1、前言
从直播在线上抓娃娃,不断变化的是玩法的创新,始终不变的是对超低延迟的苛求。实时架构是超低延迟的基石,如何在信源编码、信道编码和实时传输整个链条来构建实时架构?在实时架构的基础之上,如果通过优化采集、编码、传输、解码和渲染中的关键环节来降低延迟?本文将会介绍即构在这方面的思考与实践。
学习交流:
- 即时通讯开发交流群:320837163 [推荐]
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
(本文同步发布于:http://www.52im.net/thread-1465-1-1.html)
2、关于作者

关旭:即构科技音视频引擎核心专家,硕士毕业于南开大学数学系,先后就职于中兴通讯、腾讯等公司负责音视频相关的研发工作,在实时音视频技术上有多年积累,当前在即构科技主要负责音视频引擎核心开发。
3、相关文章
《实现延迟低于500毫秒的1080P实时音视频直播的实践分享》
《移动端实时视频直播技术实践:如何做到实时秒开、流畅不卡》
《移动端实时音视频直播技术详解(六):延迟优化》
《如何优化传输机制来实现实时音视频的超低延迟?》
《首次披露:快手是如何做到百万观众同场看直播仍能秒开且不卡顿的?》
《七牛云技术分享:使用QUIC协议实现实时视频直播0卡顿!》
4、从直播到线上抓娃娃

图 1 展示了实时音视频两种不同的应用场景——连麦互动直播和线上娃娃机。虽然这两种都是互动,但是对于实时音视频的要求却不同。第一个实时连麦是语音视频流的互动,例如其中一个说了一句话,另外一个人听到了,再回复一句话,这个实时性只是对语音视频流的实时性要求很高。而第二种线上抓娃娃则对信令的延迟提出了更高的要求,操纵者无需说话,看到的是娃娃机传回来的视频流结果。
如果考量互动直播是用实时音视频的延迟,那么线上抓娃娃则是用信令和视频流的延时。随着时代的发展,我们对实时语音视频的定义会慢慢有一些不同,将来可能还有更多的因素需要考虑。
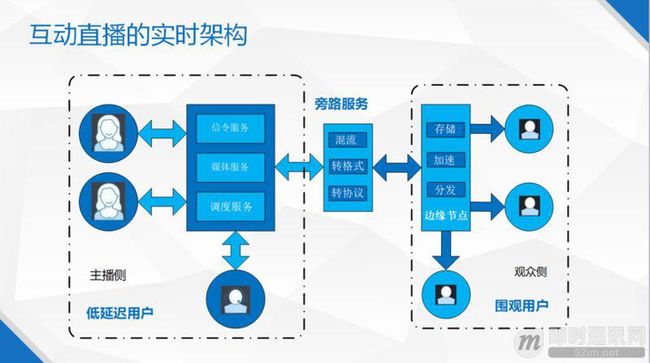
图 2 是我们互动直播的实时架构图,我们把互动直播分为两部分,一个是主播侧,需要更低的延迟,另一侧是普通观众,对延时不太敏感,但对流畅性敏感,中间通过一些旁路的服务把这两个集群(一个集群叫超低延迟集群,另外一个集群叫围观集群)连接起来。
在超低延时部分,我们提供的服务包括流状态更新、房间管理等,以及一些流媒体服务,主要起到分发的作用。我们通过超低延迟服务器集群(和观众侧不太一样),提供实时分发的功能。
此外还提供了动态调度的服务,帮助我们在现有的资源网络上找到更好的链路。后面的观众集群是另外一个集群,把它们分开是出于一些业务方和我们自己成本上的考虑,另外会提供存储、PCB 加速、分发的功能。
中间的旁路服务包括混流、转格式(主要是转码)、转协议等。为什么要混流?举一个比较简单的例子:当主播一侧有 9 个人连麦,如果没有混流服务,观众端就会同时拉 9 路音视频,这样对带宽压力很大。
普通观众是通过围观服务器集群(延迟相对大的集群)去拉这些流的,这个集群的延迟可控性相对比较弱,有可能会出现这 9 路画面之间的不同步现象,通过混流服务,观众拉的都是合成好的音视频流,就不会出现各路流之间的不同步问题。
还有转格式转码的服务,前面集群提供的是很低延迟的服务,里面一些,比如说编码码流,不能够在传统的 CDN 网络分发,如果想在传统的 CDN 网络上分发,就要服务端的转码。还有就是转协议,因为前面提供一个更低延时的服务,后面要在 CDN 网络上分发,所以协议也需要转。
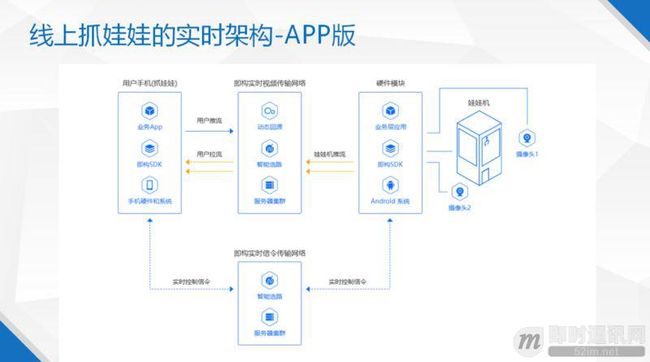
图 3 是线上娃娃机的 APP 版本的架构图,这里的是特色是线上娃娃机可以实时推两路视频流,上机玩家可以随时任意去切其中一路画面去看。这两路视频流首先通过我们超低延时服务器集群,同时上机玩家也可以推一路流上去,可以给围观观众方看到这个人在抓娃娃时候的一些表情、反应、语言,增加一种互动性。此外,玩家需要通过手机远程操控娃娃机,因此还需要实时信令的分发。
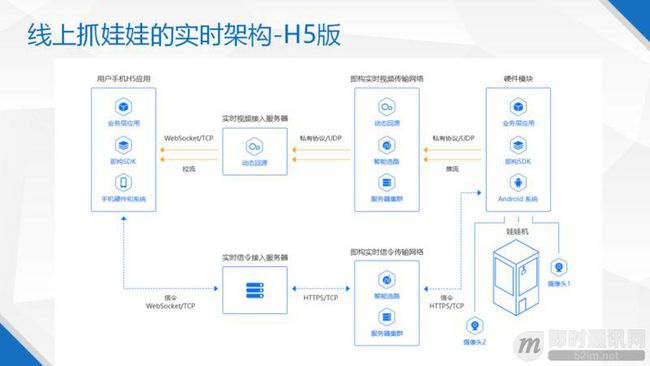
接下来是娃娃机的 H5 架构图(图4)。在推流方面和 APP 版本没有太大的区别,娃娃机一侧还是走的私有协议。不同的地方是因为私有协议没有办法直接让 H5 拉到流,所以中间会加入一个媒体网关,作用是把我们的私有协议翻译成 H5 可以识别的码流格式,然后 H5 端通过 websocket 方式把这路流拉下来,这里需要媒体网关做到超低延时的转换。
简单来看,这里的网关服务器只是做了一个分发服务,好像不会引入延时,实际上不然。
因为 websocket 拉的是 TCP 的流,但是我们推的是 UDP 的,当视频帧很大的时候,一个帧数据就要切割成很多 UDP 包上行,服务器需要将这些 UDP 包攒起来,凑成一个完整的帧后才下发给 H5,这样才能保证不花屏,才能跑得通,所以这个攒包组帧的过程是会有延迟的。信令部分和 APP 部分基本是相似的。
5、实时架构的若干点思考
刚才介绍了实时音视频的两种场景,下面提出一点思考:
1)实时音视频有什么样的特征?
2)怎么样去架构一个实时音视频系统?
这是仁者见仁,智者见智的问题。你可以通过很多方式把这个系统架构起来,都会达到相对不错的效果。但是我认为,无论怎样,实时音视频都有绕不过如下几个点,只有把它们做好了,才能够在业界有更高的知名度、更好的技术储备。
第一是实时音视频是不能等的:
因为等了就不是实时音视频了。 不能等,这里会引入一个矛盾。既然不能等,例如你把实时音视频也看作一个消费模型来看,那是提前生产还是按需生产?字面上理解很简单,肯定是按需生产,需要的时候才生产,如果提前生产就是延时了。但是并不是每一个点都做成按需生产是合理的。
举一个例子,比如你要去播放一段音频,最好的做法是系统或者驱动告诉你,它需要数据了,然后去解一帧塞给它,这就是按需生产。但是为什么还有提前生产一说呢?就是系统告诉你它要数据的时候,实际上它有一个对响应周期的要求。
你现去生产可能就要等去解完一帧,但是这个时候来得及吗?如果你只有一路下行,可能就来得及。但是现在要求很多路下行,在很短的时间周期内解很多帧,对硬件性能有很高的要求。通常来讲,并不可取。这只是实时音视频中一个简单的例子。提前生产会引入延迟的,那么到底要提前多久生产,怎么样动态估计我们什么时候应该生产?这是一个开放性的问题,也是一个大家在设计系统时要重点考虑的。
第二是实时音视频不能久等:
实时音视频中有些等待是避免不了的,例如你要做音频编码,它本来一定要 20 毫秒一帧或者 40 毫秒一帧去做,给一个采样点点是编不了的。这里既然有些延迟和等待避免不了,我们当然希望系统处理的粒度越低越好,这样可能会带来更低的延时。但是处理的粒度越低,整个系统在频繁跑的时候,你可以认为它是一套循环,当循环的东西很少,这个循环就会跑很多次,对系统来说就是一个很大的开销和负担。
所以不能久等的时候,我们当然希望它处理粒度小。另外处理粒度小还有一个优势,在整个系统中并不能保证每一个环节的处理粒度是一致的。例如这个节点可能要求是 10 毫秒,下一个结点要求 15 毫秒,这是由于算法的限制,可能没有办法避免。如果在整个系统内选一个相对小的粒度,在粒度拼接的时候,例如 10-15 毫秒,要两个 10 毫秒才能够 15 毫秒,还剩下 5 毫秒,剩的就比较少。
如果粒度很粗,可能剩下的东西就很多。在粒度拼接的时候,这个剩余的量代表了整个链路中的延迟。所以我们希望处理粒度尽量小,但是又不能小到整个系统没有办法接受的粒度。
第三是实时音视频不能死等:
例如你需要接收一个网络包的时候,这个包迟迟不到,这个时候你不能完全不等,完全不等就会卡。但是在等的时候有一个超时的机制,例如这个音频包就是很久不到,就把它跳过去做一个纠帧补偿,当包最终还是到了的时候,我也只能把它扔掉,而不应该把它利用起来。
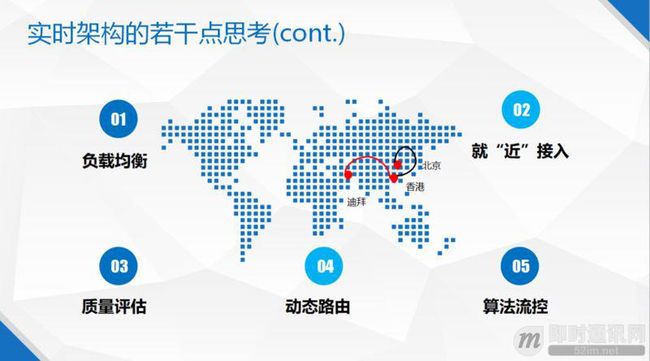
此外,实时音视频在服务器端还需要深入考虑这样几个问题:
第一是负载均衡;
第二是就近接入;
第三是质量评估;
第四是动态路由;
第五是算法流控。
负载均衡:是说让整个服务器的每一个节点都承担相对均匀的服务,不至于使得某一个节点负载过高造成一些丢包,造成网络往返时的增大,这样对任何的网络损伤来讲,对实时音视频都会造成比较大的延迟增加。
就近接入:这里的“近”并不是指地域上的近,而是“网络上的近”。很简单的例子,我们在深圳做推流,香港离得很近,可以推到香港的服务器,但实际上这毕竟是一个跨域的网络,有不稳定的因素在里面,所以我们宁愿推远一点。这个近指的应该是在网络质量评估意义上的近,例如网络往返时很小、往返时很平稳、分布在延迟比较大的时刻不会还具有很大的概率,丢包率很低等。
要做到就近接入,这个近要有一个很好的质量评估体系,质量评估方法有两种:
事后质量评估:在复盘的时候,例如这个网络平稳的运行了一个月,复盘看一下整个月中的质量怎么样,这样的质量评估可以认为是一个相对离线的评估,它能够给我们提供一个指标,最近一个月的网络和上个月相比是否有所改善。我们可以从中学习到一些经验,例如这个月和上个月的调度上有些策略上的不同。这是一个系统化的经验总结和优化的方法。
实时质量评估:更重要的应该是一个实时上的评估,例如我现在推流,能够实时监控到当前的质量是怎么样的,就可以做到实时动态路由。实时动态路由是说某个人推流从北京推到迪拜,有很多链路可以选,他可能根据之前的一些经验,假如他之前经验告诉你,直接推到迪拜,这个链路是很好的,但是毕竟有个例。有动态实时的质量评估,就知道这个时候推迪拜是否好,如果不好,可以在用户无感知的情况下更换,随时增减整个链路中一些路由的节点。这就是动态路由的思路。
实时动态路由:是说某个人推流从北京推到迪拜,有很多链路可以选,他可能根据之前的一些经验,假如他之前经验告诉你,直接推到迪拜,这个链路是很好的,但是毕竟有个例。有动态实时的质量评估,就知道这个时候推迪拜是否好,如果不好,可以在用户无感知的情况下更换,随时增减整个链路中一些路由的节点。这就是动态路由的思路。
实际情况中是结合前面这 4 个点,在我们的网络和服务器资源集中,去选出质量最优或者近似最优的链路来保证实时音视频的服务的。但是资源集是有限的,没有人可以保证你的资源集中一定可以选出的这个最优具有很好的链路特征。保证不了就要考虑第五点,我即使选出了一个认为是整个资源集中最优的链路,但是它的质量还达不到很好的标准,就要通过一些算法才能弥补。这些算法包括在一个不可靠的网络中怎么样进行可靠的音视频传输的技术,这些技术在接下来我们会和大家稍微分享一下,也包括整个链路的一些拥塞控制。
6、关于信源编码的思考

信源编码是为了减少网络中的负担,把大量的数据压缩成比较小的网络数据,来减少网络负担的方式。压缩方式有很多种,我们先以音频来看,上面画了一些图(图 6)。
我们重点看 Opus 编码器,它有几种模式在里面:
一种是线性预测模式;
还有一种是混合模式;
另一种是频域编码模式。
混合模式是把两种编码模式混合在一起,根据不同的情况进行选择。
图 6 是一个编码器,横轴是码率,纵轴是它的质量,中间是各种音频编解码器的表现。你会发现线性预测的方式能够在低码率上提供比较好的质量,但是在 20K 左右的时候就没有曲线了,因为它不支持那么高的码率。然后看 MDCT 编码,它可以在比较高的码率上达到近似透明的音质。音频编码器是有不同的编码原理在里面的,像这种 LP Mode 是模拟人的发声模型,既然有了数学建模,它的特征是能够在一个比较低的码率上提供一个比较可靠的质量。
但是它的特点是容易达到一种质量上的饱和,也就是说当你码率给它很高的时候,实际上它也就编的效果还是那样,因为它毕竟是一种参数化的编码。所以根据业务场景,当你需要一个很高的音质,又需要音乐场景的时候,选择它明显不合适。MDCT MODE 没有任何的模型在里面,实际上就是把信号转换成频域,直接去量化。既然没有模型化,它是比较消耗码率的,但是它可以在一个较高的码率上提供很好的质量,可是低码率的表现远远不如模型化的方法。
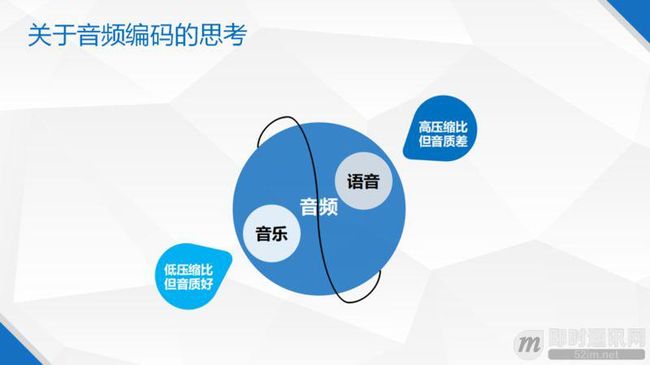
整体总结起来,音频包括语音和音乐两种,因此有适合语音的 codec 和适合音乐的 codec:
第一种 codec 适合语音,语音可以模型化,适用于语音的 codec 能够在低码率上提供很好的质量,提供一个相对高的压缩比, 但是它容易达到饱和,不能够提供一个近似于透明的音质;
另外一种 codec 的编码原理不一样,能够把音乐、语音都编得很好,但是特点是不能够提供太高的压缩比,指望它能够在低码率下提供很高的编码质量是做不到的。

关于视频编码,最简单的几个点有 I 帧、P 帧、B 帧。I 帧是自参考,P 帧是向前参考,它会参考历史帧的特性进行编码。B 帧是双向参考,它可以参考前面的帧,也可以参考后面的帧。B 帧可以带来更高的压缩比,提供更好的质量。但是因为它会参考将来的帧,所以会引入延迟,因此我们在实时音视频系统中是很少用到 B 帧的。
想要做好实时的音视频系统,流控是一定要做的,流控对视频的编解码有什么要求?至少有一点,编解码器的码控一定要很稳定。为什么?举例说,我现在有一个很好的拥塞控制策略,带宽估计做得很好,一点差错都没有,估计出某一个时刻可分配视频的带宽就是 500kbps,就可以让视频编码器设置成 500kbps。但是,如果码控不是很稳定,你设置 500kbps 的时候,视频编码器可能就跑到 600kbps 了,这样就会带来一些阻塞和延迟。因此,我们希望选择的 codec 具有很好的码控策略。
实际上一些开源代码都是有做码控的,但是直接拿来用并不是适合你的场景,因为这些开源代码做起来,可能或多或少的考虑其他的场景,并不只是实时音视频场景。比如说某个 codec 是用来压片的,希望半个小时或者一个小时之内达到预定的码率就可以,不会管这一秒钟或者下一秒是什么样子的,但是实时音视频就是要求要把时间窗做得很小。
另外我们希望 codec 有分层编码的能力。什么是分层编码?为什么要有分层编码?分层编码也分两种,一种是时域上的分层,一种是空域上的分层。前者是编码的时候是当前帧不参考上一帧,而是有隔帧参考的策略;后者可以认为使用较低的码率先编码一个小的画面,然后使用剩余的码率编码增量的部分,得到更高分辨率的画面。
为什么要这样做?实时音视频中并不是很多场景都是一对一的,当不是一对一,要做流控的时候,不可能因为某一路观众的下行不好,就把主播上行推流的码率降下来,因为可能还有一千个观众的网络很好,这些网络好的观众也会因为个别观众网络不好,而只能看到不那么清晰的画面。所以要分层,可以在服务器端选择给用户到底下发哪一层的,因为有分层策略,如果这个人线路不好,只要选择其中一个比较小的层次发给他就可以了,例如核心层,这样可以紧紧利用核心层把整个视频还原,可能会损伤一些细节或者帧率偏低,但是至少整体可用。
最后,我想说一下,很多人认为,视频的数据量很大,视频的延时比音频应该更高才对,实际上不是。因为很多的延迟实际上是编解码自有的延迟,如果编解码中没有 B 帧的话,你可以理解为视频编码是没有任何延迟的。但是音频编码或多或少都会参考一些将来的数据,也就是说音频编码器的延时一定是存在的。因此,通常来讲,音频的延时比视频的延时更高才对。
7、关于信道编码技术的思考

信道编码分几个部分:一种是根据先验知识的网络冗余编码技术——前向纠错技术。以 RS(4,6)编码为例,我要发一个分组,这个分组有六个包,其中有四个包是实际媒体数据,有两个包是冗余包。那么在解码端收到六个包中任意的四个,就可以完全恢复所有携带媒体内容的包。
例如这里 2、3 都丢了,收到了 1、4、r1、r2,也能够完全恢复 2 和 3。这样看来很好,任意两个丢掉都可以完全恢复。但是这样的算法也有它的弱点,不太适合突发性的丢包。因为这个分组不宜太大,如果分组很大,分组就有很大的延时。分组如果很小,很可能整个分组都丢掉了。
实际上这种做法就没有任何意义。所以它不太适合突发性丢包,而且它毕竟是根据先验知识去做的一种冗余,也就是说它永远是根据上一时刻网络的状态作出的判断,下一时刻网络是什么样的,是预测的东西。网络是实时发生变化的,这种预测的东西并不完全可靠。
所以它恢复的效率在实际网络中相对比较低,而且这样的算法复杂度相对比较高。当然它也有优势,例如我们是提前算好的,一次性发过去,不需要等到你发现丢包时我再做怎样的冗余传输,所以不受网络往返的影响。而且这种分组可以任意、随机调整大小冗余度,比较适合均匀丢包的场景。
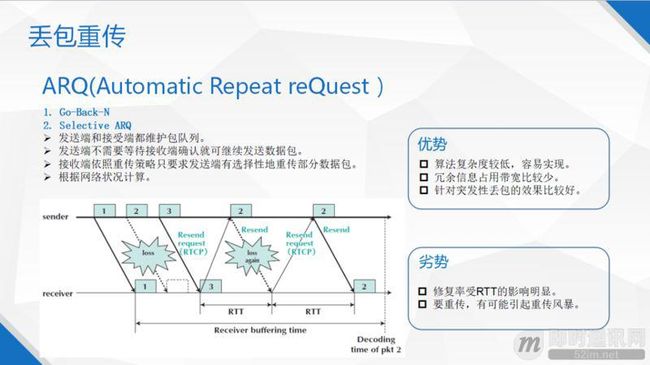
另外一项技术是丢包重传技术:相对来说,丢包重传相对 RS 来讲,更有针对性,所以恢复效率比较高。第一个 Go Back N 技术是类似于 TCP 的传输技术,发送端在不断的发包,接收端要负责告诉发送端我现在收到包的情况是怎么样,收到的连续的帧的是序列号什么样的。发送端发现发了 10 个帧,接收端只正确收到 8,不管 9 号包或者 10 号包是否收到,都会丢包重传。所以 Go Back N 技术有一定的目的性,维护的是丢包状态,它知道哪些包是没有收到的,但是并不精准。
接下来是自动选择重传技术(Selective ARQ):选择性的重传,是在接收端发现了哪个包丢了,然后才会让发送端重新发送这个包。听起来是非常好的一个技术,效率很高,丢了哪个包就重传哪个包。但是它的弱点在于,你必须要假定这个包是频密的发送才可以。例如发送端发出 1、2、3、4 这样的包,但是一秒钟才发一个包,什么时候发现 2 丢了呢?收到 3 的时候。如果 2 作为最后一包,永远发现不了丢掉了。也就是如果发包不频密,至少需要 1 秒钟才发现它丢。这个时候再让它重传,就很晚了。
所以在一个真实的系统中,选择性重传是首选,因为音视频的大部分场景是频密的,但是可能也要结合一些 Go-Back -N 的做法。发一些确认机制,这样才能把重传做得更加完备。另外所有的重传都要至少等一个网络往还时,因为无论是确认丢包还是反馈收包情况,都需要一个网络往返时,所以它的弱点是,它受网络往返时影响比较大,如果控制不好,有可能造成重传风暴。优势是算法计算复杂比较低,且容易实现。另外,因为它有很大的针对性,无效的重传包会比较少,针对突发性的丢包会有比较好的效果。
刚才讲了针对不可靠网络的两种传输技术,前向纠错和丢包重传,它们都有各自的优点和缺点。实际上一个好的网络分发技术应该是将这两种结合在一起的,根据不同的信道情况把这两种技术结合在一起。

图 11 来自于网络,首先从左下角蓝色部分看起,当网络往返时很小,丢包率不高的时候就用重传。但是当网络 RTT 很高的时候,在这个图里面去看,就没有选用重传策略。从我个人的角度来看,我认为这并不是一个非常合理的做法。因为刚才提到了,FEC 是一个无目的性的、根据先验知识去做的一种冗余技术,虽然当 RTT 很高,重传很耗时,但如果没有重传,要加很多冗余包,才能把丢掉的包完全恢复,实际就会带来很大的资源浪费。而且当你丢包率很高的时候,可能还并不能够完全恢复所有包。视频只要丢帧就会很卡,视频丢包率应该控制在千分之几以下,才可以达到顺畅的可以观看的水平。
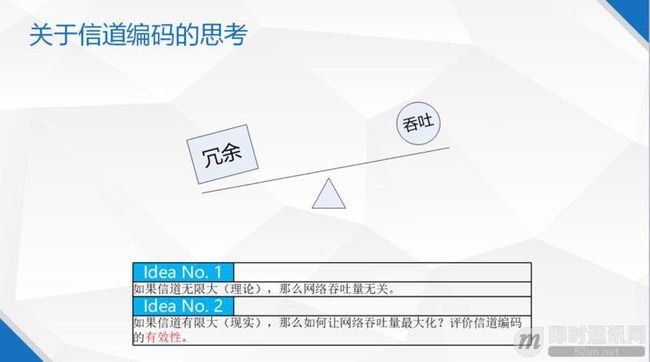
关于信道编码的思考:信道编码和网络吞吐呈反比关系。无论是重传性编码还是冗余性编码,都会占用带宽,从而减低实际媒体信息的吞吐量。现实的生活中,信道都有限制。当你传输的时候,就要根据信道的特征去做一些策略。信道如果有拥塞,我们就需要有一个拥塞控制的算法,去估计应该把整个信道怎么样做合理分配。
另外,在做一个系统的时候,想清楚如何去评价一个系统的效果是很重要的一个点:在信道编码的时候,一个很重要的指标是,信道编码的有效性是什么样子的。有效性分为两种,一种是重传或者冗余能否真的把丢掉的包补回来,这是一个有效性。即使这个包补回来了,但是如果经过一个信道编码策略之后,还有一些丢包。
例如原来的丢包是 20%,补回来变成 1%,那么这个重传在我们的评价当中实际上是没有效果的,因为 1% 的丢包对音频来讲是无所谓的,但是对视频来讲是很卡的。在这样的评价系统中,补回来还有 1% 的丢包,那么所有的编码都是没有太大意义的。举这个例子,如果在这时信道也发生拥塞,再进行这样的信道编码,就不会达到很好的效果。这个时候是否应该停止所有的信道编码呢?
还有信道编码有效性的判断:衡量它是否好,就是加了多少冗余,冗余中有多少没有被利用好,如果这些冗余像刚才那个例子那样,6 包带 2 包的冗余,刚好丢掉 2 包,整个包都恢复出来了都使用到了,那就是百分之百的冗余都有效。如果 4 包信息丢了 1 包,却带了 2 包荣誉,其中 1 包就没有效果。所以想要做一个好的系统,应该先想到如何评价这个系统的好坏。
8、引入延迟的环节和降低延迟的思路
延迟的引入主要分三部分。
1)一个是采集 / 渲染:这好像是很简单一个部分,但是它引入延迟可能是最大的,可能是整个分发过程中最大的环节。
有很多人不是特别理解,但实际上在我们现有的网络结构中,网络往返时的延迟都控制在 50 毫秒以内,但是渲染和采集,尤其是渲染,几乎没有任何移动端系统可以保证它百分之百的 50 毫秒,这是一些硬件上的限制。如何去降低这些延迟?刚才我已经举了一个生产消费模型的思路,到底是按需生产还是提前生产,这些都是可以仔细去考虑的。
2)还有编解码会带来一些延迟,尤其是音频会带来一些延迟:这些延迟中有些是避免不了的,我们就要根据实际的使用场景去减少这些延迟,这些都是要在具体形态上做一些权衡的东西。还有处理粒度上的考虑,也会影响整个系统的延迟。
3)还有一个延迟,大家都能看到的,就是网络分发延迟:如何去减小?除了在资源集中找到一个最优子集之外,还有信道编码的东西,要做一个很好的信道编码系统,我们如何评价信道编码系统的好坏。有了这些思路之后,可以指导我们去做更好的下一步的开发工作。
附录:更多实时音视频技术文章
[1] 开源实时音视频技术WebRTC的文章:
《开源实时音视频技术WebRTC的现状》
《简述开源实时音视频技术WebRTC的优缺点》
《访谈WebRTC标准之父:WebRTC的过去、现在和未来》
《良心分享:WebRTC 零基础开发者教程(中文)[附件下载]》
《WebRTC实时音视频技术的整体架构介绍》
《新手入门:到底什么是WebRTC服务器,以及它是如何联接通话的?》
《WebRTC实时音视频技术基础:基本架构和协议栈》
《浅谈开发实时视频直播平台的技术要点》
《[观点] WebRTC应该选择H.264视频编码的四大理由》
《基于开源WebRTC开发实时音视频靠谱吗?第3方SDK有哪些?》
《开源实时音视频技术WebRTC中RTP/RTCP数据传输协议的应用》
《简述实时音视频聊天中端到端加密(E2EE)的工作原理》
《实时通信RTC技术栈之:视频编解码》
《开源实时音视频技术WebRTC在Windows下的简明编译教程》
《网页端实时音视频技术WebRTC:看起来很美,但离生产应用还有多少坑要填?》
>> 更多同类文章 ……
[2] 实时音视频开发的其它精华资料:
《即时通讯音视频开发(一):视频编解码之理论概述》
《即时通讯音视频开发(二):视频编解码之数字视频介绍》
《即时通讯音视频开发(三):视频编解码之编码基础》
《即时通讯音视频开发(四):视频编解码之预测技术介绍》
《即时通讯音视频开发(五):认识主流视频编码技术H.264》
《即时通讯音视频开发(六):如何开始音频编解码技术的学习》
《即时通讯音视频开发(七):音频基础及编码原理入门》
《即时通讯音视频开发(八):常见的实时语音通讯编码标准》
《即时通讯音视频开发(九):实时语音通讯的回音及回音消除概述》
《即时通讯音视频开发(十):实时语音通讯的回音消除技术详解》
《即时通讯音视频开发(十一):实时语音通讯丢包补偿技术详解》
《即时通讯音视频开发(十二):多人实时音视频聊天架构探讨》
《即时通讯音视频开发(十三):实时视频编码H.264的特点与优势》
《即时通讯音视频开发(十四):实时音视频数据传输协议介绍》
《即时通讯音视频开发(十五):聊聊P2P与实时音视频的应用情况》
《即时通讯音视频开发(十六):移动端实时音视频开发的几个建议》
《即时通讯音视频开发(十七):视频编码H.264、VP8的前世今生》
《实时语音聊天中的音频处理与编码压缩技术简述》
《网易视频云技术分享:音频处理与压缩技术快速入门》
《学习RFC3550:RTP/RTCP实时传输协议基础知识》
《基于RTMP数据传输协议的实时流媒体技术研究(论文全文)》
《声网架构师谈实时音视频云的实现难点(视频采访)》
《浅谈开发实时视频直播平台的技术要点》
《还在靠“喂喂喂”测试实时语音通话质量?本文教你科学的评测方法!》
《实现延迟低于500毫秒的1080P实时音视频直播的实践分享》
《移动端实时视频直播技术实践:如何做到实时秒开、流畅不卡》
《如何用最简单的方法测试你的实时音视频方案》
《技术揭秘:支持百万级粉丝互动的Facebook实时视频直播》
《简述实时音视频聊天中端到端加密(E2EE)的工作原理》
《移动端实时音视频直播技术详解(一):开篇》
《移动端实时音视频直播技术详解(二):采集》
《移动端实时音视频直播技术详解(三):处理》
《移动端实时音视频直播技术详解(四):编码和封装》
《移动端实时音视频直播技术详解(五):推流和传输》
《移动端实时音视频直播技术详解(六):延迟优化》
《理论联系实际:实现一个简单地基于HTML5的实时视频直播》
《IM实时音视频聊天时的回声消除技术详解》
《浅谈实时音视频直播中直接影响用户体验的几项关键技术指标》
《如何优化传输机制来实现实时音视频的超低延迟?》
《首次披露:快手是如何做到百万观众同场看直播仍能秒开且不卡顿的?》
《Android直播入门实践:动手搭建一套简单的直播系统》
《网易云信实时视频直播在TCP数据传输层的一些优化思路》
《实时音视频聊天技术分享:面向不可靠网络的抗丢包编解码器》
《P2P技术如何将实时视频直播带宽降低75%?》
《专访微信视频技术负责人:微信实时视频聊天技术的演进》
《腾讯音视频实验室:使用AI黑科技实现超低码率的高清实时视频聊天》
《微信团队分享:微信每日亿次实时音视频聊天背后的技术解密》
《近期大热的实时直播答题系统的实现思路与技术难点分享》
《福利贴:最全实时音视频开发要用到的开源工程汇总》
《七牛云技术分享:使用QUIC协议实现实时视频直播0卡顿!》
《实时音视频聊天中超低延迟架构的思考与技术实践》
>> 更多同类文章 ……
(本文同步发布于:http://www.52im.net/thread-1465-1-1.html)