仅是技术上的问题,最严重的是影响客户体验,前一段时间我们的评论系统出了点小问题:一个客户买了一个面条机,反馈说并不是因为产品本身做不好面条要退货,因为其他原因,这个因为产品已经用过了所以按照规定是不能够退货的。结果用户想评论的时候评论不了,用户就觉得说当点击评论按钮时,系统告知接口错误,觉得这是在针对他,其实这只是系统故障,但是用户并不会这么想。

当你做了各种各样的准备,觉得万无一失了,难免有一天可能还是会翻船了。但是遇到这样的事情也是好事,经验都是在这个时候积累起来的。那么什么是高可用?基本上就是三句话,降低故障出现的概率;缩小故障影响的范围;出现故障快速恢复。不能因为是个小问题就觉得无所谓,反正我一堆的服务器,挂一个就挂一个吧,这种情况不好说会不会另外一个也挂了。因此有问题要尽快处理,最终的目的就是让用户可以正常的使用。
如何设计高可用架构

高可用架构设计常用的「姿势」。大家看到这是一架飞机。我们有一个比喻说做运维这种系统,就是开着飞机修飞机。首先系统一直运行,其次运营、产品各种业务部门会不停提各种各样需求,然后领导也许不懂技术,不懂什么叫分支、什么叫循环、什么叫面向对象;但是懂两个词,一个是敏捷,一个是迭代。
所以做这件事情的时候难度是比较高的。我们不能让这架飞机停下来歇几天,把翅膀换了再飞上去;而是常年在天上飞的,飞上去的时候也许就是个阿帕奇直升机,特别是创业公司。回头要拓展一个业务,增加一些功能,做着做着原来的业务不行了,新的业务变成了主营业务,结果变成了F15,从直升机变成了战斗机,然后变成F16,变成F22。一旦技术团队没有做好,一头栽下去,技术团队的名声就砸了。要么是没做出来,要么是做出来之后一上线挂了,市场费用都白花了,这个责任要技术来承担。
我在四个领域里面分别提炼了几条高可用相关的架构方式。

业务架构就是指产品是什么功能,有什么要求。
- 首先是领域切分,不要把鸡蛋放在一个篮子里,比如说一些传统网站,有非常多的二级域名。某一个二级域名挂了,都是不同的服务器,其他的还可以提供正常的服务。
- 系统分级,哪些系统对用户来说比较重要,级别就会更高,我们就要花更多心思去保障,其他的相对差一些。
- 降低耦合,最近在架构圈当中流行一个词叫康威定律(编者注:Conway’s law: Organizations which design systems […] are constrained to produce designs which are copies of the communication structures of these organizations),是指系统架构是和公司组织架构是有关系的。降低耦合也是如此,不要把系统搞得太复杂,你的组织和团队不要和太多的部门打交道。优化架构,让系统的关系尽可能的简单、明确。这样出现问题范围可控。
- 有损服务是什么意思呢?可以牺牲一些用户体验来保证基本功能的可用。
系统架构当中,分以下几点。
- 第一个是数据独立,不允许跨系统访问数据库这个常识大家都懂,但是很多公司做不好,因为没有强有力的措施去控制。这种事情做起来不太容易,需要管理或者说大家认可才行,但是实际上是非常关键的,因为数据如果不切分,系统很难切分,耦合就非常严重。时间长了出了问题,你连谁写的,谁改的这个数据都不知道,那怎么办?
- 第二点是集群分布,这个就不提了。
- 第三个是冗余部署。比如说电商业务是有波动的,每天的上午11点或者是下午4、5点订单量都会增长,上班族都要休息一下,给自己的辛苦找一些心理安慰,这个时候开始购物。但不能说就这点增长就弹性部署一次。所以一定要有冗余,一般来讲是3-5倍,保证哪怕突然来了一波流量你也可以扛得住。
尤其是电商公司,可能会搞一些促销,可能有的业务部门搞促销的时候,没有知会技术部门,觉得这个促销没什么,可能一两天就搞定了,然后流量预估也就上来200%。但是万一赶上这是网络红人、明星或者是小鲜肉出了书、发了唱片或者穿了什么衣服,一下子成了爆款,系统没扛住,然后运营回头就得抱怨白折腾了。 - 第四个读写分离这个不用说了。
技术架构方面,仔细说一下。要是小公司出了什么问题,几个人碰个头,达成共识就可以了;但是一个上规模的公司,技术团队几百人甚至是上千人的团队,如果技术层面控制不了的话,就会有非常严重的隐患。
- 首先是选择使用的技术平台,有的公司java也有、PHP也有、Python、Go等等的什么都有。
- 其次是人员职能,有的公司说我们的工程师都要做全栈工程师,我们的工程师什么都会。创业团队可以,但是一般成熟的公司都是专业分工,专业分工就来了一个问题,大家毕竟要对接,而且很多东西需要有人持续运维,因此就有必要统一技术标准。
- 第三点就是规范标准,比如说代码、发布的规范都要有。如果说可以沉淀的话,以上说的规范是可以做成一个统一的框架,现在当当也在做一个框架。
- 还有就是合理的选型,一方面不同特性的技术需要用到合适的场景当中。另一方面不合适的技术选型一定要尽量堵住。因为现在很多同学都有非常高涨的学习热情,新技术层出不穷。这样的话很多人会犯一个「锤子心理」的错误。
比如说我最近在当当上买了一本书,花了两个月看完,然后赶上做一个项目,我就觉得自己很懂了,英雄有了用武之地。锤子心理是什么意思呢?他有了一个锤子,看谁都是钉子,就想敲敲。这种情况是要控制的。
也许这个技术不是不能用,但是不是增加系统的负担,公司能不能持续运营。比如招来一个牛人,这个牛人自己写了一个框架,用了什么算法。用起来确实很好,但是过后牛人走了怎么办?出了问题怎么办?谁管?这种问题都是要考虑的。 - 还有就是持续集成。我们要从技术层面去保证多数测试都可以覆盖到,不能说换一个测试或者是换一个开发就经常犯一些重复的低级错误。
基础架构
- 在一个完整的系统当中有一些和业务没有关系的系统,比如运维平台的存在,是为了降低运维的风险,同时也是为了提高效率,保证质量。
- 比如统一监控,那么大一个系统谁知道哪里有问题,哪里不正常,所以必须要统一监控。
- 还有是压测工具,比如双十一,你有没有信心?谁敢说?我们要进行测试,压测之后我们说5倍没问题,10倍没问题。但是不压测谁敢说?
- 还有就是流量控制。常见是分流和限流,如果说有一个页面访问量太大,可以分到类似的页面去,更大的时候我们只能限流。
电商系统架构

这个图是一个比较简单的电商系统架构,主要说说系统分层。最上面的点是展示,包括首页、搜索、列表、活动专题页这些东西,这个展示其实都是用户查询的,没有操作,只要用户可以看就可以了,这些数据是可以缓存,可以静态化的,可以通过这样的方式保证用户访问,可以把数据都缓存起来。比如说当当的首页,是不依赖任何系统的,其他系统都挂了,首页打开是没有问题的,毕竟主站是最大的流量入口。
还有第二点就是交易系统。和订单系统是上下游的关系,交易系统是生成订单的,订单系统是处理订单的。交易系统的订单数据是存在自己的数据库当中。为什么呢?因为好不容易用户来了,终于下单了,一定要留住。订单系统也很复杂,不能说因为订单系统挂了,导致订单无法生成了。所以生成订单这件事情是在交易系统完成的。订单系统可以异步去处理订单,订单系统出了问题,用户该买还是可以买的,这是电商当中非常重要的。
第三个是商品数据中心,就是为了应对前面的这一堆面向用户的访问,我们的数据是单独有一份只读的对外提供,和后面的PIM系统是分开的。PIM是写,这边是读。如果PIM挂了,没有问题。后台系统不会对前台造成太大的影响。

交易系统是最核心的,最大的使命是生成订单。除了基本的生成订单的功能,还可以做什么呢?第一就是要快!比如说促销,这里没有写价格和库存,价格和库存都是敏感数据,要求尽可能准确的,我们都是实时的。但是促销是可以缓存的,因为现在还不是系统智能去调整促销策略的,都是靠人工设置的,节奏和频率都是比较低的,缓存下来之后,基本上是OK的。避免促销服务不稳定对交易产生影响,如果用户点半天没有反应,用户就会走的,要降低依赖。
还有一个交易单缓存,就是订单生成之前的临时数据,要选择支付方式、要写地址、要选择是不是用红包、抵用券、优惠卡这些东西,选得差不多了,万一客户端浏览器崩溃了、网断了或者是闪断、交易系统应用服务器某一个节点挂了,怎么办?这是最重要的时刻,都已经临门一脚了,我们是有缓存的,数据量也不是很大,只要他在比较短的时间内打开,填的东西还在,还可以顺畅的往下走。这个也是非常重要的。我记得以前有的网站出了问题,要重新选一遍,那个时候觉得非常郁闷,除非这个东西非常需要,否则那就算了。
电商数据模型
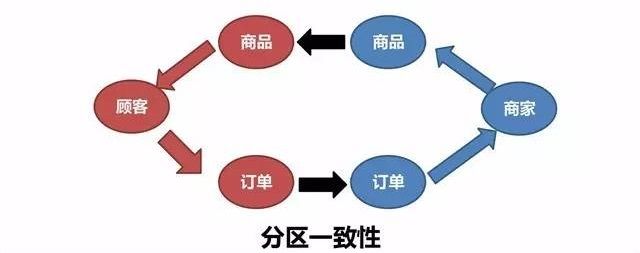
这是电商最常见的数据模型,商家来发布商品、设置促销、价格、库存这些东西。用户来浏览、收藏、加入购物车,最后下单。对于平台电商来说,就会出现多个商家,商品要按照商家来分,订单也要按照商家来分。但是对用户来说,收藏、加购物车的商品还有订单对应的是多个商家。
这个时候有一个非常明确的问题,比如查询收藏列表,或者是商家管理他的商品的时候,怎么样可以很快的处理?商品可能有几千万上亿,肯定不会放在一个数据库里,多个数据库,按什么分?后边按商家分,前边按用户分,中间两套数据库。
说起来逻辑其实挺简单,但是很多创业公司没有琢磨过这个事,中间就是一个库,上面设一个索引,数据量小还没有问题,一旦大了怎么办?觉得这是解决不了的问题。
进一步来说,这只是一个场景,还有一些更具体的场景。比如说我们刚刚提到购物车或者是收藏夹,如果在购物车或者是收藏夹,商品数据不按照用户来分,也不按照商家分,就按照商品ID来分,均匀的分布在我们的数据层是不是可行?
这个逻辑在平时也许没有问题,但是电商有一个说法叫爆品,大家可以想像一下,平时是没有问题的,正常下单正常浏览,一旦出现爆品,就会出现热点数据。爆品所在的数据分片会被用户集中浏览,热点问题没有办法解决就是设计缺陷。再怎么分,那一个商品就在一个库当中,你也不能把它一劈两半。就是我刚刚说的,可能突然爆发一下,时间也不长,但是你扛不住,扛不住怎么办?我们一会儿再说。
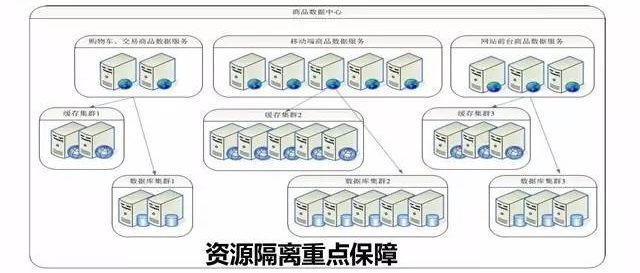
资源隔离重点保障,这也是很重要的。比如商品数据中心给前台提供商品数据,是分成三个集群的。那边的是网站,这边是App,这边是购物车和交易,各自都有自己的缓存和数据库,数据完全一样的。为什么要分开?和刚刚说的一样,首先交易下单是最关键的而且性能要保证,不能受到其他场景的影响。其次移动端也非常重要,大家都是在手机上操作,其实对速度是非常关注的,不能因为网站流量大了,导致手机浏览缓慢,甚至可以挂掉一个集群,其他的还正常,其实就是不要把鸡蛋放到一个篮子里。用空间换时间,用时间换空间。
通过框架来树立开发规范
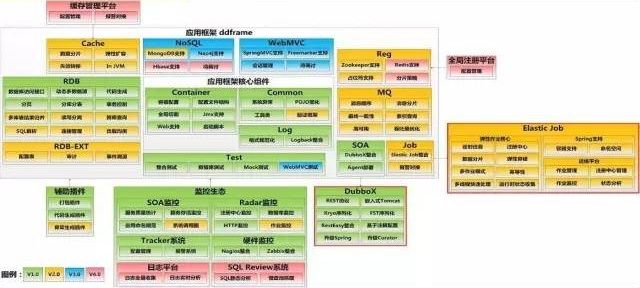
我们做的一个框架叫ddframe,这是我们技术层面想做的事情。很多的互联网公司开发平均工作经验有3年就不错了。因为这几年各种创业公司比较多,膨胀的也很厉害,要找一些有经验的工程师很难。很多开发同学没有经历过各种惨痛教训,开发都是比较随意的,因此我们需要做一个开发的框架去给他们做一些规范的事,能够有效的去帮助他们,尽量不去做一些出格的事情,因此我们做了ddframe。
框架有几个模块:包括最核心的部分、包括和监控的对接、SOA的部分DubboX、还有作业框架elastic-job、以及分布式数据库中间件sharding-JDBC。
Dubbox是我们在Dubbo的层面做了二次开发,现在有不少公司在用,这个部分把一般的服务注册、软负载、路由都搞定了。
elastic-job是分布式作业调度框架。采用分布式作业调度框架前有什么问题呢?第一个是怎么实现避免单点,很多人是这样做的,两台机器都部署,其中一台crontab注释一下,一台机器出问题了,就去另外那台机器上把注释去掉,这是非常低效的,而且是完全靠人的。机器多了怎么办?因此我们需要分布式的作业调度。这是我们去年开发的,最近唯品会在我们的早期版本基础上,自己做了一个内部的作业调度平台,当然也欢迎大家使用。我们为什么自己做,为什么不用TBSchedule,是因为我们发现没有特别合适的,所以自己做。
第二个模块就是RDB,就是分布式数据库问题,和高可用关系不太大,不详细介绍。总体而言,我们是想通过统一的框架、技术组件降低开发人员实现的复杂度,减少风险,不给他们找麻烦。
有了框架就有了工具,有了工具就有了共同的语言。大家可以回想一下历史课,秦始皇统一六国之后做了什么,统一度量衡、钱币、文字。有了这些统一的东西,大家互相之间比较容易交流、积累经验,如果说某个团队比较闲了,也可以支持别的团队,有人在某个团队腻了,可以去其他的团队。
运维与监控

原来我们有一个运维平台,但是去年技术圈出现了那么多的各种事件,运维经理说运维太重要也太危险了,因此我们做了一个强制的生产环境灰度发布,不允许你一键发布,给大家一个缓冲。自动备份也是非常重要的,如果说你发现灰度发布第一个节点就报错了,你要做的事情就是回滚。

接下来是监控。监控是一个很大的系统,非常的重要。一个好的监控系统可能更牛,因为就算是24小时都有运维的同学,但是运维同学也有打盹的时候,或者是没注意。经常我们会在电影当中看到,某一个大盗进入到某一个大厦当中,保安就在那里喝个茶什么的,保安没看到。这种事情是经常会有的。
而且有了监控就有了数据,监控不一定触发报警,但是你有了数据之后可以看趋势。比如说最重要的一点–预算。我们今年要采购多少台服务器,多数是拍脑袋拍出来的,业务说我们今年业务量增加30%,我们多采购30%的服务器,就是这么拍脑袋拍出来的,其实这个是不准确的。
如果系统在某些场景下有严重的性能衰竭,需要去评估,或者要去看,不同的业务模式会对系统造成不同的压力。比如有的系统今年负载反而下降了,就往下减服务器。有的可能增加200%,原来10%的负载,现在变成了30%了,那么这种,哪怕你的业务增长30%,这个压力还是增长200%。这是什么概念?之前是10%到30%,现在就是30%到90%了。你只有有了这些数据,才可以合理的去估算。
大促或者出现爆品时怎么办
相信在上海的同学也都遇到过这样的情况。在地铁站,高峰时限流,用栏杆把人挡住。限流基本上是电商标配,以前没有,所以动不动就挂了。现在成熟了,如果出现了爆品,出现了热点数据怎么办?
你不能说流量一来你就挂了,这个时候限流就非常重要了。举例来说可以扛得住8000,8000以外的就拦住,不让进来。比如淘宝去年双十一零点之后的几分钟,有人手机淘宝进不去,或者是支付宝支付不了,就在朋友圈里发截图说淘宝又挂了,但是没有多少人回应,因为多数人是可以使用的,他刚好倒霉,是被限流了。有了限流今天来10倍就10倍,来20倍没有办法,但是系统扛得住,把其他的流量扔了,保证了基本的收入。
那么最后我们该做的事情都做了,还能怎么办呢?就只能求佛祖保佑了。这种时候有信仰也许会对你的系统可用性指标有点帮助。不管有没有用,我们可以努力一下,在自己的代码注释当中放上一个佛祖保佑一下。
编辑推荐:架构技术实践系列文章(部分):
- 黄哲铿:应对电商大促峰值的九个方法
- 1号店交易系统架构如何向「高并发高可用」演进
- 从C10K到C10M高性能网络的探索与实践
- 服务化架构的演进与实践
- 1号店架构师王富平:一号店用户画像系统实践
- 唯品会官华:实现电商平台从业务到架构的治理体系
- 沈剑:58同城数据库架构最佳实践
- 荔枝FM架构师刘耀华:异地多活IDC机房架构
- UPYUN的云CDN技术架构演进之路
- 初页CTO丁乐:分布式以后还能敏捷吗?
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构