1、对象管理机制-复杂
为更好的管理模型对象,EF提供了一套内部管理机制和跟踪对象的状态,保存对象一致性,使用方便,但是性能有所降低。
2、执行机制-高度封装
在EF中,所有的查询表达式都会经过语法分析、解析SQL语句、然后调用底层的ADO.NET对象去执行,中间的这些环节导致性能有所降低。
3、SQL语句-低效
EF采用映射机制将对象操作转换成SQL语句,SQL语句一般的基于标准模块生成的,不会进行特殊优化,和直接编写SQL语句操作数据库相比,效率会打折扣,复杂操作更为明显。
状态管理机制优化

AsNoTracing()方法
1、添加AsNoTracing()方法后,对象将不被状态管理,查询性能提高
2、返回的实体将不再DbContext中缓存
3、适合场景:纯粹查询,不进行数据增删改操作
禁用自动跟踪变化

分析
1、关闭前,当执行Add()操作时将会耗费大量的性能,会导致DbContext遍历所有缓存的Entry,比较原始值和当前值,而这个操作会非常耗费性能
2、关闭后,使用Add()方法告知DbContext中对象的变化即可,如果是删除使用Remove()方法,如果是修改则还需要通过State属性显示告知变化
3、适合场景:大批量操作数据(添加、删除、修改)
优化措施列表
- 1.使用最新版的EF
- 2. 禁用延迟加载
- 3.使用贪婪加载(又叫预加载就是数据库的多表查询)
- 4.了解 IQueryable,IEnumerable的区别
- 5.优化操作AsNoTracking()与Attach
- 6.EF使用SqlQuery
- 7.关于AsNonUnicode
- 8.建议使用ViewModel代替实体Model
- 9.建议Model实体中枚举使用byte类型
- 10.Model实体使用DateTime2替换DateTime控制内容值精度
- 11.合理使用EF扩展库
- 1.EF实现指定字段的更新
- 2.批量查询功能
- 3.查询缓存功能
- 12.EF使用SQL分库操作
下面开始一一介绍
1.使用最新版的EF
使用最新版的EF正式版本代替老的版本(除旧迎新哈哈),毕竟EF是微软所重视的主流数据操作库,每次升级版本优化效果都挺明显的。
2. 禁用延迟加载
若使用延迟加载遍历单个Model下的某一集合属性,如下面的例子:
var user = db.Person.Single(a => a.Id == 1);
foreach (var role in user.Roles) { Console.WriteLine(role.Name); } 每次我们需要访问属性Role.Name的时候都会访问数据,这样累加起来的开销是很大的。
EF默认使用延迟加载获取导航属性关联的数据。
作为默认配置的延迟加载,需要满足以下几个条件:
-
context.Configuration.ProxyCreationEnabled = true;
-
context.Configuration.LazyLoadingEnabled = true;
-
导航属性被标记为virtual
这三个条见缺一不可。因此可以选择性禁用全局延迟加载或者是某一属性的延迟加载.
3.使用贪婪加载(又叫预加载就是数据库的多表查询)
这点其实也跟上面的一样响应了一个原则:尽量的减少数据库的访问次数,
var user = db.Person.Include(a=>a.Roles);
一次查询将UserProfile与其Role表数据查询出来
4.了解 IQueryable,IEnumerable的区别
IQueryable返回的是查询表达式,也就是说生成了SQL查询语句但是却还没有与数据库进行交互。
IEnumerable则是已经执行查询数据库的操作且数据保存在了内存中
所以在进行条件拼接的时候一定要在IQueryable类型后面追加Where条件语句,而不是等到ToList之后再开始写条件
错误的写法:
db.Person.ToList().Where(a => a.IsDeleted == false); 正确的写法:
db.Person.Where(a => a.IsDeleted == false).ToList(); 这些写法的意思就是把数据条件拼凑好,再访问数据库。否则从数据库获取全部数据后再过滤,假如数据很庞大几十万,那后果可想而知!
5.优化操作AsNoTracking()与Attach
对于只读操作,强烈建议使用AsNoTracking进行数据获取,这样省去了访问EF Context的时间,会大大降低数据获取所需的时间。
同时由于没有受到上下文的跟踪缓存,因此取得的数据也是及时最新的,更利于某些对数据及时性要求高的数据查询。
db.Person.Where(a => a.IsDeleted == false).AsNoTracking().ToList(); 下面是本人编写关于更改AsNoTracking数据Update的两种方式测试与总结:
EntityDB db = new EntityDB();
var users = db.User.AsNoTracking().ToList();
foreach (var user in users) { db.Set().Attach(user); } foreach (var user in users) { user.IsDeleted = true; //db.Entry(user).State=EntityState.Modified; } db.SaveChanges(); 以上代码我将未跟踪的数据做Attach后赋值SaveChanges生成的SQL语句如下:
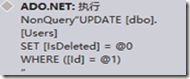
而采用直接赋值后Entry修改State状态为Modified
EntityDB db = new EntityDB();
var users = db.User.AsNoTracking().ToList();
/* foreach (var user in users)
{
db.Set().Attach(user);
}*/
foreach (var user in users) { user.IsDeleted = false; db.Entry(user).State=EntityState.Modified; } db.SaveChanges(); 生成的SQL语句如下:

对比我们得出结论第一种采用Attach后赋值的方法是执行的按需更新,也就是说更新哪个字段就update它,而第二种则是不管更新了哪个字段,生成的SQL语句都是更新全部。
为什么第一种方法中我Attach后仅仅只是给对象赋值且没有修改State为Modified,但EF却能帮我修改数据值,那是因为
当SaveChanges时,将会自动调用DetectChanges方法,此方法将扫描上下文中所有实体,
并比较当前属性值和存储在快照中的原始属性值。如果被找到的属性值发生了改变,
此时EF将会与数据库进行交互,进行数据更新,所以不用设置State为Modified。
对于删除操作则需要在Attach后设置 db.Entry(user).State = EntityState.Deleted;
借鉴于此,我又封装了一个独立的AttachList方法,此方法仅仅只是将由AsNoTracking 取得的数据附加到上下文中,因为不用关注之后的操作是Update或者Delete所以只用了Attach。
以下截图代码是直接从我的项目中摘取出来展示:
其中最关键的是性能上的提高(就是上述文字标记的地方),当查询大量数据时,使用此方法比不使用而将其附加到上下文容器中,性能提升不是一点点。
6.EF使用SqlQuery
对于某些特殊业务,我们也可以使用sql语句查询实体,以下只是一个简单的事例操作
SqlParameter[] parameter = { };
var user = db.Database.SqlQuery<User>("select * from user", parameter).ToList();
此方法获得的实体查询是在数据库(Database)上,实体不会被上下文跟踪。
SqlParameter[] parameter = { };
var user = db.Set<User>().SqlQuery("select * from user", parameter).ToList(); 此方法获得的实体查询是被上下文跟踪,所以能直接赋值后SaveChanges()。
var user = db.Set<User>().SqlQuery("select * from user").ToList(); user.Last().Name = "makmong"; db.SaveChanges(); 当然同样支持带参数的查询与存储过程操作,我就不一一列出了此处只做点出即可。
7.关于AsNonUnicode
我们执行如下语句
var query = db.User.Where(a=>a.Name=="makmong").ToList();
生成的SQL语句

再试一个语句
var query = db.User.Where(a=>a.Name== DbFunctions.AsNonUnicode("makmong")).ToList();
生成的SQL语句
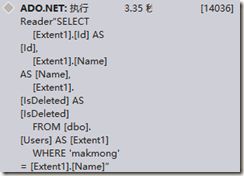
其中生成的SQL语句区别了,一个加了N,一个未加N,N是将字符串作为Unicode格式进行存储。
因为.Net字符串是Unicode格式,在上述SQL的Where子句中当一侧有N型而另一侧没有N型时,此时会进行数据转换,也就是说如果你在表中建立了索引此时会失效代替的是造成全表扫描。
用 DbFunctions.AsNonUnicode 方法来告诉.Net将其作为一个非Unicode来对待,此时生成的SQL语句两侧都没有N型,就不会进行更多的数据转换,也就是说不会造成更多的全表扫描。
所以当有大量数据时如果不进行转换会造成意想不到的结果。
因此在进行字符串查找或者比较时建议用AsNonUnicode()方法来提高查询性能。
8.建议使用ViewModel代替实体Model
大家可能都会碰到这种情况就是Model实体拥有多个字段,但是查询数据到页面展示的时候可能只需要显示那么几个字段,这个时候建议使用ViewModel查询,
也就是说需要哪些字段就查询哪些,而不是 “select *”将全部字段加载出来。此操作即出于安全考虑 (不应该将实体Model直接传递到View上面),同时查询的字段减少 (可能就几个) 对查询性能也有所提升。
例:
var query = db.User.ToList();
对应的查询语句为:
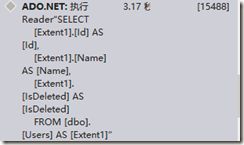
接着新建ViewModel
public class UserViewModel
{
public int Id { get; set; } public string Name { get; set; } } 开始查询:
var query = db.User.Select(a=>new UserViewModel()
{
Id = a.Id,
Name = a.Name
}).ToList();
对应的查询语句为:
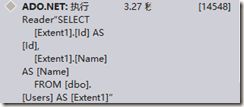
9.建议Model实体中枚举使用byte类型
我们先来了解下Sqlserver中tinyint, smallint, int, bigint的区别
-
bigint:从-263(-9223372036854775808)到263-1(9223372036854775807)的整型数据,存储大小为 8 个字节。一个字节就是8位,那么bigint就有64位
-
int:从-231(-2,147,483,648)到231-1(2,147,483,647)的整型数据,存储大小为 4 个字节。int类型,最大可以存储32位的数据
-
smallint:从-215(-32,768)到215-1(32,767)的整数数据,存储大小为 2 个字节。smallint就是有16位
tinyint:从0到255的整数数据,存储大小为 1 字节。tinyint就有8位。
所以对于有些范围比较短的数值长度,例如枚举类型值,完全可以使用byte类型替换int类型,对应生成数据库tinyint类型以节省数据存储。
如:
public CouponType CouponType { get; set; }
public enum CouponType : byte
{
RedBag = 0, Experience = 1, Cash = 2, JiaXiQuan = 3 } 对应的数据库类型:

此时的CouponType字段对应数据库就是一个tinyint类型
10.Model实体使用DateTime2替换DateTime控制内容值精度
我们先看下 SQL Server中DateTime与DateTime2的区别
-
DateTime字段类型对应的时间格式是 yyyy-MM-dd HH:mm:ss.fff ,3个f,精确到1毫秒(ms),示例 2014-12-03 17:06:15.433 。
-
DateTime2字段类型对应的时间格式是 yyyy-MM-dd HH:mm:ss.fffffff ,7个f,精确到0.1微秒(μs),示例 2014-12-03 17:23:19.2880929 。
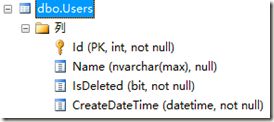
我们知道EF Model的DateTime对应的SQL类型是DateTime
例:
public DateTime CreateDateTime { get; set; }
对应的数据库实体类型:

但是在业务操作中很多时间值我们仅仅只需要精确到秒就够了(特殊业务除外),
那多余的毫秒数既无用又占数据库存储(逼死处女座),既然是优化操作那么我们是否可以去除毫秒数而只存储到秒呢?例:2014-12-03 17:06:15
So我们可以使用特性Attribute及抽象类PrimitivePropertyAttributeConfigurationConvention来达到这一目的。
不多说直接上代码:
[AttributeUsage(AttributeTargets.Property)]
public sealed class DateTime2PrecisionAttribute : Attribute { public DateTime2PrecisionAttribute(byte precision = 0) { Precision = precision; } public byte Precision { get; set; } } public class DateTime2PrecisionAttributeConvention: PrimitivePropertyAttributeConfigurationConvention<DateTime2PrecisionAttribute> { public override void Apply(ConventionPrimitivePropertyConfiguration configuration, DateTime2PrecisionAttribute attribute) { if (attribute.Precision > 7) { throw new InvalidOperationException("Precision must be between 0 and 7."); } configuration.HasPrecision(attribute.Precision); configuration.HasColumnType("datetime2"); } } 理解一下代码,第一句中的AttributeTargets.Property表示可以对属性(Property)应用特性(Attribute)
而构造函数DateTime2PrecisionAttribute则指定了要应用的datetime的精度值。
而最后两句
configuration.HasPrecision(attribute.Precision);
configuration.HasColumnType("datetime2");
则是将我们所定义的类型精度与对应声明数据类型附加给要标记的实体类型。
最后还需要将DateTime2PrecisionAttributeConvention方法注册到我们的DbContext中
public virtual DbSet User { get; set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Conventions.Add(new DateTime2PrecisionAttributeConvention()); } 现在我们再使用此特性在上面的属性CreateDateTime中看下效果吧
结果图:
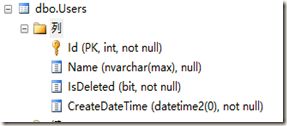

是不是感觉不错。当然基于此拓展,我们也可以扩展我们想要的Model数据类型,如:控制decimal的精度(2位或4位小数),改边nvarchar(max)为我们想要的长度类型(具体情况看业务再优化吧)。
11.合理使用EF扩展库
1.EF实现指定字段的更新
在以往的数据更新操作中我们使用EF的修改都是先查询一次数据附加到上下文中,然后给需要修改的属性赋值,虽说EF能够自动跟踪实体做到按需更新,但更新前查询不仅没有必要,而且增加了额外的开销。EF删除和修改数据只能先从数据库取出,然后再进行删除.
当进行如下操作时:
delete from user where Id>5; update user set Name=”10”; 我们需要这样操作
var t1 = db.User.Where(t => t.Id > 5).ToList();
foreach (var t in t1) { db.User.Remove(t); } db.SaveChanges(); var t2 = db.User.ToList(); foreach (var t in t1) { t.Name = "ceshi"; } db.SaveChanges(); 有没办法做到一条语句操作的更改呢?如“update user set name=’张三’where id=1”。
此时就需要使用EF的扩展库EntityFramework.Extended了。
在github中提供了一个EF扩展库https://github.com/loresoft/EntityFramework.Extended
在VS可以直接通过NuGet安装

安装完成后试验下:
当然需要先引用:
using EntityFramework.Extensions;
编写代码测试及查看结果:
EntityDB db = new EntityDB();
db.User.Where(a => true).Update(a => new User() {Name = "ceshi"}); 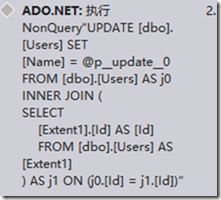
EntityDB db = new EntityDB();
db.User.Where(a => true).Delete(); 
嗯,至于具体选择怎么用,看业务分析哈。
2.批量查询功能
例如:在分页查询的时候,需要查询结果数,和结果集
EF做法:查询两次
var q = db.User.Where(u => u.Name.StartsWith("a")); var count = q.Count(); var data = q.Skip(10).Take(10).ToList(); EF扩展库的做法:一次查询
var q = db.User.Where(t => t.Name.StartsWith("a"));
var q1 = q.FutureCount(); var q2 = q.Skip(10).Take(10).Future(); var data = q2.ToList(); var count = q1.Value; 3.查询缓存功能
我们现在的后台项目权限管理模块,所有的菜单项都是写进数据库里,不同的角色用户所获取展示的菜单项各不相同。
项目导航菜单就是频繁的访问数据库导致性能低下(一开始得到1级菜单,然后通过1级获取2级菜单,2级获取3级)
解决方法就是第一次查询后把数据给缓存起来设定缓存时间,然后一段时间继续查询此数据(譬如整个页面刷新)则直接在缓存中获取,从而减少与数据库的交互。
代码如下:
var users = db.User.Where(u => u.Id > 5).FromCache(CachePolicy.WithDurationExpiration(TimeSpan.FromSeconds(30)));
如果在30秒内重复查询,则会从缓存中读取,不会查询数据库
我们再提出二个问题那就是,
1:第一次查询缓存数据修改后(如:保存到数据库)紧接着继续查询一次,由于缓存时间没有失效,此时在缓存中查询的数据是刚刚修改的最新的吗?
2:在不同的上下文中缓存获取结果是一样的吗?
写代码测试看下:
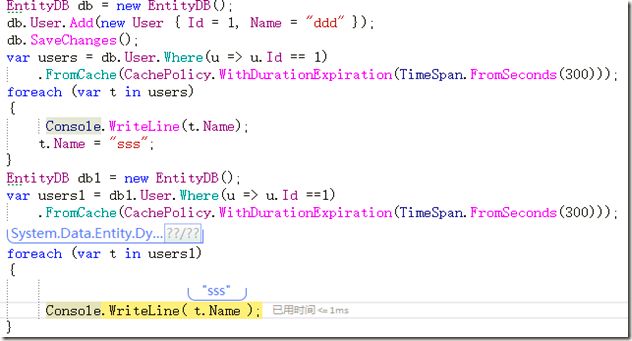
上图中我在第一个上下文中获得数据缓存,然后给Name赋值”sss”,当然此处为了测试缓存是否更新所以我没有做SaveChanges()的操作,然后接着从缓存中获取数据,由结果可知此缓存值也相应的更改了。
因此在一段时间内即使操作修改了数据值也只需要在更改的时候操作一次数据库,减少了与数据库的交互。
另外需要注意的是更改的时候可以根据操作结果选择是否继续缓存,例如数据更改失败但是缓存却改动了,下次取值数据就会不一致,所以当我们在更新数据库失败时就可以选择移除缓存调用RemoveCache()方法。
12.EF使用SQL分库操作
当数据库的表及数据达到一定规模后我们想到的优化就有分库,分表之类的优化操作。
对于之前的ADO.NET来说分库是一件很普通的操作。
比如下面的非跨数据库查询语句:
SELECT Name FROM dbo.User WHERE ID=1 跨数据库查询语句:
SELECT Name FROM MaiMangAdb.dbo.blog_PostBody WHERE ID=1 我们知道EF的DbContext中已经指定了连接字符串
public EntityDB() : base("DefaultConnection") <connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=.;Initial Catalog=EFStudy;Integrated Security=True;" providerName="System.Data.SqlClient" /> connectionStrings> 也就是说所有的上下文操作都是基于这个数据库来操作的,那我们就不能用ADO.NET那套,多个查询配多个链接去操作数据库。
当然大神们也给出了一套方法,而且也是简单明了。那我也就直接将其移植过来记录一下吧。
方法就是给数据库添加SYNONYM 同义词,我在此演示下
创建2张Model表User和Role
public class User
{
[Key]
public int Id { get; set; } public string Name { get; set; } public bool IsDeleted { get; set; } [DateTime2Precision] public DateTime CreateDateTime { get; set; } } public class Role { [Key] public int Id { get; set; } public string Name { get; set; } } 并添加一条语句:
EntityDB db = new EntityDB();
db.User.Add(new User { Id = 1, Name = "ddd" ,CreateDateTime = DateTime.Now}); db.Role.Add(new Role() {Id = 1, Name = "admin"}); db.SaveChanges(); 运行查看数据库:
现在数据库表及内容都有了。然后我要把User表及内容移植到另一个数据库中,且不影响当前的EF操作。
创建新的数据库EFSYNONYM并添加User表,表结构和EFStudy中的User一致。
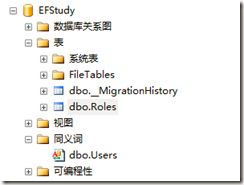
然后在EFStudy中删除表User且创建同义词
CREATE SYNONYM [dbo].[Users] FOR [EFSYNONYM].[dbo].[Users]
效果如图
此时的User和Role已经分别存在于不同的数据库里面,我们来插入查询数据操作下

至此分库成功。当然此方法也有个缺点就是分库表和主表间由同义词关联而无法建立主外键关系(其实当数据量达到一定级别后联合join查询反而不如分开多次查询来得快,
且由于在同一个上下文中,不用太过于关心由数据多次连接开关而产生影响,凡事有利弊总得有个最优是吧),因此我们可以把一些独立的容易过期的数据表给移植到单独的数据库,利于管理同时也利于优化查询。
参考资料
https://www.cnblogs.com/ahao214/p/9431910.html
http://blog.jd-in.com/947.html