Flink 读取hive,写入hive
1,读取实现了,也是找的资料,核心就是实现了
HCatInputFormat
HCatInputFormatBase
上面这两个类,底层也是 继承实现了 RichInputFormat:
public abstract class HCatInputFormatBase extends RichInputFormat implements ResultTypeQueryabl 百度下载这个jar,然后把类找出来
![]()
依赖:(大概是这些)
org.apache.flink
flink-hadoop-fs
1.6.2
com.jolbox
bonecp
0.8.0.RELEASE
com.twitter
parquet-hive-bundle
1.6.0
org.apache.hive
hive-exec
2.1.0
org.apache.hive
hive-metastore
2.1.0
org.apache.hive
hive-cli
2.1.0
org.apache.hive
hive-common
2.1.0
org.apache.hive
hive-service
2.1.0
org.apache.hive
hive-shims
2.1.0
org.apache.hive.hcatalog
hive-hcatalog-core
2.1.0
org.apache.thrift
libfb303
0.9.3
pom
org.apache.flink
flink-hadoop-compatibility_2.11
1.6.2
org.apache.flink
flink-shaded-hadoop2
1.6.2
package com.coder.flink.core.FlinkHive
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.hadoop.conf.Configuration
import org.apache.flink.api.scala._
//读取hive的数据
object ReadHive {
def main(args: Array[String]): Unit = {
val conf = new Configuration()
conf.set("hive.metastore.local", "false")
conf.set("hive.metastore.uris", "thrift://172.10.4.141:9083")
//如果是高可用 就需要是nameserver
// conf.set("hive.metastore.uris", "thrift://172.10.4.142:9083")
val env = ExecutionEnvironment.getExecutionEnvironment
//todo 返回类型
val dataset: DataSet[TamAlert] = env.createInput(new HCatInputFormat[TamAlert]("aijiami", "test", conf))
dataset.first(10).print()
// env.execute("flink hive test")
}
}
2,写入正在研究,要继承实现 RichInputFormat,不过Flink 有一个
具体不知道方法怎么实现。。。。。。等有时间再搞搞。
API地址:https://hive.apache.org/javadocs/r2.1.1/api/org/apache/hadoop/hive/ql/io/HiveOutputFormat.html
核心要实现接口:
https://www.cnblogs.com/frankdeng/p/9256215.html (参考)
https://www.coder4.com/archives/4031 (参考)
可是不知道输入的[K,V] 是什么格式......
好消息是 Flink 1.9支持了Hive读写接口
不过我们可以用Hive Jdbc的方式去读写hive,可能就是性能会比较慢:
需要导入
org.apache.hive
hive-jdbc
2.1.0
参考:https://www.cnblogs.com/guotianqi/p/8057740.html
package com.coder.flink.core.FlinkHive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.*;
public class FlinkReadHive {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection con = DriverManager.getConnection("jdbc:hive2://172.10.4.143:10000/aijiami","hive","hive");
Statement st = con.createStatement();
ResultSet rs = st.executeQuery("SELECT * from ods_scenes_detail_new limit 10");
while (rs.next()){
System.out.println(rs.getString(1) + "," + rs.getString(2));
}
rs.close();
st.close();
con.close();
}
}
通过load方式写入hive:
https://blog.csdn.net/haohaixingyun/article/details/57090626 (参考)
public class HiveApp {
private static String driver = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://Master:10000/default";
private static String user = "root"; //一般情况下可以使用匿名的方式,在这里使用了root是因为整个Hive的所有安装等操作都是root
private static String password = "";
public static void main(String[] args) {
ResultSet res = null;
try {
/**
* 第一步:把JDBC驱动通过反射的方式加载进来
*/
Class.forName(driver);
/**
* 第二步:通过JDBC建立和Hive的连接器,默认端口是10000,默认用户名和密码都为空
*/
Connection conn = DriverManager.getConnection(url, user, password);
/**
* 第三步:创建Statement句柄,基于该句柄进行SQL的各种操作;
*/
Statement stmt = conn.createStatement();
/**
* 接下来就是SQL的各种操作;
* 第4.1步骤:建表Table,如果已经存在的话就要首先删除;
*/
String tableName = "testHiveDriverTable";
stmt.execute("drop table if exists " + tableName );
stmt.execute("create table " + tableName + " (id int, name string)" + "ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'");
/**
* 第4.2步骤:查询建立的Table;
*/
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
/**
* 第4.3步骤:查询建立的Table的schema;
*/
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
/**
* 第4.4步骤:加载数据进入Hive中的Table;
*/
String filepath = "/root/Documents/data/sql/testHiveDriver.txt";
sql = "load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
stmt.execute(sql);
/**
* 第4.5步骤:查询进入Hive中的Table的数据;
*/
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
}
/**
* 第4.6步骤:Hive中的对Table进行统计操作;
*/
sql = "select count(1) from " + tableName; //在执行select count(*) 时候会生成mapreduce 操作 ,那么需要启动资源管理器 yarn : start-yarn.sh
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println("Total lines :" + res.getString(1));
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
写入HDFS的简单案例:
package com.coder.flink.core.test_demo
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
import org.apache.flink.core.fs.FileSystem.WriteMode
object WriteToHDFS {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
//2.定义数据 stu(age,name,height)
val stu: DataSet[(Int, String, String)] = env.fromElements(
(19, "zhangsan","aaaa"),
(1449, "zhangsan","aaaa"),
(33, "zhangsan","aaaa"),
(22, "zhangsan","aaaa")
)
//todo 输出到本地
stu.setParallelism(1).writeAsText("file:///C:/Users/Administrator/Desktop/Flink代码/测试数据/test001.txt",
WriteMode.OVERWRITE)
env.execute()
//todo 写入到hdfs,文本文档,路径不存在则自动创建路径。
stu.setParallelism(1).writeAsText("hdfs:///output/flink/datasink/test001.txt",
WriteMode.OVERWRITE)
env.execute()
//todo 写入到hdfs,CSV文档
//3.1读取csv文件
val inPath = "hdfs:///input/flink/sales.csv"
case class Sales(transactionId: String, customerId: Int, itemId: Int, amountPaid: Double)
val ds2 = env.readCsvFile[Sales](
filePath = inPath,
lineDelimiter = "\n",
fieldDelimiter = ",",
lenient = false,
ignoreFirstLine = true,
includedFields = Array(0, 1, 2, 3),
pojoFields = Array("transactionId", "customerId", "itemId", "amountPaid")
)
//3.2将CSV文档写入到hdfs
val outPath = "hdfs:///output/flink/datasink/sales.csv"
ds2.setParallelism(1).writeAsCsv(filePath = outPath, rowDelimiter = "\n",fieldDelimiter = "|", WriteMode.OVERWRITE)
env.execute()
}
}
================更新 最新的Flink 1.9已经支持了hive的读取======================地址:
https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/hive/read_write_hive.html
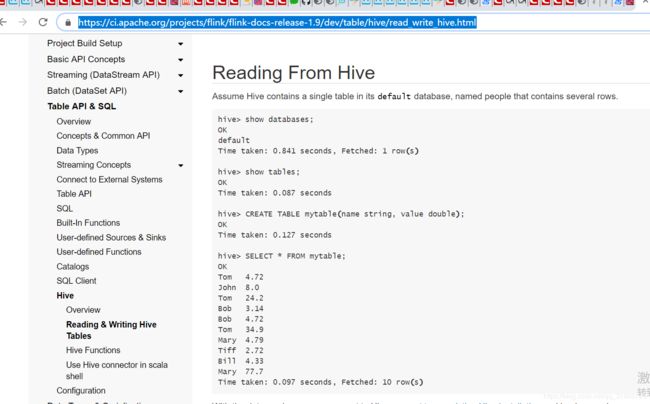

注意hive版本跟依赖:
https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/hive/#depedencies
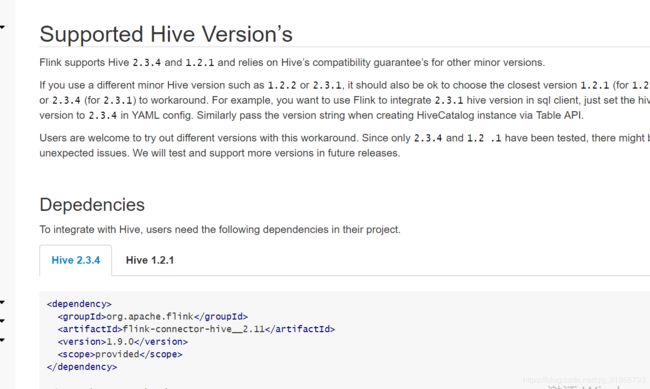
具体代码