Hive总结2(分区+分桶+查询)
Hive是一个数据仓库 ,保存的半结构化数据 文本。
Hive不支持:事务,不支持索引(但可以通过分桶实现快速的查询,hash)
类似的分布的nosql(Not Only Sql数据库:hbase - Phoinex(凤凰)
Hive的功能,就是做mapreduce。
分区:
就是在可控制的情况下,将数据放到不同的目录下。
减小查询的范围。 并不能加快查询的速度。还是要查询所有只是分了一个目录。
Stud.txt > mary=cp 目录下
分桶就是hash存储。Id = > where id=S001
将数据根据hashcode值进行分开保存
查询时对id进行hash得出结果,就知道放到了那个文件下, 提高查询的速度。
用外部表的方式管理,保证元数据不会丢失。
1.分区
通过partition by(字段名 字段类型) - 分区最后会形成一个目录。
分区的字段,不在源数据中出现,但是表的一部分
1.1创建一个分区表
hive> create table stud01(
> id string,
> name string,
> age int
> )
> partitioned by (grade string)
> row format delimited
> fields terminated by '\t';
1.2导入数据
在导入数据时,必须要通过partition提定分区的值:
hive> load data local inpath '${env:HOME}/stud.txt' into table stud01 partition(grade='2009');
1.3查询分区数据
对于分区,可能每一个分区中的数据都非常的多:
分区查询限制:默认情况下,在查询时,可以不用带分区的条件
用户配置:
在用户目录下创建.hiverc值为:
hive.mapred.mode=nonstrict
修改成strict就必须要查询时有分区的条件,修改成nonstrict可以不用写:
hive>select * from stu01 where grade ="2009"
在 Hive-site.xml配置,可以统一使用。
1.4查看分区
hive>show partitions stu01;
1.5创建多级目录
hive> create table stud01(
> id string,
> name string,
> age int
> )
> partitioned by (grade string,major string)
> row format delimited
> fields terminated by '\t';

1.6动态分区
如果使用load导入 数据,则分区的值,是用户硬编码指定,且无法动态。
但是如果从一个表,向另一个表中导入数据,则可以动态的创建分区,但是分区的字段,必须是最后一个字段。
查询是否支持动态的分区:
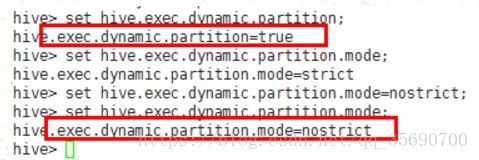
指定动态分区 mm=name;
hive> insert overwrite table stud03 partition(mm) select id,age,grade,major,name from stud02;
2.排序
3种关键字:
Order - 全排,速度比较慢,默认使用一个reducer。
Distribute by (..) 根据指定字段的hash值%reduce个数 放到不同的文件中。
Distribute by (..) sort by(...) 排序,-部分排序(每一个reduce内部排序)。
Cluster by = distrubte + sort (部分排序)
2.1.全排序
hive> insert overwrite local directory '${env:HOME}/out001'
>row format delimited
>fields terminated by '\t'
>select name ,id ,age from stu01 order by (name) asc;
可以指定asc(升序)默认,或是desc(降序)
2.2.部分排序
hive> insert overwrite local directory 'home/keys/out002'
> select * from stud01 distribute by(id) sort by (name);
Cluster by (id) = distribute by(id) sort by(id)
3.分桶
关键字:distributed
3.1创建表
hive> create table stud02(
> id string,
> name string,
> age int
> )
> clustered by (id) into 3 buckets
> row format delimited
> fields terminated by '\t';
3.2查看数据
hive> desc formatted stu002;
3.3导入数据
如果一个表是分桶的,通过load导入的数据,还是不会分桶的。
向一个分桶的表中的保存数据,必须要使用 insert select ...从其他的数据表中查询数据:
hive>insert overweite table stu002 select id,name,age from stu01 cluster by (id);
此时的表既排序又分桶。
4.存储格式
行存储和列存储
数据

行存储:
适合查询所有的数据(快)
类型:textfile,squence,avro(json)
使用:mysql oracle

列存储
适合查询某一列的数据(快)
使用: orcfile,rcfile,parquet,hbase

4.1sequenceFile

导入数据用insert不能用load,load是文件copy不会写成sequenceFile。
4.2avro

查看 文件::$ hdfs dfs -text '目录'
4.3orcfile/rcfile二进制文件
hive> create table stud_orcfile(
> id string,
> name string,
> age int
> )
> stored as orcfile
row format delimited 文本文件,顺序文件需要指定,二进制不需要
4.4parquet
hive> create table stud_parquet(
> id string,
> name string,
> age int
> )
> stored as parquet;
5.view
逻辑表,里面没有数据。不支持load数据。主要功能简化查询,封装查询,权限。
它的数据就来一个查询
hive> create view v1 as select id,name,age from stu01;
show tables 可以显示v1;
对于没有指定别名的列会默认为_c0
hive > create view v2 as select count(1),name from stu01;
查询
hive> select '_c0',name from v2; //注意要加上单引号。不加不通过
hive > create view v2 as select count(1) as cnt,name from stu01;//指定列名
6.连接查询
在hive中执行查询时,有一个建议:
1:越小的表,在前面-进行 缓存
2:大的数据表,在后面进行mapreduce。
hive> select s.id as sid,s.name sname,b.id bid,b.name bname from stud_seq s left outer join books b on(s.id=b.sid);
hive> select s.id as sid,s.name sname,b.id bid,b.name bname from stud_seq s right outer join books b on(s.id=b.sid);
hive> select s.id as sid,s.name sname,b.id bid,b.name bname from stud_seq s full join outer books b on(s.id=b.sid);
7.子查询
只支持非相关子查询,不支持相关子查询。
非相关子查询:子查询可以独立执行的。
相关子查询:子语句不能拿出来被单独执行,有依赖关系。
SELECT * FROM stud WHERE id IN(SELECT sid FROM books GROUP BY sid HAVING COUNT(sid)=0);
SELECT sid FROM books GROUP BY sid HAVING COUNT(sid)=2;
SELECT * FROM stud WHERE (SELECT COUNT(1) FROM books WHERE books.sid=stud.id)=0;
SELECT COUNT(1) FROM books WHERE books.sid=stud.id
8.查看执行计划
通过explain + sql语句查看sql的执行计划
