官方原文链接地址
本文只是个人为了整理Lint相关知识,依据谷歌翻译整理而成,水平确实不堪,很多地方自己都读不太懂,见谅...
2014.3.14更新,根据最新版本的lint中添加的新功能,添加了用于java解析的类型解析部分。
本文档简要介绍了编写lint检查,这绝对不是一个完整的教程,但希望在API之上添加一些有用的评论和提示(你可能还需要查看“Writing Custom Lint Rules”文档以获得更多的详细信息和提示)
编写一个lint检查,你将需要:
1. 意识到API不是final类型的,所以准备好可能需要调整代码以适应未来的变化。
2. 通过Lint API项目(lint/libs/lint-api)
3. 通过一些现有的lint检查(lint/libs/lint-checks)来了解如何编写lint检查。现在有80多个检查,所以这是一个你可以适应类似检查很好的机会。
确保使用ADT17代码库;ADT17已经从ADT16发生了很大变化,所以如果您在ADT·6上工作,您将浪费大量的时间。
问题与检查器
请注意,lint区分'问题'和'检查器',问题是您想要查找并显示给用户的一种问题,问题具有相关描述,全面的说明,类别,优先级等。问题是暴露给用户的,例如在eclipse的集成中,您可以打开lint首选项的对话框以查看所有各种问题,并且可以禁用问题和更改指定问题的严重性(例如将问题标记为错误而不是警告,或者您可以将其严重性设置为‘忽略’)
一个问题仅仅是一条数据,这是一个单一的,final类型的问题class,你不要对它进行子类化,你只需要实例化一个新的类型的问题,并用IssueRegistry进行注册。
你想要实现的是一个检测器,检测器负责通过代码扫描来查找条实例并报告它们。请注意,一个检测器可以报告多种类型的问题,这就允许你针对不同类型的问题具备不同的严重性,并且用户对他们想要看到的内容进行更细粒度的控制。
例如,UnusedResourceDetector将搜索项目中的所有资源以及这些资源的所有用法,并报告这些没未使用的资源,检测器报告了两种不同类型的问题,UnusedResources和UnusedIds,有些用户希望保留未使用的'unused'id,因为它们的开销并不多(R文件除外),同时它们在布局文件中提供文档目的等。因此,通过单独的问题,用户可以禁用此问题并仍然寻找其他类型的问题并且UnusedIds的默认情况下禁用)
范围
范围枚举列举了android项目项目中的许多位置
* Resource file
* Java source files
* Class files
* Proguard configuration files
* Manifest files
等. 一个问题将说明分析代码所需的范围,例如,只是在清单文件中查找错误的检查可以简要的说明其范围为Scope.MANIFEST,这是通过lint基础设施使用在多个方面。一方面用于限制它为给定的文件类型调用的检测器的数量;另一方面,它用于支持每个文件的linting;如果你正在Eclipse中编辑某个单独文件,并且按ctrl+S,lint将通过仅对此单个文件做了范围限制的所有检测器来对此文件重新进行分析。
范围参数也影响预期实现的借口(API注意:范围类可能是稍后将要更改的领域之一)
检测器接口
大多数的检测器都是实现一个或者多个以下的接口
* Detector.XmlScanner
* Detector.JavaScanner
* Detector ClassScanner
例如,对于具有范围为{Manifest}的检测器,它将实现XmlScanner接口。
这些扫描接口是接口而不是类,因为它实现了多个检测器是不常见的,以ApiChecker作个例子,它同时实现了 ClassScanner 接口(为了分析API调用的.class文件)和 XmlScanner(为了分析布局文件,因为
扫描xml文件
要分析一个xml文件,你可以只覆盖"visitDocument"方法,它将被调用一次,访问每一个xml文件,传递你的XML DOM模型,然后你自己可以重复和分析你想要分析的那部分。
然而大多数的规则在特定标签,特定属性或一组标签或一组属性或两者的组合中通常很有趣。
为了快速扫描,检测器可以指定其感兴趣的元素和属性。仅仅需要实现getApplicableElements 和/或者 getApplicableAttributes,返回一组字符串标签或者属性名称的列表集合,然后实现visitElement 和/或者 visitAttribute,现在将为每个出现的给定元素和属性调用这些方法。
(这样做的原因是其内部在扫描项目的初期,lint的基础架构会创建一个从标签名称到对其感兴趣的检测器的列表的多重映射,并且对于属性也是类似的。这样,当它分析每一个xml文件的时候,它可以简单的通过模型来进行单词迭代,来查看每个属性和标签是否具有任何对其感兴趣的检测器,并且如果有就分发给它们。这就意味着如果你添加了新的检测器来寻找特定标签名称,那么你不会使每个单独文件检查速度稍慢一些,如果该元素实际发生,你的检测器将被调用)
有一个特许的“ALL”常数,可以从getApplicableAttributes和getApplicableElements返回,这样可以调用所有属性和标签的检测器,这是例如PxUsageDetector检测器检查任何属性值是否使用了px单位作为xml属性值的后缀。
(xml扫描的一个提示:org.w3c.dom.Element.getAttribute()应该永远不会返回null,对于一个不存在的属性,它应该返回空字符串。然而,这很难重现除了清楚的堆栈跟踪显示Eclipse有时会返回null,所以许多检测器试图对此进行防御,并检查null,即使不应该是必要的)。
报告错误
如果你的检测器识别除了问题,则只需要在context对象上调用report()方法(将其传递到每个检测器方法中)
除了列出它报告的问题,它还需要提供发生问题的位置,范围节点和问题消息。
报告中的位置是这样解释的:它指向错误发生的地方。对于xml和java 资源文件来说这很简单,只需要将相应的XML DOM和Parse AST 树节点传递给context.getLocation方法,该方法将创建一个具有与给定节点相对应的正确文件名和偏移量的位置。如果你的错误属于某个属性,则传递属性而不是周围的元素,以使错误更精准的显示错误;对于类文件来说这有一些困难,看一下ClassContext类的一些有用的实用的方法,当然也可以检查一些现有的基于类的检查器。
范围节点是围绕该错误的最近的AST/XML节点,这通常与你创建的节点相同,被Lint基础设施用于支持“suppress”注释。例如:在java文件中,用户可以在围绕错误位置的一些句法元素上添加@SuppressLint("Id"),Lint将从你正在传递的范围节点向外搜索出错误,以查看错误是否被抑制。
在某些情况下,你可能明确的想要检查错误是否被自己抑制,因为计算真的很昂贵并且它还可能被抑制了,或者因为存在多个可能抑制的位置。例如,在错误一致性(翻译一致性)的情况下,也许在“其他”位置定义了此属性与该位置不一致的抑制属性。
请注意Location(和Location.Handle)类包含一个"client data"字段;它被一些检测器用来临时存储范围节点。
存储状态
可以轻松找到很多错误,如果这样的属性被设置,则将其报告为错误。但是许多错误需要更复杂的计算,你需要检查分布在多个文件上的多条数据。
通常这样做的方法是起诉前后文件钩子和前后项目钩子,detector类定义在每个扫描文件和每个项目回调之前和之后。许多检测器设置一些数据结构,并在扫描每个文件时填充它们。
然后,在afterProject钩子中,它们遍历所有数据并计算错误。
这里面临的一个挑战是,当您项目到达结束时,您无法轻松计算你报告的错误位置。这儿有几个解决方案:
1. 在这时候存储location handles,location handle是Location中一种轻量级的处理。创建一个涉及一些计算的真实Location,因为它需要计算偏移量,行和列数。在某些情况下,你可能还不知道这是一个错误,但是你想能够获取这个没有机会显示的错误位置,在这种情况下,创建location handle来代替(java和xml解析器都提供createHandle方法)。当你得到需要创建一个错误的代码时,调用handle.resolve()将会产生一个完整的位置。
2. 在第二次传递中获取确切的位置,这在下面的多段传递部分描述。
多段传递
Lint以商榷定义好的顺序处理项目文件:
1. Manifest文件
2. 资源文件,按字母顺序(首先资源文件夹按字母顺序排列,然后内部的每个文件按照字母书序排列)
3. java源文件
4. java class文件,按字母顺序(但外部类是在内部类之前,即使Foo$Bar.class字母的顺序在Foo.class之前)
5. Proguard 混淆文件
这就意味着你可以依靠 在 value 文件之前(因为 "layout" < "values")正在处理的layout文件以及在特定翻译之前处理的默认value 目录(因为“values” < "value-de")等。
通常,你可以在数据结构中存储你之后可能需要的一些信息 ,然后在获取正确数据类型的时候查阅它们。
然而,这并不总是实用的。拿UnusedResourceDetector 举个例子。它需要每个没有使用机会的单资源、单字符、属性,布局视图 等资源的位置。他不是存储所有这些信息,而是使用Lint的“多阶段”支持。
只有要求另一个阶段包含在后续阶段的的检测器可以指示它对另一个处理阶段感兴趣,并且它们只能使用相同或较窄的范围。并且Lint的基础设施可以并且将限制阶段的数量以防万一检测器被不正确地写入和保持“递归”。
未使用的资源检测器将在分析项目的最后知道哪些资源未被使用。如果(并且只有)由未使用的资源,它将要求另一个阶段进行传递。在第二次传递时,它只是查找它所知道的未被使用资源(存储在一个集合当中)的事件,然后它记录这些未使用资源的准确位置。在第二个阶段结束的时候它上报告所有未被使用资源的错误(使用新位置)。
无论你是使用多段传递或者前面存储额外的数据并且使用location handles取决于你;我会说这依赖于于错误的可能性,你将需要存储的数据量等。
分析java代码
如果你需要分析java代码,你有两个选择:
1.通过实现JavaScanner接口分析.java文件
2.通过实现ClassScanner接口分析.class文件
每个都有利弊。
分析java源代码可以让你:
1.容易得到错误的准确的位置信息,AST节点包含精确的位置信息;
2.你可以访问只有在源文件当中的信息,例如资源常量(例如R.color.red). 当一个java文件被编译成字节码的时候,它被内联,所以没有记录整数0x1123123123是对应R.color.red。另一个例子,变量声明的注释仅在源文件中是可用的。
3. AST节点结构代表资源代码,所以它很容易做到类似于“查找围绕这个调用的if-statement”或“获取调用该方法计算的第一个参数的表达式”等等
但是,解析树不包含解析的类型(注意:这个限制刚刚被解除,请参见下面的类型解析)。这是我们使用的一个解析树库的限制;javac 或者 Eclipse ECJ 可以生成这条信息,但是它并没有在AST当中暴露出来,当然,从命令行运行lint 并没有使用这两种解析器当中的任何一个,它使用了第三种,分析字节码对于其它类型的分析来说要更好。API检查器示例可以通过分析已经内联的字段、已经执行字符串连接、并且在字节码级别更容易进行流分析的字节码,从而可以做出更准确的工作。
(*:Lombok中有一些设施可以根据检查导入语句来解析类型,没有一个检查器使用这个(至今为止),所以我不能确保是否所有必要的类型都通过Lint/Java API 浮出水面)
类型解析
(下一个版本的Lint,工具27,gradle 插件0.9.2+,android studio 0.5.4 ,和ADT27)java AST解析树检测器都可以解析类型和声明。这仅仅添加到lint中,并且提供新的APIs,你可以询问在给定AST节点的已解析类型和已解析声明。它在IntelliJ和命令行lint 变量当中实现(例如 :lint 脚本以及gradle插件)。它至今为止在Eclipse ADT中尚未实现,但应该会很快,因为端口将非常容易(命令行使用Eclipse java编译器来做它的类型来源,所以应该很容易迁移到Eclipse ADT 插件)
分析java资源文件
为了分析字节码,你的检测器应该实现ClassScanner。Lint 使用ASM库处理.class 文件。它将分两个阶段进行,首先,它会剔除所有的class文件(不读取方法体等),为项目中使用的库以及项目本身中所有的类计算一个超类映射。一个类检测器在它自己分析所有给定class的超类期间可以请求lint,例如,API 检查器使用Lint来处理虚拟方法。所以如果Foo 类继承 Activity,如果它看到一个虚拟调度到“foo”方法,它可以唤醒父类,看看这是否是一个继承的方法并得到其API级别。
一旦Lint有超类映射,它依次处理每个类,并产生一个类节点(一个“.class”文件的“DOM”),然后传递给每个ClassScanner。检测器可以随后使用这些类节点根据需要去分析字节。参见一些现有的检测器来进行实例。
增量的Lint
一些工具,如Eclipse的lint集成,它允许Lint“增量的”运行。例如:在Eclipse中,无论何时你使用UI构建器,或者无论何时你保存一份xml文件或者一份java文件,Eclispe将以增量模式运行Lint,只能分析当前的文件,并更新这个文件当中所有的问题。
然而,请注意,它不能够通过查看单个文件来某些类型的检查,为了保证一份资源未被使用,它同时需要查看声明(例如一份.png图片文件)以及所有的java代码来确保没有任何的地方引用这张图片。
lint基础设施处理的方式是问题的范围属性。某些范围是指单个文件--如Scope.RESOURCE_FILE,Scope.JAVA_FILE或Scope.CLASS_FILE。然而,lint只能对给定的问题进行增量分析,如果它的范围仅包含单个文件范围。有一些类型的问题适用于多个不同的范围,例如ApiDetector,它可以同时分析.xml文件和.class文件。然而,每一份文件都可以被独立分析。因此,问题具备第二种可选类型的范围:分析范围。每个分析范围是可以分析问题的范围集。以下是ApiDetector问题的注册方式。
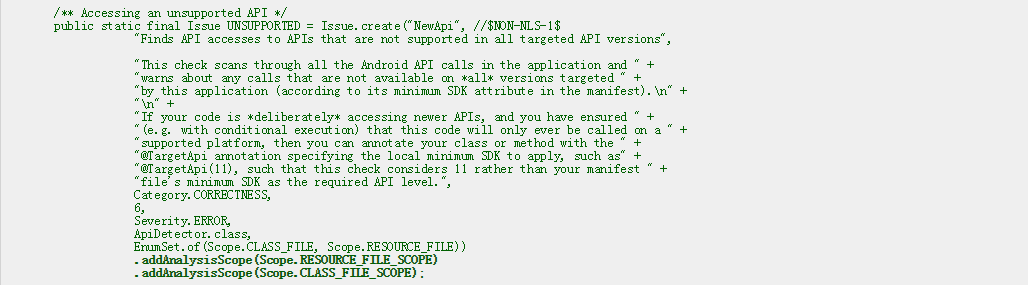
看最后两行--这个问题添加了一份资源文件和class文件作为可以被增量分析的独立范围。
任何需要比当前适用的分析要求更多范围的问题将在lint增量分析的过程中被禁止。
单元测试
编写lint的单元测试很简单。看一些现有的例子。你通常继承AbstractCheckTest,并覆盖getDetector()方法以返回检测器类的新实例。
然后你调用lintProject()方法(每一个测试),传递一个表示预期错误输出的字符串,以及用作在单元测试中即时创建的android项目中的数据文件的源文件列表。
当你编写测试的时候你通常不知道错误输出。只是放一个空白的测试,运行这个测试,并且当测试文件,在Eclipse中双击它,并且它将向你展示差异;粘贴复制输出台的实际输出,并将其粘贴到测试中的预期字符串中--假设实际输出是你认为正确的。
lintProject 调用中引用的测试数据文件与sdk/lint/libs/lint_checks/tests/src/com/android/tools/lint/checks/data/相关。请注意,你不希望在其中检查 .java或者.class 文件,因为它将导致这些文件被视为lint项目本身的一部分。实际上,使用.txt或.data后缀来命名它们,你可以使用特殊语法 foo=>bar 即时命名文件。例如,ApiDetector测试包含以下内容:apicheck/ApiTargetTest.java.txt=>src/foo/bar/ApiTargetTest.java
为什么我的检测器不工作
确保你已经把它添加到 BuiltinRegistry类中!同时确保你的检测器有一个公共默认构造函数(使其可以被实例化),并且它具备正确的范围。