本章将介绍scrapy框架里面的spider中间件,更多内容请参考: >本章将介绍Request与Response,更多内容请参考:Python学习指南
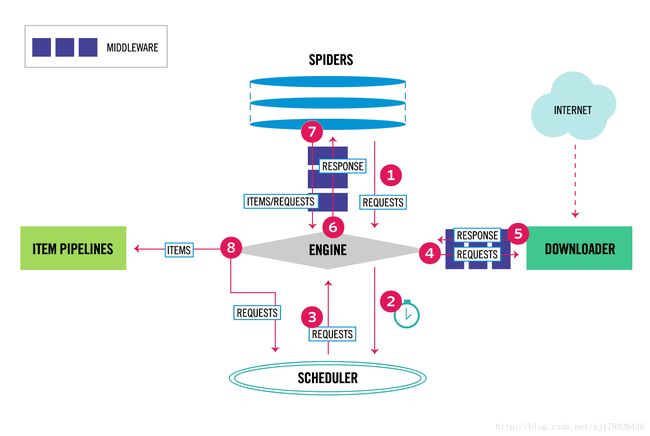
scrapy框架数据流
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎从Spiders中获取到的最初的要爬取的请求(Requests)。
- 引擎安排请求(Requests)到调度器中,并向调度器请求下一个要爬取的请求(Requests)。
- 调度器返回下一个要爬取的请求(Request)给请求。
- 引擎从上步中得到的请求(Requests)通过下载器中间件(Downloader Middlewares)发送给下载器(Downloader),这个过程中下载器中间件(Downloader Middlerwares)中的
process_request()函数就会被调用。 - 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader Middlewares)中的
process_response()函数,最后返回给引擎 - 引擎从下载器中得到上步中的Response并通过Spider中间件(Spider Middewares)发送给Spider处理,这个过程中Spider中间件(Spider Middlewares)中的
process_spider_input()函数会被调用到。 - Spider处理Response并通过Spider中间件(Spider Middlewares)返回爬取到的Item及(跟进的)新的Request给引擎,这个过程中Spider中间件(Spider Middlewares)的
process_spider_output()函数会被调用到。 - 引擎将上步中Spider处理的及其爬取到的Item给Item管道(Piplline),将Spider处理的Requests发送给调度器,并向调度器请求可能存在的下一个要爬取的请求(Requests)
- (从第二步)重复知道调度器中没有更多的请求(Requests)。
Spider中间件(Spider Middlewares)
Spider中间件是介入到Scrapy中的spider处理机制的钩子框架,可以插入自定义功能来处理发送给Spiders的response,以及spider产生的item和request。
1.激活Spider中间件(Spider Middlewares)
要启用Spider中间件(Spider Middlewares),可以将其加入到SPIDER_MIDDLEWARES设置中。该设置是一个字典,键为中间件的路径,值为中间件的顺序(order)。
样例:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware' : 543,
}
SPIDER_MIDDLEWARES设置会与Scrapy定义的SPIDER_MIDDLEWARES_BASE设置合并(但不是覆盖),而后根据顺序(order)进行排序,最后得到启用中间件的有序列表;第一个中间件是最靠近引擎的,最后一个中间就爱你是最靠近spider的。
关于如何分配中间的顺序请查看SPIDER_MIDDLEWARES_BASE设置,而后根据您想要放置中间件的位置选择一个值。由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是最重要的。
如果您想禁止内置的(在SPIDER_MIDDLEWARES_BASE中设置并默认启用的)中间件,您必须在项目的SPIDER_MIDDLEWARES设置中定义该中间件,并将其赋值为None,例如,如果您想要关闭off-site中间件:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': None,
}
最后,请注意,有些中间件需要通过特定的设置来启用。更多内容请查看相关中间件文档。
2. 编写自己的spider中间件
编写中间件十分简单,每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.contrib.spidermiddleware.SpiderMiddleware
process_spider_input(response, spider)
当response通过spider中间件时,该方法被调用,处理该response。
process_spider_input()
应该返回一个None或者抛出一个异常(exception)。
- 如果其返回None,Scrapy将会继续处理该response,调用所有其他中间件直到spider处理该response。
- 如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的process_spider_input()方法,并调用request的errback。errback的输出将会以另一个方向被输入到中间链中,使用
process_spider_output()方法来处理,当其抛出异常时则带调用process_spider_exception()。
参数:
response(Response对象) - 被处理的response
spider(Spider对象) - 该response对应的spider
process_spider_out(response, result, spider)
当Spider处理response返回result时,该方法被调用。
process_spider_output()必须返回包含Request或Item对象的可迭代对象(iterable)。
参数:
response(Response对象) - 生成该输出的response
result(包含Reques或Item对象的可迭代对象(iterable)) - spider返回的result
spider(Spider对象) - 其结果被处理的spider
process_spider_exception(response, exception, spider)
当spider或(其它spider中间件的)process_spider_input()抛出异常时,该方法被调用
process_spider_exception()必须要么返回None,要么返回一个包含Response或Item对象的可迭代对象(iterable)。
通过其返回None,Scrapy将继续处理该异常,调用中间件链中的其它中间件的process_spider_exception()
如果其返回一个可迭代对象,则中间件链的process_spider_output()方法被调用,其他的process_spider_exception()将不会被调用。
response(Response对象) - 异常被抛出时被处理的response
exception(Exception对象) - 被抛出的异常
spider(Spider对象) - 抛出异常的spider
process_start_requests(start_requests, spider)
该方法以spider启动的request为参数被调用,执行的过程类似于process_spider_output(),只不过其没有相关联的response并且必须返回request(不是item)。
其接受一个可迭代的对象(start_requests参数)且必须返回一个包含Request对象的可迭代对象。
当在您的spider中间件实现该方法时,您必须返回一个可迭代对象(类似于参数start_requests)且不要遍历所有的start_requests。该迭代器会很大(甚至是无限),进而导致内存溢出。Scrapy引擎再其具有能力处理start_requests时将会拉起request,因此start_requests迭代器会变得无限,而由其它参数来停止spider(例如时间限制或者item/page计数)。
参数:
start_requests(b包含Request的可迭代对象) - start requests
spider(Spider对象) - start request所属的spider
案例:下载妹子图图片
编写spider实现代码
1. spider文件:
##file:MeizituSpider.py
#-*- coding:utf-8 -*-
import scrapy
from scrapy.spiders import Request
import logging
import re
from cnblogSpider.items import SaveGirlImageItem
logger = logging.getLogger(__name__)
class MeiziTuSpider(scrapy.Spider):
name = "meizitu"
allowed_domains = ['meizitu.com']
user_header = {
"Referer": "http://www.meizitu.com/tag/nvshen_460_1.html",
"Upgrade-Insecure-Requests" : "1",
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0"
}
def start_requests(self):
logging.debug("###### 妹子图Spider开始启动.....%s"%self)
return [Request(url="http://www.meizitu.com/tag/nvshen_460_1.html", callback=self.parse, headers = self.user_header)]
@staticmethod
def __remove_html_tags(str):
return re.sub(r'<[^>]+>', '', str)
def parse(self, response):
# print(response.body)
for picdiv in response.css('div[class="pic"]'):
image_urls = picdiv.css('a[target="_blank"] img::attr(src)').extract_first()
image_split = image_urls.split("/")
image_name = image_split[-3]+ image_split[-2]+ image_split[-1]
yield SaveGirlImageItem({
'name' : MeiziTuSpider.__remove_html_tags(picdiv.css('a[target="_blank"] img::attr(alt)').extract()[0]),#获取这组相片的名称
'url' : picdiv.css('a[target="_blank"] img::attr(src)').extract_first(), #获取这组照片的链接
'image_urls' : [picdiv.css('a[target="_blank"] img::attr(src)').extract_first()],
'images' : image_name
})
next_page = response.xpath(u'//div[@class="navigation"]//li/a[contains(.,"下一页")]/@href').extract_first()
if next_page is not None:
requesturl = "http://www.meizitu.com" + next_page
yield Request(requesturl, callback = self.parse, headers=self.user_header)
2. 中间件代码:
##file:middlewares.py
import logging
###下面是妹子图案例的spider中间件
logger = logging.getLogger(__name__)
##start_requests函数调用这个spider中间件
class ModifyStartRequest(object):
def process_start_requests(self, start_requests, spider):
logging.info("#### 22222222 #####strat_requests %s, spider %s ####"%(start_requests, spider))
last_request = []
for one_request in start_requests:
logging.info("#### one_request %s, spider %s ####"%(one_request, spider))
last_request.append(one_request)
logging.info("#### 2222222 ####last_request %s, spider %s ####"%(last_request, spider))
return last_request
#file:spiderMiddleware.py
import logging
logger = logging.getLogger(__name__)
###
class SpiderInputMiddleware(object):
def process_spider_input(self, response, spider):
logging.info("#### 3333 response %s, spider %s ####"%(response, spider))
return
class SpiderOutputMiddleware(object):
def process_spider_output(self, response, result, spider):
logging.info("#### 4444 response %s, spider %s ####" %(response, spider))
return result
3. item文件:
#file:items.py
class SaveGirlImageItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
4. settings设置:
#file:settings.py
LOG_LEVEL = "INFO"
#禁用Cookie
COOKIES_ENABLED = False
#spider中间件
SPIDER_MIDDLEWARES = {
# 'cnblogSpider.middlewares.CnblogspiderSpiderMiddleware': 543,
'cnblogSpider.middlewares.ModifyStartRequest' : 643,
'cnblogSpider.spiderMiddleware.SpiderInputMiddleware' : 743,
'cnblogSpider.spiderMiddleware.SpiderOutputMiddleware': 843
}
#管道中间件
ITEM_PIPELINES = {
'cnblogSpider.pipelines.MeizituPipelineJson' :10,
'scrapy.pipelines.images.ImagesPipeline' : 1
}
#使用图片管道文件下载图片
IMAGES_STORE="/home/chenqi/python/python_code/python_Spider/chapter04/cnblogs/cnblogSpider/cnblogSpider/images"
IMAGES_URLS_FIELD = "image_urls"
IMAGES_RESULT_FIELD="images"
参考
- 代码目录