Hive专题八---Hive函数--自定义函数UDF
版权声明:本文为博主原创文章,转载请注明出处。
交流QQ: 824203453
欢迎访问博主个人主页:http://www.oldsheep.cn
hive函数使用
系统自带的函数
1)查看系统自带的函数
hive> show functions;2)显示自带的函数的用法
hive> desc function upper;3)详细显示自带的函数的用法
hive> desc function extended upper;
测试函数小技巧:
直接用常量来测试函数即可
select substr("abcdefg",1,3);而且,可以将hive的本地运行自动模式开启:
hive>set hive.exec.mode.local.auto=true;
HIVE 的所有函数手册:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inTable-GeneratingFunctions(UDTF)
转换函数
类型转select cast("5" as int) ;
select cast("2017-08-03" as date) ;
select cast(current_timestamp as date);| 1 |
1995-05-05 13:30:59 |
1200.3 |
| 2 |
1994-04-05 13:30:59 |
2200 |
| 3 |
1996-06-01 12:20:30 |
80000.5 |
create table t_fun(id string,birthday string,salary string)
row format delimited fields terminated by ',';查询:
select id,cast(birthday as date) as bir,cast(salary as float) from t_fun;
数学运算函数
select round(5.4); ## 5 四舍五入
select round(5.1345,3) ; ##5.135
select ceil(5.4) ; // select ceiling(5.4) ; ## 6 向上取整
select floor(5.4); ## 5 向下取整
select abs(-5.4) ; ## 5.4 绝对值
select greatest(id1,id2,id3) ; ## 6 单行函数
select least(3,5,6) ; ##求多个输入参数中的最小值
示例:
有表如下:

select greatest(cast(s1 as double),cast(s2 as double),cast(s3 as double)) from t_fun2;结果:
+---------+--+
| _c0 |
+---------+--+
| 2000.0 |
| 9800.0 |
+---------+--+
select max(age) from t_person group by ..; 分组聚合函数
select min(age) from t_person group by...; 分组聚合函数
字符串函数
substr(string str, int start) ## 截取子串
substring(string str, int start)
示例:
select substr("abcdefg",2) ;substr(string, int start, int len)
substring(string, int start, int len)
示例:
select substr("abcdefg",2,3) ; ## bcd
concat(string A, string B...) ## 拼接字符串
concat_ws(string SEP, string A, string B...)
示例:
select concat("ab","xy") ; ## abxy
select concat_ws(".","192","168","33","44") ; ## 192.168.33.44
length(string A)
示例:
select length("192.168.33.44"); ## 13
split(string str, string pat) ## 切分字符串,返回数组
示例:select split("192.168.33.44",".") ; 错误的,因为.号是正则语法中的特定字符
select split("192.168.33.44","\\.") ;upper(string str) ##转大写
lower(string str) ##转小写
时间函数
select current_timestamp; ## 返回值类型:timestamp,获取当前的时间戳(详细时间信息)
select current_date; ## 返回值类型:date,获取当前的日期
## 字符串格式转unix时间戳——unix_timestamp:返回值是一个长整数类型
## 如果不带参数,取当前时间的秒数时间戳long--(距离格林威治时间1970-1-1 0:0:0秒的差距)
select unix_timestamp();
unix_timestamp(string date, string pattern)
示例:
select unix_timestamp("2017-08-10 17:50:30");
select unix_timestamp("2017-08-10 17:50:30","yyyy-MM-dd HH:mm:ss");## unix时间戳转字符串格式——from_unixtime
from_unixtime(bigint unixtime[, string format])
示例:
select from_unixtime(unix_timestamp());
select from_unixtime(unix_timestamp(),"yyyy/MM/dd HH:mm:ss");
## 将字符串转成日期date
select to_date("2017-09-17 16:58:32");求年:
select year("2017-09-17 16:58:32");求月份:
select month("2017-09-17 16:58:32");hive (test) > select datediff("2018-10-10","2018-10-01");
OK
_c0
9
Time taken: 0.056 seconds, Fetched: 1 row(s)
hive (test)> select date_add("2018-10-10",3);
OK
_c0
2018-10-13
时间函数大全:
select
current_date,
current_timestamp,
unix_timestamp(current_timestamp),
unix_timestamp(current_timestamp,'yyyy-MM-dd'),
from_unixtime(1550545559,'yyyy-MM-dd hh'),
from_unixtime(1550545559,'yyyy-MM-dd hh:mm:ss'),
year(current_timestamp),
month(current_timestamp),
day(current_timestamp),
weekofyear(current_timestamp),
dayofmonth(current_timestamp),
hour(current_timestamp),
minute(current_timestamp),
second(current_timestamp),
date_add(current_date,1),
date_add(current_date,-1),
add_months(current_date,1),
add_months(current_date,-1),
last_Day(current_date),
next_Day(current_date ,'TU'),
date_add(current_date,-1),
datediff(current_date,'2019-03-08')
条件控制函数
IF
select id,if(age>25,'working','worked') from t_user;
select moive_name,if(array_contains(actors,'吴刚'),'好电影',’烂片儿’) from t_movie;
case when
语法:
CASE [ expression ]
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionn THEN resultn
ELSE result
ENDcase when有两种用法:简单匹配和条件匹配:
简单匹配
case 字段 when 值1 then 返回值1
when 值2 then 返回值2
else 返回值3
end as 别名
条件匹配
case when 表达式1 then 返回值1
when 表达式2 then 返回值2
else 返回值3
end as 别名
有如下数据:
1,zhangsan,18,beijing,20000
2,lisi,28,shanghai,1500
3,wangwu,38,wuhan,4000
4,zhaoliu,35,changsha,10050
5,tianqi,23,shijiazhuang,30000
6,wangba,45,qinhuangdao,28000
7,wushuai,55,haerbin,80000
查询:
把年龄和收入都用阶段表示
年龄 ----> 少年/中年等
收入 -----> 屌丝/还行/oldsheep/土豪
建表:
create table t10(id int,name string,age int,addr string,income int)
row format delimited fields terminated by ',';
查询:
select id,name,
case
when age<=20 then '少年'
when age>20 and age<=40 then '青年'
when age>40 and age<=60 then '中年'
when age>60 then '老年'
end as status,
addr,
income,
case
when income<=5000 then '穷屌丝'
when income>5000 and income<=15000 then '富屌丝'
when income>15000 and income<=30000 then '还行'
when income>30000 and income<=60000 then 'oldsheep'
when income>60000 then '土豪'
end as level
from t10;
结果:
| +-----+-----------+---------+---------------+---------+--------+--+ | id | name | status | addr | income | level | +-----+-----------+---------+---------------+---------+--------+--+ | 1 | zhangsan | 少年 | beijing | 20000 | 还行 | | 2 | lisi | 青年 | shanghai | 1500 | 穷屌丝 | | 3 | wangwu | 青年 | wuhan | 4000 | 穷屌丝 | | 4 | zhaoliu | 青年 | changsha | 10050 | 富屌丝 | | 5 | tianqi | 青年 | shijiazhuang | 30000 | 还行 | | 6 | wangba | 中年 | qinhuangdao | 28000 | 还行 | | 7 | wushuai | 中年 | haerbin | 80000 | 土豪 | +-----+-----------+---------+---------------+---------+--------+--+ |
集合函数
array(3,5,8,9) 构造一个整数数组
array(‘hello’,’moto’,’semense’,’chuizi’,’xiaolajiao’) 构造一个字符串数组
array_contains(Array
示例:
select moive_name,array_contains(actors,'吴刚') from t_movie;
select array_contains(array('a','b','c'),'c') ;
sort_array(Array
示例:
select sort_array(array('c','b','a')) ;
select 'haha',sort_array(array('c','b','a')) as xx from (select 0) tmp;
size(Array
示例:
select moive_name,size(actors) as actor_number from t_movie;
size(Map
size(array
map_keys(Map
map_values(Map
常见分组聚合函数
sum(字段) : 求这个字段在一个组中的所有值的和
avg(字段) : 求这个字段在一个组中的所有值的平均值
max(字段) :求这个字段在一个组中的所有值的最大值
min(字段) :求这个字段在一个组中的所有值的最小值
count():求一个组中的满足某条件的数据条数!
举例说明:
1,mary,female,jiuye
2,tom,male,meijiuye
3,kitty,female,meijiuye
4,white,male,jiuye
5,jack,male,jiuye
6,rose,female,meijiuye
建表语句:
create table t_count(id int,name string,gender string,job string)
row format delimited fields terminated by ',';
请求出,男生和女生中分别已就业的人数
方式1 :在count计数时进行判断是否需要计入
select sex,count(if(job='jiuye',1,null))
from t11
group by sex;
方式3:在count计数时判断是否需要计入:
select sex,count(case when job='jiuye' then 1 else null end)
from t11
group by sex;
方式3:先过滤掉不需要计入的数据,再分组计数
select sex,count(1)
from
(
select *
from t11
where job='jiuye') o1
group by o1.sex;
collect_set() :将某个字段在一组中的所有值形成一个集合(数组)返回
举例:
有数据如下:
1,zhangsan,数学
1,zhangsan,化学
1,zhangsan,语文
1,zhangsan,搭讪学
2,lisi,数学
2,lisi,化学
2,lisi,聊骚
2,lisi,成人搏斗学
3,wangwu,防狼术
3,wangwu,跆拳道需求:
查询出如下结果:
| 1 |
zhangsan |
数学 化学 语文 搭讪学 |
| 2 |
lisi |
数学 化学 聊骚 |
| ..... |
.... |
.... |
创建表:
create table t13(id int,name string,subject string)
row format delimited fields terminated by ',';
加载数据:
load data local inpath '/root/hivedata/collectset.dat' into table t13;
select id,name,collect_set(subject)
from t13
group by id,name;查询结果如下:
| +-----+-----------+------------------------------------------------------------+--+ | id | name | _c2 | +-----+-----------+--------------------------------------------------------------+--+ | 1 | zhangsan | ["数学","化学","语文","街头搭讪学"] | | 2 | lisi | ["数学","化学","聊骚","成人搏斗学"] | | 3 | wangwu | ["防狼术","跆拳道"] | +-----+-----------+----------------------------------------------------------------+--+ |
disctinct
数据:
1,zhangsan,28,beijing
1,lisi,29,shanghai
1,wangwu,30,beijing
2,zhaoliu,18,tianjin
2,tianqi,19,shenzhen
3,wangba,21,shenzhen
建表:
create table t_distinct(id int,
name string,
age int,
addr string)
row format delimited fields terminated by ',';
加载数据:
load data local inpath '/root/hivedata/distinct.dat' into table t_distinct;
表生成函数
表生成函数 行转列函数:explode()
假如有以下数据,把所有的学科转换成列数据。
1,zhangsan,化学:物理:数学:语文
2,lisi,化学:数学:生物:生理:卫生
3,wangwu,化学:语文:英语:体育:生物
映射成一张表:
create table t_stu_subject(id int,name string,subjects array)
row format delimited fields terminated by ','
collection items terminated by ':';
加载数据:
load data local inpath '/root/hivedata/explode.dat' into table t_stu_subject;
使用explode()对数组字段“炸裂”
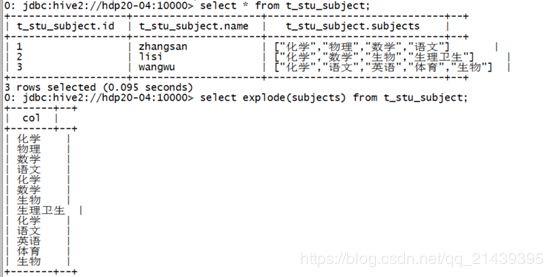
可以利用这个explode的结果,求去重的课程:
select distinct tmp.sub
from
(select explode(subjects) as sub from t_stu_subject) tmp;
表生成函数lateral view
虽然炸裂函数可以使用把行转成列了,但是生成的结果数据中不能包含原有的id,name字段。
想实现原样恢复的结果(结果如下图所示),可以使用lateral view来实现。

select id,name,tmp.sub
from t_stu_subject lateral view explode(subjects) tmp as sub;查询结果:
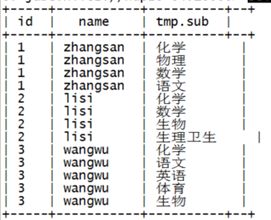
理解: lateral view 相当于两个表在join
左表:是原表
右表:是explode(某个集合字段)之后产生的表
而且:这个join只在同一行的数据间进行
如此,便做更多的查询:
比如,查询选修了生物课的同学
select a.id,a.name,a.sub from
(select id,name,tmp.sub as sub from t_stu_subject lateral view explode(subjects) tmp as sub) a
where sub='生物';
json解析函数
需求:有如下json格式的电影评分数据:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
需要做各种统计分析。
发现,直接对json做sql查询不方便,需要将json数据解析成普通的结构化数据表。可以采用hive中内置的json_tuple()函数
实现步骤:
- 创建一个原始表用来对应原始的json数据
create table t_json(json string);
注意: json数据不需要切分,所以不需要指定分隔符。
加载数据:
load data local inpath '/root/hivedata/ratings.data' into table t_json;
- 利用json_tuple进行json数据解析
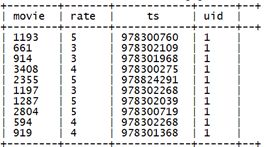
测试,示例:
select json_tuple(json,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid) from t_json limit 10;产生结果:
窗口分析函数:
row_number() over()
语法: row_number()为数据加行号。 over中写划分窗口的条件,比如怎么分组怎么排序等。
需求:需要查询出每种性别中年龄最大的2条数据
数据如下:
1,18,a,male
2,19,b,male
3,22,c,female
4,16,d,female
5,30,e,renyao
6,26,f,female
7,16,d,renyao
8,30,e,renyao
9,26,f,female
10,14,b,male
创建表:
create table t_rn(id int,age int,name string,sex string)
row format delimited fields terminated by ',';
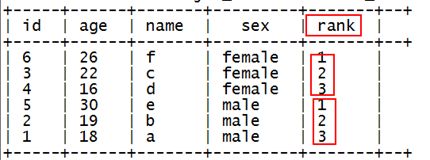
使用row_number函数,对表中的数据按照性别分组,按照年龄倒序排序并进行标记
hql代码:
select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank from t_rownumber;产生结果:
然后,利用上面的结果,查询出rank<=2的即为最终需求
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber) tmp
where rank<=2;sum() over()
sum over常用于 级联求和
语法: sum(求和的字段) over (窗口的生成的条件,及行的起始位置)
需求:
有一张每个店铺的销量纪录表。
数据字段为:店铺名称,月份,销售额。
a,01,10
a,01,20
a,02,100要求 统计每一个店铺的月份总销量,及累积到当前月份的总销量。
实现:使用sum()over()窗口分析函数来实现
步骤1:先求出每家店铺每个月的总金额
create table t_tmp as
select name,month,sum(sale) as amt from shop group by name,month;+-------+--------+-------+--+
| name | month | amt |
+-------+--------+-------+--+
| a | 01 | 350 |
| a | 02 | 5000 |
| a | 03 | 600 |
| b | 01 | 7800 |
| b | 02 | 2500 |
| c | 01 | 470 |
| c | 02 | 630 |
+-------+--------+-------+--+
步骤2:实现级联求和
select name,month,amt,
sum(amt) over(partition by name order by month rows between unbounded preceding and current row) as accumulate
from t_tmp;sum over中的 累加的语法格式:
| 重要提示 |
sum()over()的累加范围指定语法:
sum() over(partition by x order by y rows between 8 preceding and current row) sum() over(partition by x order by y rows between 8 preceding and 5 following) sum() over(partition by x order by y rows between unbounded preceding and 5 following) sum() over(partition by x order by y rows between unbounded preceding and unbounded following) |
sum over需要指定累加的范围,起始行 和终止行的位置。
起始位置和终止位置:
窗口内的第一行:unbounded preceding
窗口内当前行的前3行:3 preceding
当前行: current row
窗口中的最后一行 unbounded following
当前行的下一行 1 following
自定义函数
1)Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如lateral view explore()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
需求:
有如下数据:
id,salay,bonus,subsidy
a,100,50,120
b,220,150,20
c,220,450,2203个字段分别表示: 用户id,基本工资,业绩提成,股权收益
需要查询出每个人的三类收益中最高的是哪一种收益。
求的不是最高收益,而是最高收益的类型。
a,100,50,120,subsidy
b,220,150,20,salary
c,220,450,220,bonushive中有一个函数greatest(f1,f2,f3)可以求出n个字段中的最大值,但满足不了本案例的需求。此时,我们可以考虑自己开发一个hive的函数(hive具备这个机制)
创建表:
create table t19(id int, salary int,bonus int,subsidy int)
row format delimited fields terminated by ',';
通过需求分析,如果有如下函数:
select id,f_c(salary,bonus,subsidy) from t19
f_c(salary,bonus,subsidy) :能够接收3个整数,返回哪一个是最大的,就很容易实现需求;
可惜这样的函数在hive中没有;
解决方案:自定义一个这样的函数;
实现思路:
hive的函数无非也就是一个逻辑的封装,可以接收参数,返回结果,跟java中的方法本质上没有区别。
hive就允许用户开发一个java的方法,来实现你想要的函数的功能;
然后在hive中定义一个自己命名的函数,并将这个函数跟你的java方法所在的类关联起来即可。
实现的流程:
- 创建javase 工程
- 导入hive的依赖jar包
- 自定义类 ,继承父类UDF 重写方法
- evaluate方法的业务逻辑实现
- 打成jar包,提交到hive运行的环境中
- 注册临时函数
- 使用注册的函数查询
实现步骤:
- 创建java工程,
- 导入hive的所有的java包
3,开发一个java类继承(HIVE的父类UDF),重载一个方法: evaluate()
方法的功能:
输入:3个整数值
返回:最大值所在的序号(然后使用case when来进行匹配)
public class HighestIncomType extends UDF{
// 重载evaluate方法,而且必须是public
public int evaluate(int a,int b,int c) {
// 最简单的一行代码
return (a >b && a> c)?0:(b>c ? 1:2);
}
}
4, 将java工程打成jar包,上传到hive所在的机器上
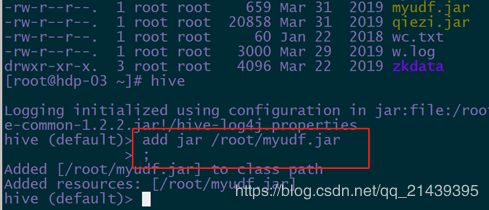
5, 在hive的提示符中,将jar包添加到hive的运行时classpath
6, 注册临时函数
在hive的提示中,用hive语法声明一个自定义函数,并与jar包中的java类关联
hive (default)> add jar /root/myudf.jar ;
Added [/root/myudf.jar] to class path
Added resources: [/root/myudf.jar]
hive (default)> create temporary function f_c as 'cn.huige.hiveudf.MyUDF';
OK
Time taken: 0.7 seconds
7. 就可以在sql查询中使用这个临时函数了
select id,
case
when type=0 then '基本工资'
when type=1 then '股权收益'
else '津贴'
end as type
from
(select id,f_c(salary,bonus,subsidy) as type from t19) o1;
自定义函数永久生效
上述创建的函数是临时生效的,当hive窗口退出之后,函数就不能使用了。
如果需要创建的函数是永久生效的。就需要做一些其他的配置。
- 把自定义函数的jar包,放到hive的lib目录下。
[root@hdp-03 ~]# cp myudf.jar apps/apache-hive-1.2.2-bin/lib/- 注册永久的函数
hive (default)> create function f_c as 'cn.huige.hiveudf.MyUDF';
版权声明:本文为博主原创文章,转载请注明出处。
交流QQ: 824203453
欢迎访问博主个人主页:http://www.oldsheep.cn