转自:
https://www.w3cschool.cn/architectroad/architectroad-mysql-parallel-copy.html
https://blog.csdn.net/linuxlsq/article/details/52606292
http://cenalulu.github.io/mysql/mysql-5-6-gtid-basic/
一、缘起
mysql主从复制,读写分离是互联网用的非常多的mysql架构,主从复制最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重。
为什么mysql主从延时这么大?

回答:从库使用【单线程】重放relaylog。
什么是relay log(中继日志)
The relay log, like the binary log, consists of a set of numbered files containing events that describe database changes, and an index file that contains the names of all used relay log files.
The term “relay log file” generally denotes an individual numbered file containing database events. The term”relay log” collectively denotes the set of numbered relay log files plus the index file
参见:http://www.21yunwei.com/archives/4896
优化思路是什么?
回答:使用单线程重放relaylog使得同步时间会比较久,导致主从延时很长,优化思路不难想到,可以【多线程并行】重放relaylog来缩短同步时间。
mysql如何“多线程并行”来重放relaylog,是本文要分享的主要内容。
二、如何多线程并行重放relaylog

通过多个线程来并行重放relaylog是一个很好缩短同步时间的思路,但实施之前要解决这样一个问题:
如何来分割relaylog,才能够让多个work-thread并行操作数据data时,使得data保证一致性?
首先,【随机的分配relaylog肯定是不行的】,假设relaylog中有这样三条串行的修改记录:
update account set money=100 where uid=58;
update account set money=150 where uid=58;
update account set money=200 where uid=58;
串行执行:肯定能保证与主库的执行序列一致,最后得到money=200
随机分配并行执行:3个工作线程并发执行这3个语句,谁最后执行成功是不确定的,故得到的数据可能与主库不同
好,对于这个问题,可以用什么样的思路来解决呢(大伙怎么想,mysql团队其实也就是这么想的)
【方法一:相同库上的写操作,用相同的work-thread来重放relaylog;不同库上的写操作,可以用多个work-thread并发来重放relaylog】
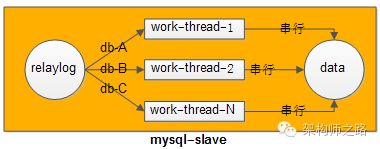
如何做到呢?
回答:不难,hash(db-name) % thread-num,库名hash之后再模上线程数,就能够做到。
存在的不足?
很多公司对mysql的使用是“单库多表”,如果是这样的话,仍然是同一个work-thread在串行执行,还是不能提高relaylog的重放速度。
优化方案:将“单库多表”的模式升级为“多库多表”的模式。
其实,数据量大并发量大的互联网业务场景,“多库”模式还具备着其他很多优势,例如:
(1)非常方便的实例扩展:dba很容易将不同的库扩展到不同的实例上
(2)按照业务进行库隔离:业务解耦,进行业务隔离,减少耦合与相互影响
(3)…
对于架构师进行架构设计的启示是:使用多库的方式设计db架构,能够降低主从同步的延时。
新的想法:“单库多表”的场景,还有并行执行优化余地么?
仔细回顾和思考,即使只有一个库,数据的修改和事务的执行在主库上也是并行操作的,既然在主库上可以并行操作,在从库上为啥就不能并行操作,而要按照库来串行执行呢(表示不服)?
新的思路:将主库上同时并行执行的事务,分为一组,编一个号,这些事务在从库上的回放可以并行执行(事务在主库上的执行都进入到prepare阶段,说明事务之间没有冲突,否则就不可能提交),没错,mysql正是这么做的。
【方法二:基于GTID的并行复制】
新版的mysql,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=1
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=2
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=3
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=4

和原来的日志相比,多了last_committed和sequence_number。
last_committed表示事务提交时,上次事务提交的编号,如果具备相同的last_committed,说明它们在一个组内,可以并发回放执行。
三、结尾
从mysql并行复制缩短主从同步时延的思想可以看到,架构的思路是相同的:
(1)多线程是一种常见的缩短执行时间的方法
(2)多线程并发分派任务时必须保证幂等性:mysql的演进思路,提供了“按照库幂等”,“按照commit_id幂等”两种方式,思路大伙可以借鉴
mysql在并行复制上的逐步优化演进:
mysql5.5 -> 不支持并行复制,对大伙的启示:升级mysql吧
mysql5.6 -> 按照库并行复制,对大伙的启示:使用“多库”架构吧
mysql5.7 -> 按照GTID并行复制
四、附录
一、MySQL主从复制原理介绍
MySQL的主从复制是一个异步的复制过程(虽然一般情况下感觉是实时的),数据将从一个Mysql数据库(我们称之为Master)复制到另一个Mysql数据库(我们称之为Slave),在Master与Slave之间实现整个主从复制的过程是由三个线程参与完成的。其中有两个线程(SQL线程和IO线程)在Slave端,另一个线程(I/O线程)在Master端。
要实现MySQL的主从复制,首先必须打开Master端的binlog记录功能,否则就无法实现。因为整个复制过程实际上就是Slave从aster端获取binlog日志,然后再在Slave上以相同顺序执行获取的binlog日志中的记录的各种SQL操作

1)在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制。
2)此时,Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change
master命令指定的)之后开始发送binlog日志内容
3)Master服务器接收到来自Slave服务器的IO线程的请求后,其上负责复制的IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在Master服务器端记录的IO线程。返回的信息中除了binlog中的下一个指定更新位置。
4)当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
5)Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点
二、GTID简介
什么是GTID
GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。 GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。下面是一个GTID的具体形式
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
更详细的介绍可以参见:官方文档
GTID的作用
那么GTID功能的目的是什么呢?具体归纳主要有以下两点:
- 根据GTID可以知道事务最初是在哪个实例上提交的
- GTID的存在方便了Replication的Failover

此时,Server A的服务器宕机,需要将业务切换到Server B上。同时,我们又需要将Server C的复制源改成Server B。复制源修改的命令语法很简单即CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn。而难点在于,由于同一个事务在每台机器上所在的binlog名字和位置都不一样,那么怎么找到Server C当前同步停止点,对应Server B的master_log_file和master_log_pos是什么的时候就成为了难题。这也就是为什么M-S复制集群需要使用MMM,MHA这样的额外管理工具的一个重要原因。 这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server C当前停止点的GTID就能唯一定位到Server B上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。 So easy不是么?