1.Volley源码分析(一)
2.Volley源码分析(二)
3.Volley源码分析(三)
4.XVolley-基于Volley的封装的工具类
第一次一行一行读源码,记录下来,慢慢来
1.Volley.class
用过Volley的都知道使用Volley的第一步需要使用Volley.newRequestQueue方法创建一个RequestQueue。所以就从这开始吧。
public class Volley {
/** Default on-disk cache directory. */
private static final String DEFAULT_CACHE_DIR = "volley";
/**
* Creates a default instance of the worker pool and calls {@link RequestQueue#start()} on it.
*
* @param context A {@link Context} to use for creating the cache dir.
* @param stack An {@link HttpStack} to use for the network, or null for default.
* @return A started {@link RequestQueue} instance.
*/
public static RequestQueue newRequestQueue(Context context, HttpStack stack) {
//建立缓存
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
String userAgent = "volley/0";
try {
String packageName = context.getPackageName();
PackageInfo info = context.getPackageManager().getPackageInfo(packageName, 0);
userAgent = packageName + "/" + info.versionCode;
} catch (NameNotFoundException e) {
}
/**
* 策略模式
*/
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
//大于2.3则建立HurlStack
stack = new HurlStack();
} else {
// Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
//小于2.3版本则建立HttpClientStack
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
/**
* 创建一个网络请求
*/
Network network = new BasicNetwork(stack);
/**
* 这里每次都会创建一个请求队列
*/
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
queue.start();
return queue;
}
/**
* Creates a default instance of the worker pool and calls {@link RequestQueue#start()} on it.
*
* @param context A {@link Context} to use for creating the cache dir.
* @return A started {@link RequestQueue} instance.
*/
public static RequestQueue newRequestQueue(Context context) {
return newRequestQueue(context, null);
}
}
首先大体看,这里newRequestQueue方法使用了重载,提供两种方式创建RequestQueue。实际上最后执行的都是newRequestQueue(Context context, HttpStack stack)方法。详细看下这个方法。
第一步
建立缓存,可以看到这里利用文件流建立了缓存。
第二步
这里是个重点,当没有HttpStack == null时,这里对版本进行了判断,大于等于2.3则创建HurlStack,小于则创建HttpClientStack。两种的区别网上可以搜,大体就是2.3前HttpClientStack使用的HttpClient拥有较少的bug,2.3以后HttpURLConnection拥有更小的体积,更多的api,更多的优化。
tips:记得这里曾经有一次面试问到用到了什么设计模式,现在补一下,用到了策略模式。
这里分析一下:
HttpStack.class
public interface HttpStack {
/**
* Performs an HTTP request with the given parameters.
*
* A GET request is sent if request.getPostBody() == null. A POST request is sent otherwise,
* and the Content-Type header is set to request.getPostBodyContentType().
*
* @param request the request to perform
* @param additionalHeaders additional headers to be sent together with
* {@link Request#getHeaders()}
* @return the HTTP response
*/
HttpResponse performRequest(Request request, Map additionalHeaders)
throws IOException, AuthFailureError;
}
可以看到HttpStack是一个接口,定义了performRequest方法,而HurlStack和HttpClientStack则实现了这个接口,分别实现了不同的实现方式。对应在不同的版本判断时调用将实现不同的类。这里提供下《HeadFrist 设计模式》读书笔记 —— 策略模式博客里面的类图
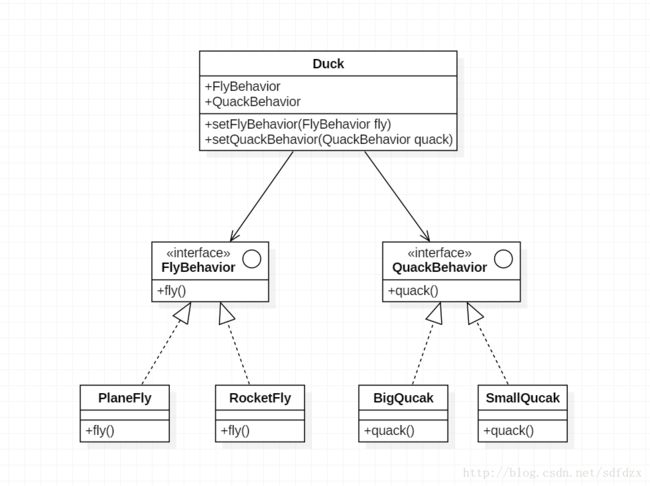
所有综上所述,这里用到的是策略模式。
第三步
创建了一个网络请求,这个后面会分析这两个类,现在只要知道这个类的作用是真正执行网络请求的地方。
第四步
创建了一个请求队列,并执行请求队列的start方法。这里可以看到每次都会创建一个请求队列其实不是特别合适的,这里可以考虑优化使用单例模式公用一个队列