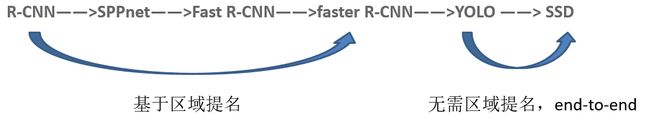
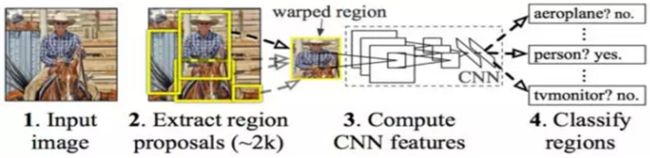
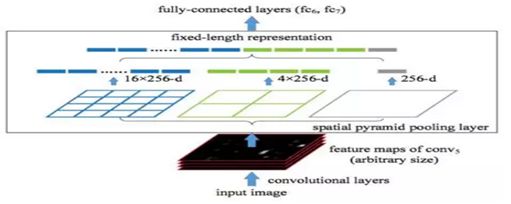
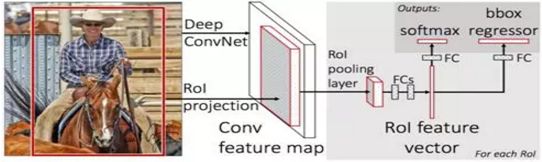
- android系统selinux中添加新属性property
辉色投像
1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property
- Cell Insight | 单细胞测序技术又一新发现,可用于HIV-1和Mtb共感染个体诊断
尐尐呅
结核病是艾滋病合并其他疾病中导致患者死亡的主要原因。其中结核病由结核分枝杆菌(Mycobacteriumtuberculosis,Mtb)感染引起,获得性免疫缺陷综合症(艾滋病)由人免疫缺陷病毒(Humanimmunodeficiencyvirustype1,HIV-1)感染引起。国家感染性疾病临床医学研究中心/深圳市第三人民医院张国良团队携手深圳华大生命科学研究院吴靓团队,共同研究得出单细胞测序
- 绘本讲师训练营【24期】8/21阅读原创《独生小孩》
1784e22615e0
24016-孟娟《独生小孩》图片发自App今天我想分享一个蛮特别的绘本,讲的是一个特殊的群体,我也是属于这个群体,80后的独生小孩。这是一本中国绘本,作者郭婧,也是一个80厚。全书一百多页,均为铅笔绘制,虽然为黑白色调,但并不显得沉闷。全书没有文字,犹如“默片”,但并不影响读者对该作品的理解,反而显得神秘,梦幻,給读者留下想象的空间。作者在前蝴蝶页这样写到:“我更希望父母和孩子一起分享这本书,使他
- 向内而求
陈陈_19b4
10月27日,阴。阅读书目:《次第花开》。作者:希阿荣博堪布,是当今藏传佛家宁玛派最伟大的上师法王,如意宝晋美彭措仁波切颇具影响力的弟子之一。多年以来,赴海内外各地弘扬佛法,以正式授课、现场开示、发表文章等多种方法指导佛学弟子修行佛法。代表作《寂静之道》、《生命这出戏》、《透过佛法看世界》自出版以来一直是佛教类书籍中的畅销书。图片发自App金句:1.佛陀说,一切痛苦的根源在于我们长期以来对自身及外
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- 拥有断舍离的心态,过精简生活--《断舍离》读书笔记
爱吃丸子的小樱桃
不知不觉间房间里的东西越来越多,虽然摆放整齐,但也时常会觉得空间逼仄,令人心生烦闷。抱着断舍离的态度,我开始阅读《断舍离》这本书,希望从书中能找到一些有效的方法,帮助我实现空间、物品上的断舍离。《断舍离》是日本作家山下英子通过自己的经历、思考和实践总结而成的,整体内涵也从刚开始的私人生活哲学的“断舍离”升华成了“人生实践哲学”,接着又成为每个人都能实行的“改变人生的断舍离”,从“哲学”逐渐升华成“
- 少了生活气息
我爱大草莓
最近啊,总觉得自己日更的内容缺了点什么。我仔细地想,大概是少了些生活气息。这两三个月减少了许多与别人相处的时间,独自生活,偶尔只是出去买菜,总觉得生活好像变空了许多。买菜的时候会跟档口的阿姨聊一两句话,让自己感觉在真实地生活着。幸好我也不是一宅到底,偶尔周末也会约着跟好朋友见面,面对面交流跟隔着屏幕交流,效果还是不一样的,至少有更为真实的生活感。写作不仅需要有阅读量,有文笔,生活阅历也是非常重要的
- 【目标检测数据集】卡车数据集1073张VOC+YOLO格式
熬夜写代码的平头哥∰
目标检测YOLO人工智能
数据集格式:PascalVOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1073标注数量(xml文件个数):1073标注数量(txt文件个数):1073标注类别数:1标注类别名称:["truck"]每个类别标注的框数:truck框数=1120总框数:1120使用标注工具:labelImg标注
- 走向以教育叙事为载体的教育叙事研究
666小飞鱼
今天我读了吴松超老师的《给教师的68条建写作建议》中的第23条《如何通过教育叙事走向研究》,吴老师在文中与我们分享了一个德育案例,这是一个反面的案例,意在告知我们在处理问题时,不能就考虑的点太窄,思考要全面。走向教育叙事研究,教师要有敏锐的“感知力”,这个感知力来自于背后专业知识的支撑,思维能力以及广阔的视野和见识等。所以对于同一件事处理方法不同,这个就是教师背后“敏锐力”的不同造成的,也就是说是
- 梁文道《尽头:怎样是好的阅读和书写》 片段
白夜书摘
1、写小说的人,有时会强烈地感到一种现实的召唤,想去面对和回应现实。这时他们会觉得自己正站在时代中心,就像黑格尔说的,要把时代精神掌握在自己的小说(不是哲学)里面。但是这也很危险,当一个作家像一个时代那样书写,可能就会出现问题了。2、文字是远比语言大块而且湿冷的木头,又距离我们内心的火花稍远,不容易瞬间点燃起来,这处隙缝,给了我们回身的余地,可以再多看一下想一下设身处地一下;人类过往这最后五千年,
- 番茄西红柿叶子病害分类数据集12882张11类别
futureflsl
数据集分类数据挖掘人工智能
数据集类型:图像分类用,不可用于目标检测无标注文件数据集格式:仅仅包含jpg图片,每个类别文件夹下面存放着对应图片图片数量(jpg文件个数):12882分类类别数:11类别名称:["Bacterial_Spot_Bacteria","Early_Blight_Fungus","Healthy","Late_Blight_Water_Mold","Leaf_Mold_Fungus","Powdery
- 阶段总结反思
轻争
马上就要进入10月份了,今天做一下前段时间的总结和反思。前段时间,日更、英语、健身、护肤坚持的比较好。阅读、书法坚持的不好。1.中间被迫停更半个多月,其余时间一直在坚持日更挑战。偶尔也有不想写的时候,就做一下摘抄。因为阅读(输入)没跟上来,所以写作(输出)质量有待进一步加强。2.英语做到了一周至少学习5天,每次不少于30分钟,但是小班课没有跟上更新速度,下一步要争取利用零碎时间补听小班课。3.减肥
- 【穿过丛林看见你】2015年在《诗歌报》读诗日记(一)
快快_ce70
写完《三月的领土》和《手握一把锄头,在翻动诗歌的春天》之后,安稳的睡了个好觉,这是从2013年的五月之后,第一次睡的如此安稳和香甜。其实这对于我来说,也没有什么特别的意义和变故,就像我现在的生活在人人忙着踏青、写生、拍照的春天。在我脚下,没有领土的完整,也没有加剧的破碎。我曾经和现在都是个辛勤的“蜂农”,在这样一个角色里,尽管有人盗走了我所有的蜜,但不妨碍我对甜蜜的不懈追求和喜爱。翻开最近的阅读笔
- 2019-3-23晨间日记
红红火火小耳朵
今天是什么日子起床:7点40就寝:23点半天气:有太阳,不过一会儿出来一会儿进去特别清爽的凉意,还蛮舒服的心情:小激动要给女朋友过生日啦纪念日:田田女士过生日任务清单昨日完成的任务,最重要的三件事:1.英语一对一2.运动计划3.认真护肤习惯养成:调整状态周目标·完成进度英语七天打卡(5/7)轻课阅读(87/180)音标课(25/30)读书(福尔摩斯一章)学习·信息·阅读#英语课#Cookingte
- 【华为OD技术面试真题精选 - 非技术题】 -HR面,综合面_华为od hr面
一个射手座的程序媛
程序员华为od面试职场和发展
最后的话最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!资料预览给大家整理的视频资料:给大家整理的电子书资料:如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料的朋友,可以点击这里获
- 2020-12-24
我和我的天使们
阅读《老子的心事》391—403“将欲取之,必固与之”:想要得到什么,首先就要送出什么。我常常对孩子们说,你希望别人怎样对你你就怎样对待别人。想要得到别人的尊重,首先要尊重别人。我希望她们可以不迟到,因为不迟到是对别人的尊重,我就自己就先做到不迟到。哪怕是约朋友逛街,我尽量准时赴约。我严格要求孩子们,也同样严格要求自己,我跟孩子们一起把好的品格变成习惯。“是谓微明”:这就是微妙的智慧。看起来很少很
- 《经年驯养》黎栀傅谨臣(高分女频)全章节在线阅读
云轩书阁
《经年驯养》黎栀傅谨臣(高分女频)全章节在线阅读主角:黎栀傅谨臣简介:傅谨臣养大黎栀,对她有求必应,黎栀以为那是爱。结婚两年才发现,她不过他豢养最好的一只宠物,可她拿他当全世界。关注微信公众号【看精灵】去回个书號【9328】,即可阅读【经年驯养】小说全文!第10章温柔的眼神,宠溺的动作,留恋的话近乎情人低语。是黎栀做梦都想要的一切……她口干舌燥,紧张难言。一颗心似被浸泡在温水里,酥麻舒适,无可抗拒
- 厉国刚:新闻学与传播学到底有何区别
微观大道
厉国刚:新闻学与传播学到底有何区别头几天,有人在知乎上问我:新闻学与传播学到底有何区别。他是一位想要跨专业考研的学生,对新闻传播学学科可谓了解甚少,甚至一头雾水,想要让我帮他解释解释。在研究生学硕层面,新闻传播学是一级学科,分成新闻学、传播学这两个二级学科。有些高校,还自设了广告学、出版发行学等其他二级学科,但从官方角度,新闻传播学一级学科下,正统的就是那两个二级学科。招生时,一般会按一级学科招,
- ES聚合分析原理与代码实例讲解
光剑书架上的书
大厂Offer收割机面试题简历程序员读书硅基计算碳基计算认知计算生物计算深度学习神经网络大数据AIGCAGILLMJavaPython架构设计Agent程序员实现财富自由
ES聚合分析原理与代码实例讲解1.背景介绍1.1问题的由来在大规模数据分析场景中,特别是在使用Elasticsearch(ES)进行数据存储和检索时,聚合分析成为了一个至关重要的功能。聚合分析允许用户对数据集进行细分和分组,以便深入探索数据的结构和模式。这在诸如实时监控、日志分析、业务洞察等领域具有广泛的应用。1.2研究现状目前,ES聚合分析已经成为现代大数据平台的核心组件之一。它支持多种类型的聚
- 2022-08-28
蔚蓝一片晴
初三暑假培训收获点滴从8月25至8月27日三天两晚的培训结束了,回到家中,该静下心来整理一下触动心灵的收获,成为成长的积淀。1.在优秀团队中快速成长与提升,做一名反思成长型教师一名专业型教师的教学指导包括了教学原理知识、案例知识、策略知识。面对教学中的遇到的有趣的情形、问题会去研究其理,寻找更好的教法学法对策。从新手到成熟型教师,再走向专业型教师,需要的是觉醒与反思,多进行案例研究,从案例中观察、
- 希望和悲伤都是照亮我们人生的一缕光
山月映雪
我开始并不想读《云边有个小卖部》,但看到好几个学生就都在读这本书,为了了解学生的阅读实际,我就拿起这本书翻看起来。读了十几页,发现小说的语言中不时有一些粗俗的字眼,感觉自己读不下去了。小说一开始把云边镇风景写的特别的美好,我错判为脱离现实的鸳鸯蝴蝶派小说,对于人为制造的童话世界的人与物,我真的不太感兴趣,所以就没有再读了。有天在教室闲转,顺手又拿起了这本书看了起来,这次我才真的看进去了。这部小说除
- 为什么瘦子很难增胖?
我的狗毛毛
我是个标准的瘦子,168,100斤。用一句通俗的话来讲,我连马甲线都瘦出来了(体脂含量比较低)。但是我反而很羡慕那些比较丰满的女人,我的理想是再增重十五斤,练成前凸后翘的魔鬼身材。为此我开始纠正自己不规律的作息,吃高热量的食物,减少运动量,能坐着绝不站着,能躺着绝不坐着。但是结果却没有丝毫变化。我一直很苦恼,直到最近在网上看到一个视频,英国的某个研究机构做了一个实验,想要知道瘦子能否在高热量的食物
- 2020-8-19晨间日记:看过的电影
盐大虾
今天是周三起床:6点半就寝:11点天气:晴心情:正常纪念日:周三任务清单今日完成的任务,最重要的三件事:1.整理写过的文档2.电影《电灯泡》3.这就是街舞第三季第五期改进:早睡早起习惯养成:早睡早起,看书周目标·完成进度两篇文章学习·信息·阅读电影艺术发展史相关教材健康·饮食·锻炼吃了挺多零食,还喝了果粒橙,还是得少吃,多锻炼,不然会慢慢死掉的。人际·家人·朋友淡定交流,不放在心上。工作·思考专心
- 现代汉语粗糙版 文学史与经典
学习搬运工
第十六章文学史与经典文学史的兴起在西方,虽然从亚里士多德开始,在人类的著述中已经可以找到文学史概念与写作方式的萌芽,但是,人们一般认为17世纪后期到18世纪是现代文学史写作真正开始的时期。长达百年波及整个欧洲的“古今之争”孕育出文学研究的历史意识,现代意义上的文学史观念在这场影响深远的论争中初见端倪。从18世纪晚期到19世纪初,由于席勒、弗·施莱格尔和赫尔德等人的介入,文学史研究逐渐变得复杂和成熟
- 简单说说关于shell中zsh和bash的选择
秋刀prince
MacOS小猿们的开发日常bash
希望文章能给到你启发和灵感~如果觉得文章对你有帮助的话,点赞+关注+收藏支持一下博主吧~阅读指南开篇说明一、基础环境说明1.1硬件环境1.2软件环境二、什么是shell、bash、zsh?2.1bash2.2zsh三、选择Bash还是Zsh?四、一些常见问题开篇说明本篇主要简单说明一下,shell中bash和zsh的区别和选择;我们经常会把这两个搞混,不知道什么时候用哪一个,以及怎么使用;一、基础
- 《前夫如龙》王昊江琼(独家小说)精彩TXT阅读
海边书楼
《前夫如龙》王昊江琼(独家小说)精彩TXT阅读主角:王昊江琼简介:离婚那天,她视他如泥土。谁曾想,消息一出,天下震动!可关注微信公众号【风车文楼】去回个书号【203】,即可免费阅读【前夫如龙】全文!江芸并未听出华少龙声音里的冷漠,依旧一脸笑容道:“是啊,那个废物哪儿配得上我姐?这些年,我姐对他仁至义尽了。以后,华少爷可以多跟我姐接触接触,只有华少爷这样的人,才配得上我姐啊!”江琼低着头,微微有些娇
- 2018-12-22 《金刚经修心课:不焦虑的活法》摘录
Cintia1004
不为外界干扰的神奇力量如果你即将开始阅读金刚经,请试着把你的心空下来,把你各种习惯性的想法放在一边,以一种敞开的心态去阅读它。在敞开的阅读里,你会慢慢领悟到,金刚经没有任何结论,只是一种启迪,一种指引,指引你彻底地自我解放,从一切的成见里解放出来。你会惊奇地发现,金刚经……你都能够获得一种不为外界干扰的平静的力量。当这种力量充满你的日常生活,你会不害怕失败,……没有得到的时候,想要得到;已经得到的
- android 更改窗口的层次,浮窗开发之窗口层级
Ms.Bu
android更改窗口的层次
最近在项目中遇到了这样的需求:需要在特定的其他应用之上悬浮自己的UI交互(拖动、输入等复杂的UI交互),和九游的浮窗类似,不过我们的比九游的体验更好,我们越过了很多授权的限制。浮窗效果很多人都知道如何去实现一个简单的浮窗,但是却很少有人去深入的研究背后的流程机制,由于项目中浮窗交互比较复杂,遇到了些坑查看了很多资料,故总结浮窗涉及到的知识点:窗口层级关系(浮窗是如何“浮”的)?浮窗有哪些限制,如何
- 2023-06-19【感恩日记】第246篇
o泡沫o
思想日记:坚持下去,相信自己一定可以的【感恩日记】第246篇1.我真是太幸福啦!感恩孩子早起阅读,放学到学生之家完成作业,平安度过美好的一天。感恩!感恩!感恩!❤️2.我真是太幸福啦!感恩自己早起给孩子煮早餐,完成计划的工作,晚上学习。感恩!感恩!感恩!❤️3.我真是太幸福啦!感恩为我设计效果图的老师。感恩!感恩!感恩!❤️4.我真是太幸福啦!感恩父母养育了我,有妈的孩子真幸福。感恩!感恩!感恩!
- 5月23日能量阅读打卡
free森
当我走在人生路上的时候,我只能往前因为身后是飞逝的光阴。如果我因为过去与未来而瞻前顾后我的道路与生命进程就会停下来我的生命就会成为恐惧的俘虏所以我不应该因为过去与未来而驻足即便我的道路上充满了坎坷,即便我的道路上充满了考验,可是坎坷与考验都不能成为我停下的理由!我要跟坎坷说对不起,我爱你!我要跟考验说请原谅,谢谢你!我要在人生路上勇往直前,面对坎坷与重重生命的考验,我要毅然高歌猛进去追求精彩的人生
- log4j对象改变日志级别
3213213333332132
javalog4jlevellog4j对象名称日志级别
log4j对象改变日志级别可批量的改变所有级别,或是根据条件改变日志级别。
log4j配置文件:
log4j.rootLogger=ERROR,FILE,CONSOLE,EXECPTION
#log4j.appender.FILE=org.apache.log4j.RollingFileAppender
log4j.appender.FILE=org.apache.l
- elk+redis 搭建nginx日志分析平台
ronin47
elasticsearchkibanalogstash
elk+redis 搭建nginx日志分析平台
logstash,elasticsearch,kibana 怎么进行nginx的日志分析呢?首先,架构方面,nginx是有日志文件的,它的每个请求的状态等都有日志文件进行记录。其次,需要有个队 列,redis的l
- Yii2设置时区
dcj3sjt126com
PHPtimezoneyii2
时区这东西,在开发的时候,你说重要吧,也还好,毕竟没它也能正常运行,你说不重要吧,那就纠结了。特别是linux系统,都TMD差上几小时,你能不痛苦吗?win还好一点。有一些常规方法,是大家目前都在采用的1、php.ini中的设置,这个就不谈了,2、程序中公用文件里设置,date_default_timezone_set一下时区3、或者。。。自己写时间处理函数,在遇到时间的时候,用这个函数处理(比较
- js实现前台动态添加文本框,后台获取文本框内容
171815164
文本框
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://w
- 持续集成工具
g21121
持续集成
持续集成是什么?我们为什么需要持续集成?持续集成带来的好处是什么?什么样的项目需要持续集成?... 持续集成(Continuous integration ,简称CI),所谓集成可以理解为将互相依赖的工程或模块合并成一个能单独运行
- 数据结构哈希表(hash)总结
永夜-极光
数据结构
1.什么是hash
来源于百度百科:
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
- 乱七八糟
程序员是怎么炼成的
eclipse中的jvm字节码查看插件地址:
http://andrei.gmxhome.de/eclipse/
安装该地址的outline 插件 后重启,打开window下的view下的bytecode视图
http://andrei.gmxhome.de/eclipse/
jvm博客:
http://yunshen0909.iteye.com/blog/2
- 职场人伤害了“上司” 怎样弥补
aijuans
职场
由于工作中的失误,或者平时不注意自己的言行“伤害”、“得罪”了自己的上司,怎么办呢?
在职业生涯中这种问题尽量不要发生。下面提供了一些解决问题的建议:
一、利用一些轻松的场合表示对他的尊重
即使是开明的上司也很注重自己的权威,都希望得到下属的尊重,所以当你与上司冲突后,最好让不愉快成为过去,你不妨在一些轻松的场合,比如会餐、联谊活动等,向上司问个好,敬下酒,表示你对对方的尊重,
- 深入浅出url编码
antonyup_2006
应用服务器浏览器servletweblogicIE
出处:http://blog.csdn.net/yzhz 杨争
http://blog.csdn.net/yzhz/archive/2007/07/03/1676796.aspx
一、问题:
编码问题是JAVA初学者在web开发过程中经常会遇到问题,网上也有大量相关的
- 建表后创建表的约束关系和增加表的字段
百合不是茶
标的约束关系增加表的字段
下面所有的操作都是在表建立后操作的,主要目的就是熟悉sql的约束,约束语句的万能公式
1,增加字段(student表中增加 姓名字段)
alter table 增加字段的表名 add 增加的字段名 增加字段的数据类型
alter table student add name varchar2(10);
&nb
- Uploadify 3.2 参数属性、事件、方法函数详解
bijian1013
JavaScriptuploadify
一.属性
属性名称
默认值
说明
auto
true
设置为true当选择文件后就直接上传了,为false需要点击上传按钮才上传。
buttonClass
”
按钮样式
buttonCursor
‘hand’
鼠标指针悬停在按钮上的样子
buttonImage
null
浏览按钮的图片的路
- 精通Oracle10编程SQL(16)使用LOB对象
bijian1013
oracle数据库plsql
/*
*使用LOB对象
*/
--LOB(Large Object)是专门用于处理大对象的一种数据类型,其所存放的数据长度可以达到4G字节
--CLOB/NCLOB用于存储大批量字符数据,BLOB用于存储大批量二进制数据,而BFILE则存储着指向OS文件的指针
/*
*综合实例
*/
--建立表空间
--#指定区尺寸为128k,如不指定,区尺寸默认为64k
CR
- 【Resin一】Resin服务器部署web应用
bit1129
resin
工作中,在Resin服务器上部署web应用,通常有如下三种方式:
配置多个web-app
配置多个http id
为每个应用配置一个propeties、xml以及sh脚本文件
配置多个web-app
在resin.xml中,可以为一个host配置多个web-app
<cluster id="app&q
- red5简介及基础知识
白糖_
基础
简介
Red5的主要功能和Macromedia公司的FMS类似,提供基于Flash的流媒体服务的一款基于Java的开源流媒体服务器。它由Java语言编写,使用RTMP作为流媒体传输协议,这与FMS完全兼容。它具有流化FLV、MP3文件,实时录制客户端流为FLV文件,共享对象,实时视频播放、Remoting等功能。用Red5替换FMS后,客户端不用更改可正
- angular.fromJson
boyitech
AngularJSAngularJS 官方APIAngularJS API
angular.fromJson 描述: 把Json字符串转为对象 使用方法: angular.fromJson(json); 参数详解: Param Type Details json
string
JSON 字符串 返回值: 对象, 数组, 字符串 或者是一个数字 示例:
<!DOCTYPE HTML>
<h
- java-颠倒一个句子中的词的顺序。比如: I am a student颠倒后变成:student a am I
bylijinnan
java
public class ReverseWords {
/**
* 题目:颠倒一个句子中的词的顺序。比如: I am a student颠倒后变成:student a am I.词以空格分隔。
* 要求:
* 1.实现速度最快,移动最少
* 2.不能使用String的方法如split,indexOf等等。
* 解答:两次翻转。
*/
publ
- web实时通讯
Chen.H
Web浏览器socket脚本
关于web实时通讯,做一些监控软件。
由web服务器组件从消息服务器订阅实时数据,并建立消息服务器到所述web服务器之间的连接,web浏览器利用从所述web服务器下载到web页面的客户端代理与web服务器组件之间的socket连接,建立web浏览器与web服务器之间的持久连接;利用所述客户端代理与web浏览器页面之间的信息交互实现页面本地更新,建立一条从消息服务器到web浏览器页面之间的消息通路
- [基因与生物]远古生物的基因可以嫁接到现代生物基因组中吗?
comsci
生物
大家仅仅把我说的事情当作一个IT行业的笑话来听吧..没有其它更多的意思
如果我们把大自然看成是一位伟大的程序员,专门为地球上的生态系统编制基因代码,并创造出各种不同的生物来,那么6500万年前的程序员开发的代码,是否兼容现代派的程序员的代码和架构呢?
- oracle 外部表
daizj
oracle外部表external tables
oracle外部表是只允许只读访问,不能进行DML操作,不能创建索引,可以对外部表进行的查询,连接,排序,创建视图和创建同义词操作。
you can select, join, or sort external table data. You can also create views and synonyms for external tables. Ho
- aop相关的概念及配置
daysinsun
AOP
切面(Aspect):
通常在目标方法执行前后需要执行的方法(如事务、日志、权限),这些方法我们封装到一个类里面,这个类就叫切面。
连接点(joinpoint)
spring里面的连接点指需要切入的方法,通常这个joinpoint可以作为一个参数传入到切面的方法里面(非常有用的一个东西)。
通知(Advice)
通知就是切面里面方法的具体实现,分为前置、后置、最终、异常环
- 初一上学期难记忆单词背诵第二课
dcj3sjt126com
englishword
middle 中间的,中级的
well 喔,那么;好吧
phone 电话,电话机
policeman 警察
ask 问
take 拿到;带到
address 地址
glad 高兴的,乐意的
why 为什么
China 中国
family 家庭
grandmother (外)祖母
grandfather (外)祖父
wife 妻子
husband 丈夫
da
- Linux日志分析常用命令
dcj3sjt126com
linuxlog
1.查看文件内容
cat
-n 显示行号 2.分页显示
more
Enter 显示下一行
空格 显示下一页
F 显示下一屏
B 显示上一屏
less
/get 查询"get"字符串并高亮显示 3.显示文件尾
tail
-f 不退出持续显示
-n 显示文件最后n行 4.显示头文件
head
-n 显示文件开始n行 5.内容排序
sort
-n 按照
- JSONP 原理分析
fantasy2005
JavaScriptjsonpjsonp 跨域
转自 http://www.nowamagic.net/librarys/veda/detail/224
JavaScript是一种在Web开发中经常使用的前端动态脚本技术。在JavaScript中,有一个很重要的安全性限制,被称为“Same-Origin Policy”(同源策略)。这一策略对于JavaScript代码能够访问的页面内容做了很重要的限制,即JavaScript只能访问与包含它的
- 使用connect by进行级联查询
234390216
oracle查询父子Connect by级联
使用connect by进行级联查询
connect by可以用于级联查询,常用于对具有树状结构的记录查询某一节点的所有子孙节点或所有祖辈节点。
来看一个示例,现假设我们拥有一个菜单表t_menu,其中只有三个字段:
- 一个不错的能将HTML表格导出为excel,pdf等的jquery插件
jackyrong
jquery插件
发现一个老外写的不错的jquery插件,可以实现将HTML
表格导出为excel,pdf等格式,
地址在:
https://github.com/kayalshri/
下面看个例子,实现导出表格到excel,pdf
<html>
<head>
<title>Export html table to excel an
- UI设计中我们为什么需要设计动效
lampcy
UIUI设计
关于Unity3D中的Shader的知识
首先先解释下Unity3D的Shader,Unity里面的Shaders是使用一种叫ShaderLab的语言编写的,它同微软的FX文件或者NVIDIA的CgFX有些类似。传统意义上的vertex shader和pixel shader还是使用标准的Cg/HLSL 编程语言编写的。因此Unity文档里面的Shader,都是指用ShaderLab编写的代码,
- 如何禁止页面缓存
nannan408
htmljspcache
禁止页面使用缓存~
------------------------------------------------
jsp:页面no cache:
response.setHeader("Pragma","No-cache");
response.setHeader("Cache-Control","no-cach
- 以代码的方式管理quartz定时任务的暂停、重启、删除、添加等
Everyday都不同
定时任务管理spring-quartz
【前言】在项目的管理功能中,对定时任务的管理有时会很常见。因为我们不能指望只在配置文件中配置好定时任务就行了,因为如果要控制定时任务的 “暂停” 呢?暂停之后又要在某个时间点 “重启” 该定时任务呢?或者说直接 “删除” 该定时任务呢?要改变某定时任务的触发时间呢? “添加” 一个定时任务对于系统的使用者而言,是不太现实的,因为一个定时任务的处理逻辑他是不
- EXT实例
tntxia
ext
(1) 增加一个按钮
JSP:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%
String path = request.getContextPath();
Stri
- 数学学习在计算机研究领域的作用和重要性
xjnine
Math
最近一直有师弟师妹和朋友问我数学和研究的关系,研一要去学什么数学课。毕竟在清华,衡量一个研究生最重要的指标之一就是paper,而没有数学,是肯定上不了世界顶级的期刊和会议的,这在计算机学界尤其重要!你会发现,不论哪个领域有价值的东西,都一定离不开数学!在这样一个信息时代,当google已经让世界没有秘密的时候,一种卓越的数学思维,绝对可以成为你的核心竞争力. 无奈本人实在见地