本文参考整理了Coursera上由NTU的林轩田讲授的《机器学习技法》课程的第七章的内容,主要围绕将不同hypotheses中具有预测性的features进行融合的aggregation技术,讲述了引入blending的动机,常用的blending方式(如uniform blending、linear blending和any blending等),介绍了利用bootstrapping技术的Bagging Meta Algorithm,并利用实际例子表现了aggregation的巨大威力和用处。文中的图片都是截取自在线课程的讲义。
欢迎到我的博客跟踪最新的内容变化。
如果有任何错误或者建议,欢迎指出,感激不尽!
--
本系列文章已发七章,前六章的地址如下:
- 一、线性SVM
- 二、SVM的对偶问题
- 三、Kernel SVM
- 四、Soft-Margin SVM
- 五、Kernel Logistic Regression
- 六、Support Vector Regression
Blending和Bagging都是Aggregation里面非常典型的做法。
Aggregation的动机
日常选股
假设你有T个朋友g1,g2...gT预测某支股票X是否会上涨gt(X)
你会怎么做?
- 根据他们的平常表现选择最可信的朋友---即validation
- 均衡(uniformly)地混合朋友们的预测---让他们一人一票,最后选择票数最多的结果
- 不均衡(non-uniformly)地混合朋友们的预测---每个人的票数不一,让他们投票,而票数的分配和问题有关,比如有人擅长分析科技类股票,有人擅长分析传统产业股票,因此在不同条件下,对不同人的信任度也不同,即如果[t 满足某些条件],则给朋友t多一些票。
- ...更多方式
对应到机器学习里面,把T个人的意见融合起来以获得更好的表现,就是aggregation模型,即aggregation models = mix or combine hypotheses for better performance.
数学形式
数学化以上操作:
- 选择平常表现(val)最好的人
- 等额投票
- 不等额投票(包括情形1、2)
包含了:
- 选择,即αt = [[ Eval(gt)最小 ]]
- 等额: 即αt = 1
- 根据条件合并预测(包括情形1、2、3)
- 包含了不等额投票,即qt(X)=αt。
aggregation model是一个非常丰富的家族。
aggregation与selection的对比
selection: 选择出一个strong的hypothesis(强人主导)
aggregation: do better with many (possibly weaker) hypotheses(三个臭皮匠)
为什么aggregation可能会做得更好
- more power,more strong

如果只用垂直、水平线,怎样都做不太好,而如果能把垂直和水平的线结合起来,则可能会做得比较好。
如果等额混合不同的弱弱的hypotheses,就可能会得到一个比较强的G(x),比较复杂的边界,类似于之前的feature transform,它也扩展了我们的model的power。
- more moderate,more regularization

有若干条直线可以完美分割OO和XX,PLA会随机选择一条。如果等额混合不同的random-PLA hypotheses,则会收敛于中间那条large margin的直线,比较中庸,具有regularization的效果。因此aggregation具有more powerful和more regularization这两种看似对立的效果。
Uniform Blending
uniform blending for classification
blending: 已知gt。
uniform blending: known gt each with 1 ballot

- 如果每个gt都一样(独裁政治),则G和g的表现是相同的。
- 如果gt各不相同(多样性+民主),则多数派能纠正少数派。
- 对多类别分类,一样的结果
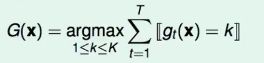
对于regression如何做呢?
uniform blending for regression

- 每个gt都一样,融合g效果变化不大
- 每个gt都不太一样,有些gt(x) > f(x),而有些gt(x) < f(x),两者抵消,平均值可能会比单一值更加准确稳定。
因此,如果我们的aggregation要起作用,很重要的前提是gt要各不一样,畅所欲言,对于diverse hypotheses,即使使用非常简单的uniform blending,也可以比任何单一的hypothesis表现得更好。
uniform blending for regression work的理论保证

先讨论对于固定的确定的X
随便选一个gt,期望意义下的square error是
将gt的期望错误和G的错误联系在一起。
avg代表
推广到所有X上,对X分布取期望,得到

由此可知,最好的g是否比G好我们不得而知,但平均的g确实没有G表现好,我们的uniform blending对于square error regression确实work了。
bias-variance decomposition
考虑一个虚拟迭代过程(t = 1,2...T)
- 第t轮,取得N笔资料Dt,Dt来自分布PN(i.i.d)
- 通过A(Dt)学习获得gt
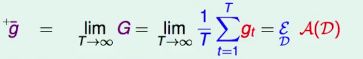
将刚刚得到的式子推广到无穷大

把一个演算法的表现拆分成bias-variance decomposition。
而uniform blending就是减少variance,使表现更加稳定。
Linear and Any Blending
linear blending
linear blending: known gt, each to be given αt ballot

什么样的α是好的α?
min[αt>=0]Ein(α)
要求解的问题


有点类似two-level learning,先得到gt,再做LinReg。
linear blending = LinModel + hypotheses as transform + constraints
唯一的不同是要求αt>=0,而一般的LinReg没有要求Wt>=0。
constraints on α

在实际中,我们常常故意忽略掉α的约束,如果αt<0,就把对应的gt想象成gt'=-gt好了,对于regression可能比较奇怪,但是大部分时候constraints放在一边没有什么影响。
linear blending versus selection
之前我们都说gt直接给定,那么gt通常是怎么来的呢?
在实践中,常常g1∈H1,g2∈H2 ... gT∈HT,即g是从不同的model通过求最好的Ein来得到的,就像之前在model selection中发生的事情一样。
recall:
selection by minimum Ein --- best of best --- best of all
则 dvc = (∪Ht),这也就是为什么我们要用Eval而不是Ein来做选择。
recall:
linear blending 包含了 selection 作为特殊情况
即αt = [[ Eval(gt-) 最小 ]]
如果用Ein来做linear blending,即aggregation of best,模型复杂度代价比best of best还大,>= dvc = (∪Ht).
模型更加危险,因此实践中不建议使用Ein来选α,选择α时让Eval而不是Ein最小,gt-来自最小的E(train)。
Any Blending
从某个比较小的D(train),训练得到g1-,g2-...,gT-,把Dval中的(xn,yn)转换成(Zn=Φ-(xn),yn),Φ-(X) = (g1-(X), g2-(X) ... gT-(X))。
linear blending

注意最后回传的是Φ而不是Φ-,
我们不一定要用linear来合并{Zn,yn},可以用任何方法,即Any Blending,也叫作Stacking.
对Z空间中的资料不一定用Linear model,可用Non-linear model

any blending:
- powerful,达成了根据条件来进行blending的目的
- 有overfitting的危险,要小心使用
Blending in Practice

资料来临==>学习g==>validation set blending 得到G
- a special any blending model
E[test](squared): 519.45 ==> 456.24
- g、G 再做一次 linear blending ,test set blending: linear blending using Etest~
E[test](squared): 456.24 ==> 442.06
在实践中,blending是非常有用的,如果不考虑计算负担。
Bagging(Bootstrap Aggregation)
What We Have Done
blending: aggregate after getting gt
learning: aggregate as well as getting gt

gt的多样性很重要,如何得到不一样的g?
- 通过不同的模型: g1∈H1,g2∈H2 ... gT∈HT
- 同一模型的不同参数: 如GD的不同的η,SVM中不同的C
- 演算法本来就有randomness: 如有不一样的randome seeds的随机PLA
- 资料的randomness: within-cross-validation hypotheses gv-
接下来,我们尝试用同一份资料制造好多g,以产生多样性。
Revisit of Bias-Variance

- consensus 比直接 A(D) 更加稳定,但是需要很多笔资料
- 我们想要近似的g的平均,要做两个妥协
- 无限大T(很大的T)
- 只使用手中资料D,生成T个近似的gt=A(Dt),其中Dt~PN
我们需要用到统计学中的工具bootstrapping,它做的是从D中重新抽样来模拟Dt。
Bootstrap Aggregation
sampling with replacement 有放回的抽样


bootstrap aggregation:我们称为BAGging,一个简单的meta algorithm,在base algorithm A 之上。
Bagging Pocket In Action

每个Pocket演算法跑1000趟,使用25条Pocket线组合而成。
- 每个来自bagging生成的g都很不一样
- aggregation后形成了还算合适的non-linear边界来进行二元分类
如果base algorithm对数据随机性很敏感,则bagging通常工作得很好
在bootstrapping过程里,原来的N笔资料D里面再重新抽样N个D',则D'正好为D的可能性是N!/N^N。
Mind Map Summary

下一章我们讲述是否可以得到比Bagging更加diverse的hypotheses,从而使blending后的G更加strong,即逐步增强法。欢迎关注!