hive 调优总结
hive调优是比较大的专题,需要结合实际的业务,数据的类型,分布,质量状况等来实际的考虑如何进行系统性的优化,hive底层是mapreduce,所以hadoop调优也是hive调优的一个基础,hvie调优可以分为几个模块进行考虑,数据的压缩与存储,sql的优化,hive参数的优化,解决数据的倾斜等。
一,数据的压缩与存储格式
对分析的数据选择合适的存储格式与压缩方式能提高hive的分析效率:
1)压缩方式
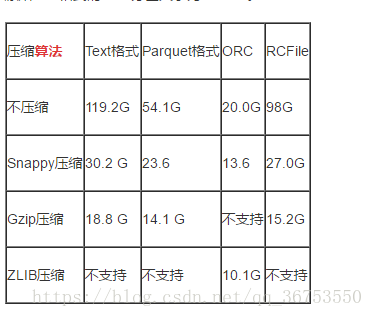
压缩可以节约磁盘的空间,基于文本的压缩率可达40%+; 压缩可以增加吞吐量和性能量(减小载入内存的数据量),但是在压缩和解压过程中会增加CPU的开销。所以针对IO密集型的jobs(非计算密集型)可以使用压缩的方式提高性能。 几种压缩算法:

注意:选择压缩算法的时候需要考虑到是否可以分割,如果不支持分割(切片的时候需要确定一条数据的完整性),则一个map需要执行完一个文件,如果文件很大,则效率很低。一般情况下hdfs一个块(128M)就是一个map的输入切片,而block是按物理切割的,可能一条数据会被切到两个块中去,而mapde 切片如何确保一条数据在一个切片中呢?这就是看压缩算法支不支持分割了,具体的实现机制需要看源码研究。
2)存储格式(行存与列存)

1. TextFile
Hive数据表的默认格式,存储方式:行存储。 可以使用Gzip压缩算法,但压缩后的文件不支持split 在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
2.Sequence Files
Hadoop中有些原生压缩文件的缺点之一就是不支持分割。支持分割的文件可以并行的有多个mapper程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。Sequence File是可分割的文件格式,支持Hadoop的block级压缩。 Hadoop API提供的一种二进制文件,以key-value的形式序列化到文件中。存储方式:行存储。 sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能。 优势是文件和hadoop api中的MapFile是相互兼容的
3. RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低 其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取 数据追加:RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的 HDFS当前仅仅支持数据追加写文件尾部。 行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。
4.ORCFile
存储方式:数据按行分块,每块按照列存储。
压缩快,快速列存取。效率比rcfile高,是rcfile的改良版本。
5.Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间

6、自定义格式
可以自定义文件格式,用户可通过实现InputFormat和OutputFormat来自定义输入输出格式。
压缩与存储格式的选择
mapreduce可以选择压缩的地方:map阶段的输出和reduce阶段的输出。

设置方式:
1. map阶段输出数据压缩 ,在这个阶段,优先选择一个低CPU开销的算法。
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
2.hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。 (也可以在建表的时候进行设置)
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec结论,一般选择orcfile/parquet + snappy 的方式
建表语句:
create table tablename (
xxx,string
xxx, bigint
)
ROW FORMAT DELTMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties("orc.compress" = "SNAPPY")二、创建分区表,桶表,拆分表
1)创建分区表:(分区表相当于hive的索引,加快查询速度)
CREATE external TABLE table_name
(col1 string, col2 double)
partitioned by (date string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' Stored AS TEXTFILE
location ‘xxxxx’;
alter table table_name add partitions(key = value) location 'xxxx' (收到设置分区,静态分区)设置动态分区
set hive.exec.dynamic.partition=true;(可通过这个语句查看:set hive.exec.dynamic.partition;)
set hive.exec.dynamic.partition.mode=nonstrict; (它的默认值是strick,即不允许分区列全部是动态的)
SET hive.exec.max.dynamic.partitions=100000;(如果自动分区数大于这个参数,将会报错)
SET hive.exec.max.dynamic.partitions.pernode=100000;2)创建桶表:
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
create table bucketed_user(id int,name string) clustered by (id)
sorted by(name) into 4 buckets row format delimited fields terminated by '\t'
stored as textfile;
3)拆分表:当你需要对一个很大的表做分析的时候,但不是每个字段都需要用到,可以考虑拆分表,生成子表,减少输入的数据量。并且过滤掉无效的数据,或者合并数据,进一步减少分析的数据量
create table tablename
ROW FORMAT DELTMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties("orc.compress" = "SNAPPY")
as select XXX from XXXX三、hive参数优化
1)fetch task 为执行hive时,不用执行MapReduce,如select * from emp;
Hive.fetch.task.conversion 默认为minimal
修改配置文件hive-site.xml
hive.fetch.task.conversion
more
Some select queries can be converted to single FETCH task
minimizing latency.Currently the query should be single
sourced not having any subquery and should not have
any aggregations or distincts (which incurrs RS),
lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (+TABLESAMPLE, virtual columns)
或者当前session修改
hive> set hive.fetch.task.conversion=more;
执行SELECT id, money FROM m limit 10; 不走mr
2)并行执行
当一个sql中有多个job时候,且这多个job之间没有依赖,则可以让顺序执行变为并行执行(一般为用到union all )
// 开启任务并行执行
set hive.exec.parallel=true;
// 同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number=8;
3)jvm 重用
JVM重用对hive的性能具有非常大的 影响,特别是对于很难避免小文件的场景或者task特别多的场景,这类场景大多数执行时间都很短。jvm的启动过程可能会造成相当大的开销,尤其是执行的job包含有成千上万个task任务的情况。
set mapred.job.reuse.jvm.num.tasks=10; JVM的一个缺点是,开启JVM重用将会一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡“的job中有几个 reduce task 执行的时间要比其他reduce task消耗的时间多得多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
4)设置reduce的数目
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定: hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,在Hive 0.14.0版本之前默认值是1G(1,000,000,000);而从Hive 0.14.0开始,默认值变成了256M(256,000,000) ) hive.exec.reducers.max(每个任务最大的reduce数,在Hive 0.14.0版本之前默认值是999;而从Hive 0.14.0开始,默认值变成了1009 ) 计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1) 即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务;
调整reduce个数方法一: 调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)调整reduce个数方法二;
set mapred.reduce.tasks = numberreduce个数并不是越多越好; 同map一样,启动和初始化reduce也会消耗时间和资源; 另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题 -
5) 推测执行
什么是推测执行?
所谓的推测执行,就是当所有task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的task node机器配置比较低或者CPU load很高(原因很多),导致任务执行比总体任务的平均执行要慢,此时Job Tracker会启动一个新的任务(duplicate task),原有任务和新任务哪个先执行完就把另外一个kill掉
怎么配置推测执行参数?
推测执行需要设置Job的两个参数:
mapred.map.tasks.speculative.execution
mapred.reduce.tasks.speculative.execution
两个参数的默认值均为true.
四、优化sql
(1)where条件优化
优化前(关系数据库不用考虑会自动优化):
select m.cid,u.id from order m join customer u on( m.cid =u.id )where m.dt='20180808';
优化后(where条件在map端执行而不是在reduce端执行):
select m.cid,u.id from (select * from order where dt='20180818') m join customer u on( m.cid =u.id);
(2)union优化
尽量不要使用union (union 去掉重复的记录)而是使用 union all 然后在用group by 去重
(3)count distinct优化
不要使用count (distinct cloumn) ,使用子查询
select count(1) from (select id from tablename group by id) tmp;
(4) 用in 来代替join
如果需要根据一个表的字段来约束另为一个表,尽量用in来代替join .
select id,name from tb1 a join tb2 b on(a.id = b.id);
select id,name from tb1 where id in(select id from tb2); in 要比join 快(5)消灭子查询内的 group by 、 COUNT(DISTINCT),MAX,MIN。 可以减少job的数量。
(6) join 优化:
Common/shuffle/Reduce JOIN 连接发生的阶段,发生在reduce 阶段, 适用于大表 连接 大表(默认的方式)
Map join : 连接发生在map阶段 , 适用于小表 连接 大表
大表的数据从文件中读取
小表的数据存放在内存中(hive中已经自动进行了优化,自动判断小表,然后进行缓存)
set hive.auto.convert.join=true; SMB join
Sort -Merge -Bucket Join 对大表连接大表的优化,用桶表的概念来进行优化。在一个桶内发送生笛卡尔积连接(需要是两个桶表进行join)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
五、数据倾斜
表现:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
原因:某个reduce的数据输入量远远大于其他reduce数据的输入量
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| join | 大表与大表,但是分桶的判断字段0值或空值过多 | 这些空值都由一个reduce处理,非常慢 |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
| count distinct | 某特殊值过多 | 处理此特殊值reduce耗时 |
解决方案:
(1)参数调节
set hive.map.aggr=true
set hive.groupby.skewindata=true
(2) 熟悉数据的分布,优化sql的逻辑,找出数据倾斜的原因。
六、合并小文件
小文件的产生有三个地方,map输入,map输出,reduce输出,小文件过多也会影响hive的分析效率:
设置map输入的小文件合并
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数:
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
七、查看sql的执行计划
explain sql 学会查看sql的执行计划,优化业务逻辑 ,减少job的数据量。
以上为我在工作中的经验和网上查阅资料所整理出来的hive调优,后面会继续补充
八、在脚本中并行
在实际的开发中,我们写好的sql是放到脚本中去跑 hive -f xxx.sql 文件,然后在cron里面设置个定时任务跑,所以可以在脚本中用到并行的跑sql文件,其实是放到后台跑sql文件,sql文件之间是不相关的,且不能用union all 连接起来的sql(如果可以写成一个sql的话设置一下并行执行就可以了)。如:
#!/bin/bash
hive -f aa.sql &
hive -f bb.sql & #(aa和bb里面的sql同时执行)
wait #(等待aa 和 bb 执行完后在 执行 xxx.sql文件)
hive -f xxx.sql