Druid基本概念及架构介绍
1.什么是Druid
Druid是一个专为大型数据集上的高性能切片和OLAP分析而设计的数据存储。Druid最常用作为GUI分析应用程序提供动力的数据存储,或者用作需要快速聚合的高度并发API的后端。Druid的常见应用领域包括:
点击流分析
网络流量分析
服务器指标存储
应用性能指标
数字营销分析
商业智能/OLAP
2.druid的主要特点
1.列式存储格式 Druid使用面向列的存储,这意味着它只需要加载特定查询所需的精确列。这为仅查看几列的查询提供了巨大的速度提升。此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。
2.高可用性与高可拓展性 Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。Druid通常部署在数十到数百台服务器的集群中,并且可以提供数百万条记录/秒的摄取率,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。
3.大规模并行处理 Druid可以在整个集群中并行处理查询。
4.实时或批量摄取 实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure-merge)-Tree结构使Druid拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
5.自愈,自平衡,易于操作 作为运营商,要将群集扩展或缩小,只需添加或删除服务器,群集将在后台自动重新平衡,无需任何停机时间。如果任何Druid服务器发生故障,系统将自动路由损坏,直到可以更换这些服务器。Druid旨在全天候运行,无需任何原因计划停机,包括配置更改和软件更新。
6.云原生,容错的架构,不会丢失数据 一旦Druid摄取了您的数据,副本就会安全地存储在深层存储(通常是云存储,HDFS或共享文件系统)中。即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。对于仅影响少数Druid服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。
7.亚秒级的OLAP查询分析 Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
8.近似算法 Druid包括用于近似计数 - 不同,近似排序以及近似直方图和分位数的计算的算法。这些算法提供有限的内存使用,并且通常比精确计算快得多。对于精确度比速度更重要的情况,Druid还提供精确计数 - 不同且精确的排名。
9.丰富的数据分析功能针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口。
3.为什么会有Druid
大数据时代,如何从海量数据中提取有价值的信息,是一个亟待解决的难题。针对这个问题,IT巨头们已经开发了大量的数据存储与分析类产品,比如IBM Netezza、HP Vertica、EMC GreenPlum等,但是他们大多是昂贵的商业付费类产品,业内使用者寥寥。
而受益于近年来高涨的开源精神,业内出现了众多优秀的开源项目,其中最有名的当属Apache Hadoop生态圈。时至今日,Hadoop已经成为了大数据的“标准”解决方案,但是,人们在享受Hadoop便捷数据分析的同时,也必须要忍受Hadoop在设计上的许多“痛点”,下面就罗列三方面的问题:
1.何时能进行数据查询? 对于Hadoop使用的Map/Reduce批处理框架,数据何时能够查询没有性能保证。
2.随机IO问题。 Map/Reduce批处理框架所处理的数据需要存储在HDFS上,而HDFS是一个以集群硬盘作为存储资源池的分布式文件系统,那么在海量数据的处理过程中,必然会引起大量的读写操作,此时随机IO就成为了高并发场景下的性能瓶颈。
3.数据可视化问题。 HDFS是一个优秀的分布式文件系统,但是对于数据分析以及数据的即席查询,HDFS并不是最优的选择。
传统的大数据处理架构Hadoop更倾向于一种“后台批处理的数据仓库系统”,其作为海量历史数据保存、冷数据分析,确实是一个优秀的通用解决方案,但是如何保证高并发环境下海量数据的查询分析性能,以及如何实现海量实时数据的查询分析与可视化,Hadoop确实显得有些无能为力。
4.Druid直面的痛点
Druid的母公司MetaMarket在2011年以前也是Hadoop的拥趸者,但是在高并发环境下,Hadoop并不能对数据可用性以及查询性能给出产品级别的保证,使得MetaMarket必须去寻找新的解决方案,当尝试使用了各种关系型数据库以及NoSQL产品后,他们觉得这些已有的工具都不能解决他们的“痛点”,所以决定在2011年开始研发自己的“轮子”Druid,他们将Druid定义为“开源、分布式、面向列式存储的实时分析数据存储系统”,所要解决的“痛点”也是上文中反复提及的“在高并发环境下,保证海量数据查询分析性能,同时又提供海量实时数据的查询、分析与可视化功能”。
5.什么时候应该使用Druid
-
1.如果您的用例符合以下几个描述符,Druid可能是一个不错的选择:
插入率非常高,但更新不常见。
您的大多数查询都是聚合和报告查询(“分组依据”查询)。您可能还有搜索和扫描查询。
您将查询延迟定位为100毫秒到几秒钟。
您的数据有一个时间组件(Druid包括与时间特别相关的优化和设计选择)。
您可能有多个表,但每个查询只能访问一个大的分布式表。查询可能会触发多个较小的“查找”表。
您有高基数数据列(例如URL,用户ID),需要对它们进行快速计数和排名。
您希望从Kafka,HDFS,平面文件或对象存储(如Amazon S3)加载数据。
-
2.情况下,您可能会不希望使用Druid包括:
您需要使用主键对现有记录进行低延迟更新。Druid支持流式插入,但不支持流式更新(使用后台批处理作业进行更新)。
您正在构建一个脱机报告系统,其中查询延迟不是很重要。
你想做“大”连接(将一个大事实表连接到另一个大事实表)。
6.Druid架构
Druid拥有一个多进程,分布式架构,旨在实现云友好且易于操作。每个Druid流程类型都可以独立配置和扩展,为您的群集提供最大的灵活性。此设计还提供增强的容错能力:一个组件的中断不会立即影响其他组件。
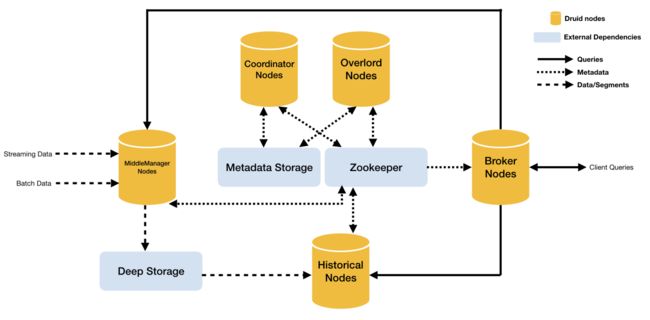
Druid集群包含多种节点类型,分别是Historical Node、Coordinator Node、Broker Node、Indexing Service Node(包括Overlord、MiddleManager和Peon)以及Realtime Node(包括Firehose和Plumber)。
Druid将整个集群切分成上述角色,有两个目的:
第一,划分Historical Node和Realtime Node,是将历史数据的加载与实时流数据处理切割开来,因为二者都需要占用大量内存与CPU;
第二,划分Coordinator Node和Broker Node,将查询需求与数据如何在集群内分布的需求切割开来,确保用户的查询请求不会影响数据在集群内的分布情况,从而不会造成数据“冷热不均”,局部过热,影响查询性能的问题。
下图给出了Druid集群内部的实时/批量数据流以及查询请求过程。我们可以看到,实时数据到达Realtime Node,经过Indexing Service,在时间窗口内的数据会停留在Realtime Node内存中,而时间窗口外的数据会组织成Segment存储到Deep Storage中;批量数据经过Indexing Service也会被组织成Segment存储到DeepStorage中,同时Segment的元信息都会被注册到元信息库中,Coordinator Nodes会定期(默认为1分钟)去同步元信息库,感知新生成的Segment,并通知在线的Historical Node去加载Segment,Zookeeper也会更新整个集群内部数据分布拓扑图。
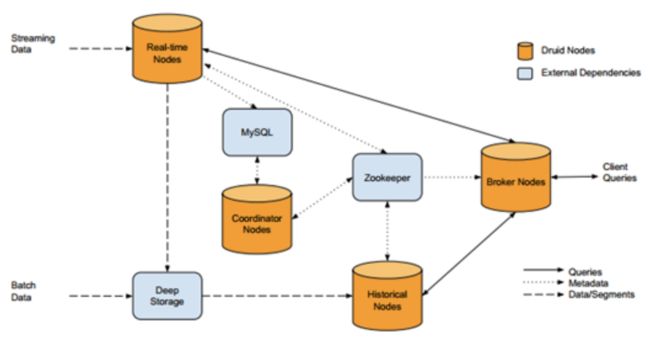
当用户需要查询信息时,会将请求提交给Broker Node,Broker Node会请求Zookeeper获取集群内数据分布拓扑图,从而知晓请求应该发给哪些Historical Node以及Realtime Node,汇总各节点的返回数据并将最终结果返回给用户。
7.Druid集群节点
7.1Historical Node
Historical Node的职责单一,就是负责加载Druid中非实时窗口内且满足加载规则的所有历史数据的Segment。每一个Historical Node只与Zookeeper保持同步,不与其他类型节点或者其他Historical Node进行通信。
Coordinator Nodes会定期(默认为1分钟)去同步元信息库,感知新生成的Segment,将待加载的Segment信息保存在Zookeeper中在线的Historical Nodes的load queue目录下,当Historical Node感知到需要加载新的Segment时,首先会去本地磁盘目录下查找该Segment是否已下载,如果没有,则会从Zookeeper中下载待加载Segment的元信息,此元信息包括Segment存储在何处、如何解压以及如何如理该Segment。Historical Node使用内存文件映射方式将index.zip中的XXXXX.smoosh文件加载到内存中,并在Zookeeper中本节点的served segments目录下声明该Segment已被加载,从而该Segment可以被查询。对于重新上线的Historical Node,在完成启动后,也会扫描本地存储路径,将所有扫描到的Segment加载如内存,使其能够被查询。
7.2Broker Node
Broker Node是整个集群查询的入口,作为查询路由角色,Broker Node感知Zookeeper上保存的集群内所有已发布的Segment的元信息,即每个Segment保存在哪些存储节点上,Broker Node为Zookeeper中每个dataSource创建一个timeline,timeline按照时间顺序描述了每个Segment的存放位置。我们知道,每个查询请求都会包含dataSource以及interval信息,Broker Node根据这两项信息去查找timeline中所有满足条件的Segment所对应的存储节点,并将查询请求发往对应的节点.
对于每个节点返回的数据,Broker Node默认使用LRU缓存策略;对于集群中存在多个Broker Node的情况,Druid使用memcached共享缓存。对于Historical Node返回的结果,Broker Node认为是“可信的”,会缓存下来,而Real-Time Node返回的实时窗口内的数据,Broker Node认为是可变的,“不可信的”,故不会缓存。所以对每个查询请求,Broker Node都会先查询本地缓存,如果不存在才会去查找timeline,再向相应节点发送查询请求。
7.3Coordinator Node
Coordinator Node主要负责Druid集群中Segment的管理与发布,包括加载新Segment、丢弃不符合规则的Segment、管理Segment副本以及Segment负载均衡等。如果集群中存在多个Coordinator Node,则通过选举算法产生Leader,其他Follower作为备份。
Coordinator会定期(默认一分钟)同步Zookeeper中整个集群的数据拓扑图、元信息库中所有有效的Segment信息以及规则库,从而决定下一步应该做什么。对于有效且未分配的Segment,Coordinator Node首先按照Historical Node的容量进行倒序排序,即最少容量拥有最高优先级,新的Segment会优先分配到高优先级的Historical Node上。由之前介绍我们知道,Coordinator Node不会直接与Historical Node打交道,而是在Zookeeper中Historical Node对应的load queue目录下创建待加载Segment的临时信息,等待Historical Node去加载该Segment。
Coordinator在每次启动后都会对比Zookeeper中保存的当前数据拓扑图以及元信息库中保存的数据信息,所有在集群中已被加载的、却在元信息库中标记为失效或者不存在的Segment会被Coordinator Node记录在remove list中,同一Segment对应的新旧version,旧version的Segments同样也会被放入到remove list中,最终被逻辑丢弃。
对于离线的Historical Node,Coordinator Node会默认该Historical Node上所有的Segment已失效,从而通知集群内的其他Historical Node去加载该Segment。但是,在生产环境中,我们会遇到机器临时下线,Historical Node在很短时间内恢复服务的情况,那么如此“简单粗暴”的策略势必会加重整个集群内的网络负载。对于这种场景,Coordinator会为集群内所有已丢弃的Segment保存一个生存时间(lifetime),这个生存时间表示Coordinator Node在该Segment被标记为丢弃后,允许不被重新分配最长等待时间,如果该Historical Node在该时间内重新上线,则Segment会被重新置为有效,如果超过该时间则会按照加载规则重新分配到其他Historical Node上。
考虑一种最极端的情况,如果集群内所有的Coordinator Node都停止服务,整个集群对外依然有效,不过新Segment不会被加载,过期的Segment也不会被丢弃,即整个集群内的数据拓扑会一直保持不变,直到新的Coordinator Node服务上线。
7.4Indexing Service
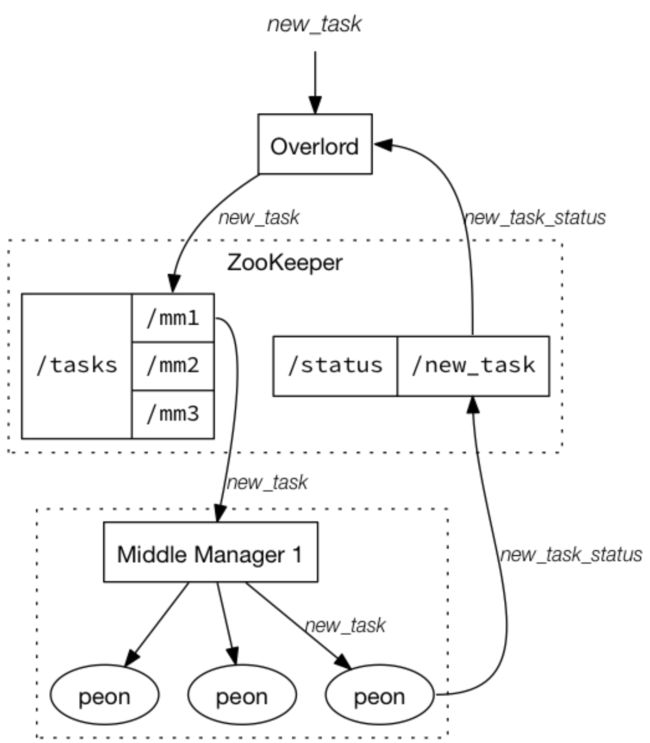
Indexing Service是负责“生产”Segment的高可用、分布式、Master/Slave架构服务。主要由三类组件构成:负责运行索引任务(indexing task)的Peon,负责控制Peon的MiddleManager,负责任务分发给MiddleManager的Overlord;三者的关系可以解释为:Overlord是MiddleManager的Master,而MiddleManager又是Peon的Master。其中,Overlord和MiddleManager可以分布式部署,但是Peon和MiddleManager默认在同一台机器上。图-3.5给出了Indexing Service的整体架构。
-
Overlord
Overlord负责接受任务、协调任务的分配、创建任务锁以及收集、返回任务运行状态给调用者。当集群中有多个Overlord时,则通过选举算法产生Leader,其他Follower作为备份。
Overlord可以运行在local(默认)和remote两种模式下,如果运行在local模式下,则Overlord也负责Peon的创建与运行工作,当运行在remote模式下时,Overlord和MiddleManager各司其职,根据图3.6所示,Overlord接受实时/批量数据流产生的索引任务,将任务信息注册到Zookeeper的/task目录下所有在线的MiddleManager对应的目录中,由MiddleManager去感知产生的新任务,同时每个索引任务的状态又会由Peon定期同步到Zookeeper中/Status目录,供Overlord感知当前所有索引任务的运行状况。
Overlord对外提供可视化界面,通过访问http://ip/console.html,我们可以观察到集群内目前正在运行的所有索引任务、可用的Peon以及近期Peon完成的所有成功或者失败的索引任务。
-
MiddleManager
MiddleManager负责接收Overlord分配的索引任务,同时创建新的进程用于启动Peon来执行索引任务,每一个MiddleManager可以运行多个Peon实例。
在运行MiddleManager实例的机器上,我们可以在${ java.io.tmpdir}目录下观察到以XXX_index_XXX开头的目录,每一个目录都对应一个Peon实例;同时restore.json文件中保存着当前所有运行着的索引任务信息,一方面用于记录任务状态,另一方面如果MiddleManager崩溃,可以利用该文件重启索引任务。
-
Peon
- Peon是Indexing Service的最小工作单元,也是索引任务的具体执行者,所有当前正在运行的Peon任务都可以通过Overlord提供的web可视化界面进行访问。
7.5Real-Time Node
在流式处理领域,有两种数据处理模式,一种为Stream Push,另一种为Stream Pull。
Stream Pull 如果Druid以Stream Pull方式自主地从外部数据源拉取数据从而生成Indexing Service Tasks,我们则需要建立Real-Time Node。Real-Time Node主要包含两大“工厂”:一个是连接流式数据源、负责数据接入的Firehose(中文翻译为水管,很形象地描述了该组件的职责);另一个是负责Segment发布与转移的Plumber(中文翻译为搬运工,同样也十分形象地描述了该组件的职责)。在Druid源代码中,这两个组件都是抽象工厂方法,使用者可以根据自己的需求创建不同类型的Firehose或者Plumber。Firehose和Plumber给我的感觉,更类似于Kafka_0.9.0版本后发布的Kafka Connect框架,Firehose类似于Kafka Connect Source,定义了数据的入口,但并不关心接入数据源的类型;而Plumber类似于Kafka Connect Sink,定义了数据的出口,也不关心最终输出到哪里。
Stream Push 如果采用Stream Push策略,我们需要建立一个“copy service”,负责从数据源中拉取数据并生成Indexing Service Tasks,从而将数据“推入”到Druid中,我们在druid_0.9.1版本之前一直使用的是这种模式,不过这种模式需要外部服务Tranquility,Tranquility组件可以连接多种流式数据源,比如Spark-Streaming、Storm以及Kafka等,所以也产生了Tranquility-Storm、Tranquility-Kafka等外部组件。
8.外部拓展
Druid集群依赖一些外部组件,与其说依赖,不如说正是由于Druid开放的架构,所以用户可以根据自己的需求,使用不同的外部组件。
Deep Storage Druid目前支持使用本地磁盘(单机模式)、NFS挂载磁盘、HDFS、Amazon S3等存储方式保存Segments以及索引任务日志。
Zookeeper Druid使用Zookeeper作为分布式集群内部的通信组件,各类节点通过Curator Framework将实例与服务注册到Zookeeper上,同时将集群内需要共享的信息也存储在Zookeeper目录下,从而简化集群内部自动连接管理、leader选举、分布式锁、path缓存以及分布式队列等复杂逻辑。
Metadata Storage Druid集群元信息使用MySQL 或者PostgreSQL存储,单机版使用derby。在Druid_0.9.1.1版本中,元信息库druid主要包含十张表,均以“druid_”开头,如图-3.7所示。
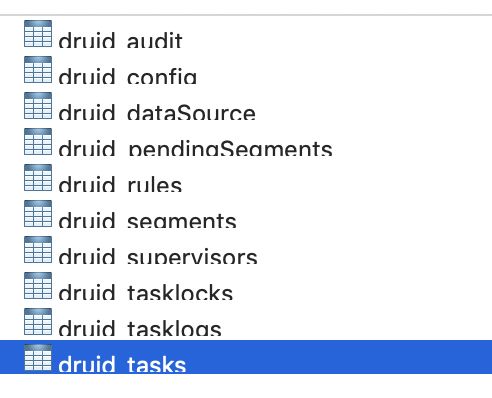
(1) Load/Drop Segments规则表 druid_rules
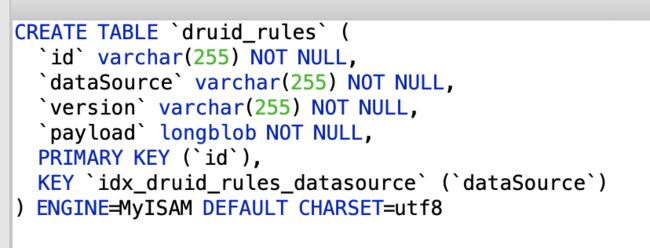

我们通过访问http://
在生产环境中,我们建议大家,不要直接在表中操作规则,以免出现各种未知问题。
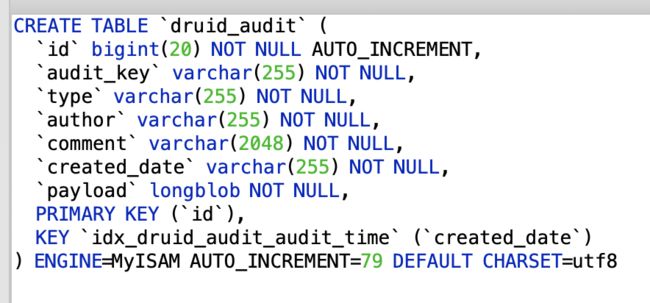
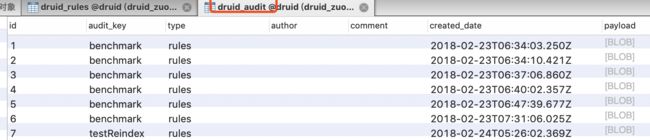
(2)规则审计表druid_audit。记录Load/Drop Segment规则的审计信息
(3)Index Service配置表 druid_config
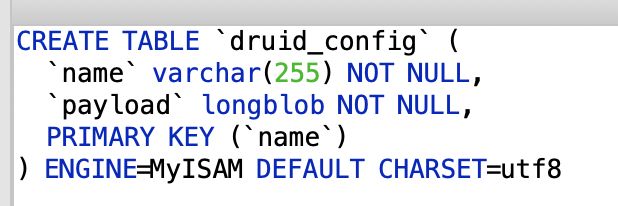

Overload作为Indexing Service的Master节点,可以动态改变Peon运行配置。举例说明,如图3.13所示。我们在使用Druid时,通过JSON over HTTP的方式向http://
(4)数据源表druid_dataSource
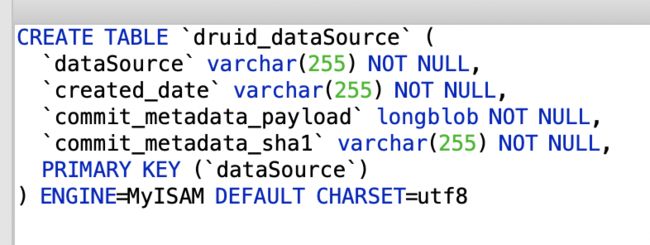
如果使用druid_0.9.1.1新特性Kafka IndexingService,如图3.14所示,那么该表会保存每个datasource对应的Kafka Topic信息,一级改Topic下所有Partitions已被消费的offset。
(5)Segment元信息表druid_segments
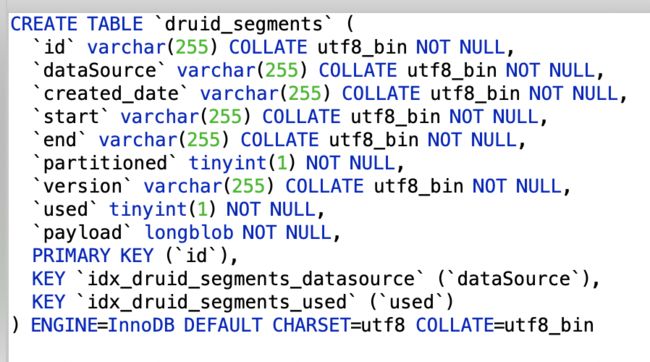
该表中有一个used字段,是用来标识此segment是否被使用,如果某个datasource配置了规则,那么Druid只会采用逻辑删除,即应把对应的segment的used置为0,而不是物理删除。
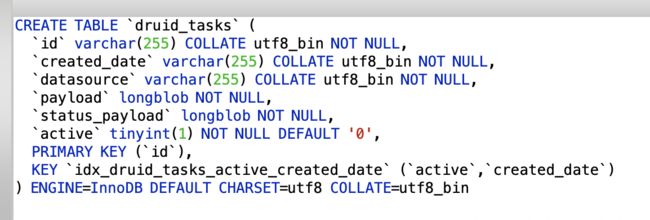
(6)任务表druid_tasks。其中,图3.18是druid_0.9.1.1版本新增的kafka indexing service tasks。
(5)Segment元信息表druid_segments
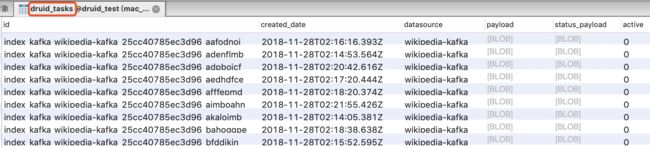
(7)任务锁表druid_tasklocks
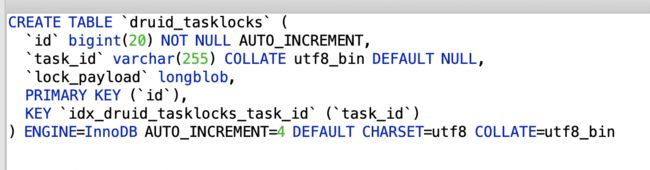
(8)等待队列中的索引任务表druid_pendingSegments
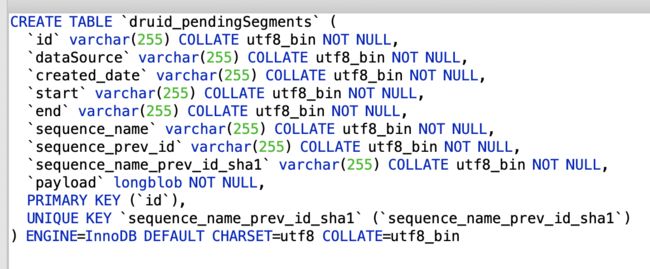
(9)索引任务日志信息表druid_tasklogs
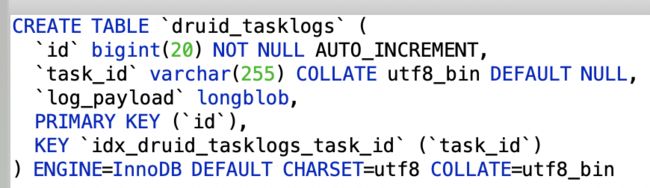
(10)KafkaIndexingService对应supervise表 druid_supervisors
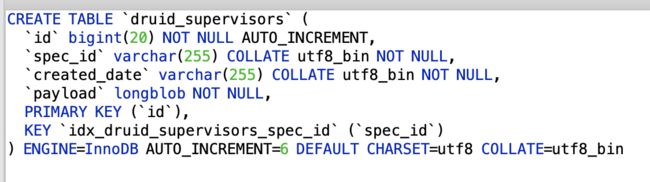
9.加载数据
对于加载外部数据,Druid支持两种模式:实时流(real-time ingestion)和批量导入(batch ingestion)。
Real-Time Ingestion 实时流过程可以采用Apache Storm、Apache Spark Streaming等流式处理框架产生数据,再经过pipeline工具,比如Apache Kafka、ActiveMQ、RabbitMQ等消息总线类组件,使用Stream Pull 或者Stream Push模式生成Indexing Service Tasks,最终存储在Druid中。
Batch Ingestion 批量导入模式可以采用结构化信息作为数据源,比如JSON、Avro、Parquet格式的文本,Druid内部使用Map/Reduce批处理框架导入数据。
10.高可用性
Druid高可用性可以总结以下几点:
Historical Node 如前所述,如果某个Historical Node离线时长超过一定阈值,Coordinator Node会将该节点上已加载的Segments重新分配到其他在线的Historical Nodes上,保证满足加载规则的所有Segments不丢失且可查询。
Coordinator Node 集群可配置多个Coordinator Node实例,工作模式为主从同步,采用选举算法产生Leader,其他Follower作为备份。当Leader宕机时,其他Follower能够迅速failover。
即使当所有Coordinator Node均失效,整个集群对外依然有效,不过新Segments不会被加载,过期的Segments也不会被丢弃,即整个集群内的数据拓扑会一直保持不变,直到新的Coordinator Node服务上线。Broker Node Broker Node与Coordinator Node在HA部署方面一致。
Indexing Service Druid可以为同一个Segment配置多个Indexing Service Tasks副本保证数据完整性。
Real-Time Real-Time过程的数据完整性主要由接入的实时流语义(semantics)决定。我们在0.9.1.1版本前使用Tranquility-Kafka组件接入实时数据,由于存在时间窗口,即在时间窗口内的数据会被提交给Firehose,时间窗口外的数据则会被丢弃;如果Tranquility-Kafka临时下线,会导致Kafka中数据“过期”从而被丢弃,无法保证数据完整性,同时这种“copy service”的使用模式不仅占用大量CPU与内存,又不满足原子操作,所以在0.9.1.1版本后,我们使用Druid的新特性Kafka Indexing Service,Druid内部使用Kafka高级Consumer API保证exactly-once semantics,尽最大可能保证数据完整性。不过我们在使用中,依然发现有数据丢失问题。
Metadata Storage 如果Metadata Storage失效,Coordinator则无法感知新Segment的生成,整个集群中数据拓扑亦不会改变,不过不会影响老数据的访问。
Zookeeper 如果Zookeeper失效,整个集群的数据拓扑不会改变,由于Broker Node缓存的存在,所以在缓存中的数据依然可以被查询。
参考:
http://druid.io/docs/latest/design/index.html
https://blog.csdn.net/paicmis/article/details/72625404
https://blog.csdn.net/njpjsoftdev/article/details/52955676
https://blog.csdn.net/njpjsoftdev/article/details/52955937