一 面试题概述
面试的时候,面试官会结合你的回答和你的简历来询问你,所以在写简历的时候,简历上所写的所有内容在写的时候必须自己反问一下自己,这个知识点懂不懂。
面试其实是一个沟通技巧的考量,在面试的时候要“灵活”;
在有一些问题上,如果不会,那么直接说不会就可以;但是在一些比较关键的问题上,如果这个算法不会,最好可以稍微的提一下相关的算法,灵活回答。
机器学习/人工智能相关岗位在招聘人员的时候,主要考量的指标有以下几个方面:
①算法的思维能力
②基本的算法原理
③编程能力
④数据结构能力(扩展了解)
二 机器学习面试题(问法)
1.请介绍一下你熟悉的机器学习模型或算法?
2.请介绍**算法或模型原理?(一般都是简历上的)
3.请描述一下**算法和**算法有什么区别?(一般是简历上或者面试过程中问到的算法内容)
4.这些算法模型你是不是都使用过?都用于那些应用场景?
5.在**应用场景中,你使用**算法的时候,遇到了那些问题?最终是如何解决的?
6.在**应用场景中,你们为什么不使用**算法?
7.你觉得在**应用场景中,使用**算法效果如何?
三 机器学习面试题
1. 什么是机器学习过拟合?
所谓过拟合,就是指模型在训练集上的效果很好,在测试集上的预测效果很差.
2. 如何避免过拟合问题?
1. 重采样bootstrap
2. L1,l2正则化
3. 决策树的剪枝操作
4. 交叉验证
3.什么是机器学习的欠拟合?
所谓欠拟合就是模型复杂度低或者数据集太小,对模型数据的拟合程度不高,因此模型在训练集上的效果就不好.
4. 如何避免欠拟合问题?
1.增加样本的数量
2.增加样本特征的个数
3.可以进行特征维度扩展
5.什么是交叉验证?交叉验证的作用是什么?
交叉验证就是将原始数据集(dataset)划分为两个部分.一部分为训练集用来训练模型,另外一部分作为测试集测试模型效果.
作用: 1)交叉验证是用来评估模型在新的数据集上的预测效果,也可以一定程度上减小模型的过拟合
2)还可以从有限的数据中获取尽可能多的有效信息。
交叉验证主要有以下几种方法:
①留出法.简单地将原始数据集划分为训练集,验证集,测试集三个部分.
②k折交叉验证.(一般取5折交叉验证或者10折交叉验证)
③留一法.(只留一个样本作为数据的测试集,其余作为训练集)---只适用于较少的数据集
④ Bootstrap方法.(会引入样本偏差)
6.有监督算法和无监督算法有什么区别?
根据算法模型中有标签的称为有监督算法,反之则称为无监督算法.
7常见的距离度量公式有那些?
1)Minkowski(闵可夫斯基距离)
--- P=1:曼哈顿距离(城市距离)
---P=2:欧式距离
---P无穷:切比雪夫距离
2) 夹角余弦相似度
3) KL距离(相对熵)
4) 杰卡德相似度系数(集合)
5) Pearson相关系数ρ(距离= 1-ρ)
8.文本数据处理的方式有哪些,以及这些处理方式有什么区别
处理方式有:
1) 词袋法(BOW/TF)\词集法(SOW)
---不考虑文本的语法和语序,只考虑单词存在的次数(BOW/TF)或者是否存在(SOW)
2) TF-IDF
---既考虑文本的词频,也考虑文件的逆文档频率(基本思想是:单词的重要性与单词在文档中出现的次数成正比,与单词在语料库中出现的次数成反比)
3) HashTF-IDF(不计算词频,计算单词进行Hash后的Hash值的数量)
4) 哑编码(OneHotEncoder)
5) Word2Vec (通过对文档中的所有单词进行分析->>获得单词之间的关联程度->>进而形成词向量矩阵)
9.什么是最小二乘法?
最小二乘的核心思想---通过最小化误差的平方和,使得拟合对象无限接近目标对象.
10.常见的优化算法有那些,以及这些优化算法有那些优缺点;
1)梯度下降法(Gradient Descent)
---BGD--->每一步迭代都需要遍历所有的样本数据,消耗时间长,但是一定能得到最优解.
---SGD--->迭代速度快,得到局部最优解(凸函数时得到全局最优解)
---MBGD--->小批量梯度下降法
2)牛顿法和拟牛顿法
牛顿法--->牛顿法是二阶收敛,收敛速度快; 牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
拟牛顿法--->改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度.
3)共轭梯度法(Conjugate Gradient)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
4) 启发式的方法
启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等。
多目标优化算法(NSGAII算法、MOEA/D算法以及人工免疫算法)
5)解决约束的方法---拉格朗日乘子法
11. 请描述一下拉格朗日乘子法和KKT条件;
拉格朗日乘子法就是一种将具有约束条件的目标函数转化为没有约束的目标函数的方法.对于不等式约束条件,要求不等式f(x)<=0.
KKT条件:要求α*f(x)=0, f(x)<=0; α>=0并且要求各参数的导数为0
12.如何避免数据不平衡?
1)bootstrap(重采样)--->上采样和下采样
2)数据合成-->利用已有样本生成更多样本
3)加权
4)看成一分类或者异常检测的问题
正负样本都非常之少-->数据合成的方式
负样本足够多,正样本非常之少且比例及其悬殊-->一分类方法
正负样本都足够多且比例不是特别悬殊-->采样或者加权的方法。
13.算法的误差一般是由那几个方面引起的?
1)因模型无法表示基本数据的复杂度而造成的偏差(bias).---欠拟合
2)因模型过度拟合训练集数据而造成的方差(variance).---过拟合
14.在数据处理过程中,对于缺失特征的样本如何进行处理?
根据样本缺失的实际情况,我们一般运用:
1)均值,中值,最大最小值等来填充数据
2)根据经验值补全数据
3)通过相关计算得到缺失值
4)样本数量足够,则可以直接删除有缺失值的样本
15.连续性数据分区转换为离散数据有什么优点?
1)离散特征的增加和减少都很容易,易于模型的快速迭代
2)离散化后的特征对异常数据具有很强的鲁棒性
3)离散化后可以进行特征交叉,相当于引入非线性,提升模型的表达能力
4)降低了模型过拟合的风险
16.哑编码的作用是什么?
哑编码是一种将字符串类型的特征转化为数值型的方法.
17.决策树的常用算法有那些,这些算法有什么区别?
常用的有:ID3,C4.5,CART三种算法
区别:1) 纯度量化指标不同.ID3-->信息增益,C4.5-->信息增益率,CART-->基尼系数
2) 数据处理能力不同. ID3-->离散数据,C4.5,CART--->连续数据离散化,剪枝操作
3)要求的树的类型不同.ID3和C4.5可以是多叉树,CART只能是二叉树.
18.决策树的数据split原理或者流程;
1)将所有样本看做一个节点
2)根据纯度量化指标.计算每一个特征的’纯度’,根据最不’纯’的特征进行数据划分
3)重复上述步骤,知道每一个叶子节点都足够的’纯’或者达到停止条件
19.决策树算法中如何避免过拟合和欠拟合;
过拟合:选择能够反映业务逻辑的训练集去产生决策树;剪枝操作(前置剪枝和后置剪枝); K折交叉验证
欠拟合:增加树的深度,RF
20.回归决策树算法和分类决策树算法有什么区别与联系?
回归决策树解决的是回归的问题.分类决策树解决的是分类的问题.他们在决策树的构建上是一样的(最优划分).回归决策树是计算预测点所在的叶子节点的均值或者加权平均值得到回归结果.分类是通过多数投票或者加权的多数投票得到分类结果.
度量指标不同:回归决策树是MAE,MSE 分类决策树是:信息熵、基尼系数、错误率
21.数据标准化、数据归一化、区间缩放法有什么作用以及各个方法之间有什么区别
数据标准化是将数据集转化为服从标准正态分布的数据.(常用于离散程度较高的数据)
数据归一化是将每个样本的向量转化为单位向量(矩阵的行操作)
区间缩放法是对于分布较大的数据集,通过等比缩放的方法缩放到feature_range=(0,1).
22.特征选择的目标是什么?
选择离散程度高且与目标的相关性强的特征
23.常用的特征选择方式有那些?
①过滤法
过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,从而选择特征;常用方法包括方差选择法、相关系数法、卡方检验、互信息法等
②包装法
包装法,根据目标函数(通常是预测效果评分),每次选择若干特征或者排除若干特征;常用方法主要是递归特征消除法。
③嵌入法
嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权重系数,根据系数从大到小选择特征;常用方法主要是基于惩罚项的特征选择法.
24.降维的作用是什么?
①降维可以缓解维度灾难问题
②降维可以在压缩数据的同时让信息损失最小化
③理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解
25.常见的降维方式有那些?
L1惩罚模型,PCA(主成分分析法)和LDA(线性判别分析法)
PCA-->无监督的降维(无类别信息)-->选择方差大的方向投影,方差越大所含的信息量越大,信息损失越少.可用于特征提取和特征选择。
LDA-->有监督的降维(有类别信息)-->选择投影后的类别内的方差小,类别间的方差较大.
26. PCA降维的原理是什么?
通过线性变换将样本数据从高维投影到低维,并且投影后的数据具有最大的方差,进而完成降维的工作.

27. LDA线性判别分析降维的原理是什么?
LDA一种有监督的降维算法,它是将高维数据投影到低维上,并且要求投影后的数据具有较好的分类.(也就是说同一类的数据要去尽量的投影到同一个簇中去)
28.机器学习中模型参数和超参的区别?超参给定的方式有那些?
模型参数是模型内部的配置变量,可以用数据估计模型参数的值;
模型超参是模型外部的配置,必须手动设置参数的值。
模型超参可以通过网格交叉验证来取值,也可以通过经验选定.
29.常用的机器学习工具有那些?
Python,Numpy,pandas,matplotlib,scikit-learn……
30. SVD矩阵分解在机器学习中有那些作用?
LSA(潜在语义分析),PCA降维……
31.请推导Logistic算法并说明该算法的目标函数是什么?
Sigmoid函数,MLE, 似然函数L(θ)
32.请描述SVM的原理
SVM就是找到一个超平面,使得距离这个超平面最近的点(支持向量)距离超平面最远.
33. SVM中为什么采用间隔最大化?
间隔最大化可以使得样本的置信度上升,分类器更健壮.
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
34.请推导线性可分SVM算法
极大极小值问题的求解,并需要满足KKT条件.
首先求解w,b,带入目标函数中得到:

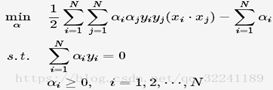
这就要用到SMO方法求解.
35. 请描述软间隔线性可分SVM算法的原理以及应用场景
对于一些不满足函数间隔大于1的样本点,我们在线性可分的基础上加入了松弛因子ξ和惩罚项系数C.
C越大,对误分类的惩罚越大(越不允许分错);当C无限大时就是线性可分问题.
36.请描述SVM如何解决非线性可分的问题37.核函数有什么作用?常见的核函数有那些?
低维映射到高维-----核函数(rbf,linear,poly)----在低维度计算,得到高维分类的效果.
常见的核函数有:高斯核函数、多项式核函数
38. SVM如何处理多分类问题?
ovo或者ovr
39. Logistic回归和SVM算法有什么区别和联系?
相同点:
1)Logistic回归和SVM都是分类算法.
2)如果不考虑使用核函数,LR和SVM都是线性分类模型,也就是说它们的分类决策面是线性的。
3)都是有监督学习的算法
4) LR和SVM都是判别模型。
不同点:
1)损失函数不同
LR基于概率理论,通过极大似然估计方法估计出参数的值,然后计算分类概率,取概率较大的作为分类结果。SVM基于几何间隔最大化,把最大几何间隔面作为最优分类面。
2)SVM只考虑分类面附近的局部的点,即支持向量,LR则考虑所有的点,与分类面距离较远的点对结果也起作用,虽然作用较小。
3)在解决非线性分类问题时,SVM采用核函数,而LR通常不采用核函数。
4)SVM不具有伸缩不变性,LR则具有伸缩不变性。
5)Logistic回归是通过sigmoid函数来进行分类的,类别分为{0,1}.
SVM是通过sign函数来进行分类的,类别分为{+1,-1}.
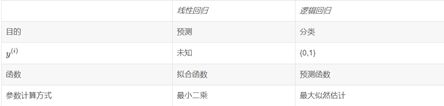
40. Logistic回归和Linear线性回归有什么区别和联系?
41. 如何评价算法模型的效果?
分类算法评价:准确率(Accuracy),精确率(Precision),召回率(Recall),F1值,ROC曲线(AUC值)
回归算法评价: MAE,MSE,可解释方差的回归评分函数(explained_variance_score)
42.分类算法的评估指标有那些?
准确率(Accuracy),精确率(Precision),召回率(Recall),F1值,ROC曲线(AUC值)
43.混淆矩阵的作用?(模型效果评价)

44. 召回率、精确率、准确率、F1指标的作用以及区别?
召回率(Recall)-->预测正确的真正例/全部真正例
精确率(Precision)-->预测正确的真正例/被预测为真正例的所有样本数
准确率(Accuracy)-->预测正确的正负样本数/样本总数
F1值--> 2/(1/Precision +1/Recall)-->精确率和召回率的调和平均值
45. ROC和AUC的作用?
TPR(TruePositive Rate): TP/(TP+FN),实际就是Recall
FPR:FP/(FP+TN),错误接收率,误报率,即负样本被识别为正样本的概率.
ROC曲线就是以FPR为横轴,TPR为纵轴,绘制出的一条曲线.AUC为ROC曲线下方的面积.
ROC曲线是评价分类模型效果的常用方法.AUC的值越大,表示模型效果越好.
46.回归算法的评估指标有那些?
MAE,MSE, R2
47. MSE、MAE、R2指标的作用和区别?
MSE--->均方差.
MAE--->平均绝对误差.
R2--->分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响.
48. 损失函数和目标函数的区别?
损失函数(代价函数)-->损失函数越小,就代表模型拟合的越好。
目标函数-->把要最大化或者最小化的函数(模型迭代时的迭代方向,往目标函数最小化的方向迭代)称为目标函数.有正则项的必定是目标函数.
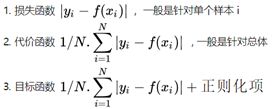
49. 在机器学习中,模型的选择指的是?如何进行模型选择?
模型选择就是算法模型及模型参数的选择.(就是说选择什么算法)
如何进行模型选择--->交叉验证,选择效果好的模型.
50.在机器学习中,模型效果不好的时候,如何调试学习算法模型?
1)获取更多的数据量
2)特征减少(降维)或者特征增加(是否删除了很重要的特征)==》特征工程
3)模型参数的调节(超参)
4) 模型融合(提升算法)
51.请描述随机森林(Random Forest)的原理
RF是Bagging算法的一种变种算法.
1)通过对数据集进行Bootstrap(重采样),获取m个样本.
2)对这m个样本并进行特征随机选择,再训练出m棵决策树模型.
3)根据这m棵决策树,运用投票表决或者加权投票表决的方式进行分类,运用平均值或者加权平均进行回归.
52.请描述RF和GBDT之间的相同点和不同点
RF和GBDT相同点:
1)都是使用决策树作为基模型.
2)都是集成算法的一种
3)都是由多棵树组成, 最终的结果都是由多棵树一起决定
RF和GBDT不同点:
1、组成随机森林的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
2、组成随机森林的树可以并行生成;而GBDT只能是串行生成(强融合)
3、对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加或者加权累加起来
4、随机森林对异常值不敏感,GBDT对异常值非常敏感
5、随机森林对训练集一视同仁,GBDT是基于权值的弱分类器的集成
6、随机森林是通过减少模型方差提高性能,GBDT是通过减少模型偏差提高性能
53. XGBoost的作用是什么
0.0
54.在XGBoost中,构建树的时候使用那些优化的方式
0.0
55.集成学习的原理/作用是什么?
原理:’博采众长’
作用:根据一定的结合策略,将多个弱学习器组成一个强学习器.
56. RF、GBDT在特征选择中的作用是什么?
在进行特征选择时,我们可以使用RF、GBDT首先对模型进行训练,得到feature_importance参数值,再给定的阈值就可以进行特征选择(选择那些重要性高的特征).
做特征的扩展。