Python自带的re模块提供了对正则表达式的支持。
1.Pythonre模块中的一些元字符及其表示的意义
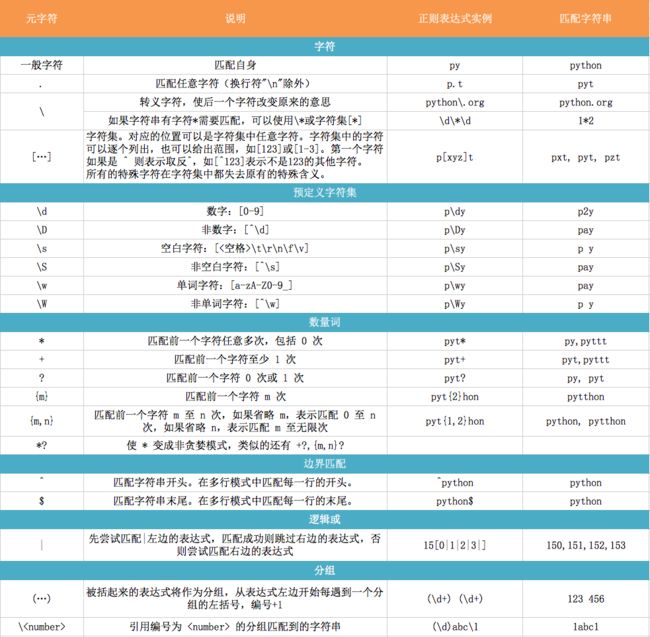
python 正则表达式元字符
几点说明:
(1)python正则匹配模式默认采用贪婪匹配,即匹配越多越好。
In [17]: import re
In [18]: s='abbbbc'
In [20]: re.match('ab*',s)
Out[20]: <_sre.SRE_Match object; span=(0, 5), match='abbbb'>
In [21]: re.match('ab?',s)
Out[21]: <_sre.SRE_Match object; span=(0, 2), match='ab'>
In [22]: re.match('ab*?',s) #特殊例子
Out[22]: <_sre.SRE_Match object; span=(0, 1), match='a'>
(2)转义字符''用来关闭元字符的特殊意义,而在python正则表达式中r'rawstring'同样可以关闭元字符特殊意义,使其仅作为一个字符。
In [29]: print('\\')
\
In [30]: print(r'\\')
\\
In [31]: print('\\d')
\d
In [32]: print(r'\d')
\d
2.Python re模块常用方法
re.complile(pattern) #编写正则匹配模式
re.match(pattern, text) # pattern为正则表达模式,text为要查找的字符串,会返回一个match对象,从头匹配,开头没有则返回None,
可用re.match(pattern, text).group()方法取出匹配到的对象
re.search(pattern, text) # 只要在text中找到了pattern就返回,只返回第一个匹配到的pattern的位置
re.findall(pattern, text) # 将能匹配到的以list的方式全部返回
re.finditer() # 返回一个包含了所有的匹配对象的迭代器
# 迭代器中的每一个迭代对象都有span(),start(),end()方法,可以返回匹配结果的位置
re.split(pattern, text) # 按照pattern匹配,并且以匹配到的字符为分隔符切割text,返回一个切割后的list
re.sub(pattern, s, text) # 替换,将pattern匹配到的字符替换为s
3. 匹配对象的操作方法
group() 返回正则表达式匹配到的字符串
start() 返回匹配的起始位置
end() 返回匹配的结束位置
span() 返回一个包含匹配的起始位置和结束位置的元组(start, end)
4. 重复匹配一个字符串多次
string = 'asdasdasdasdasdasdasddasfdhgasghsd'
print(re.findall(r'((?:asd)+)', string))
# 解释下
# (?:asd)+ 是正则的一种不存分组的语法, 它具有2个用途, 将`asd`看成一个样式整体, 所以当我们用+时, 就能代表多个asd
# () 最外层的括号就是将匹配的结果存入分组, 与上面不同的就是, 少了`?:`, 因为没有这个, 所以它能存到分组
# 所以整体的结果就是: 将多个asd匹配, 并存入分组, 然后在re.findall的结果就能看到了