介绍
眼科医生是否青光眼主要诊断方法是观察视网膜眼底图像。然而,仍然难以仅通过手动观察来区分病变特征,特别是在青光眼早期。
这项工作是一场研讨会挑战-视网膜眼底青光眼挑战(REFUGE)。挑战的目标是评估和比较在视网膜眼底图像的通用数据集上进行青光眼检测和视盘/杯分割的自动算法。我们提出了两种解决方案,这些解决方案在分割和分类任务上均达到了最佳性能。该解决方案有可能扩展到新颖的方法或应用程序
在本文中,作者介绍了两种基于深度学习的自动算法,用于青光眼检测以及视盘和杯分割。利用注意力机制来学习像素级特征以进行准确的预测。特别是,我们提出了两个卷积神经网络,它们可以专注于学习各种像素级特征。此外,我们制定了几种注意力策略来指导网络学习对预测准确性有重大影响的重要特征。我们在验证数据集上评估我们的方法,提出的两个任务的解决方案都可以取得令人印象深刻的结果,并且胜过当前的最新方法。
作者信息

方法
细分
作者采用类似于u-net 的架构来学习不同的像素级功能。我们将u-net修改为具有多个输入(本例中为3个)可以在训练期间接收更多原始的原始像素信息。这种策略可以减少过度安装的风险,并增强网络的学习能力。我们将此架构称为X Unet。此外,我们将挤压和激励块嵌入到我们的X-Unet中,以加权来自不同卷积层通道的特征。利用一种机制,允许网络选择性地放大有价值的通道功能,并从全局信息中抑制无用的功能。另外,我们在网络解码器部分使用反卷积,通过拒绝不同级别编码特征和相应级别解码特征之间的特征来改进解码能力。下图图显示了我们的X-Unet的体系结构。
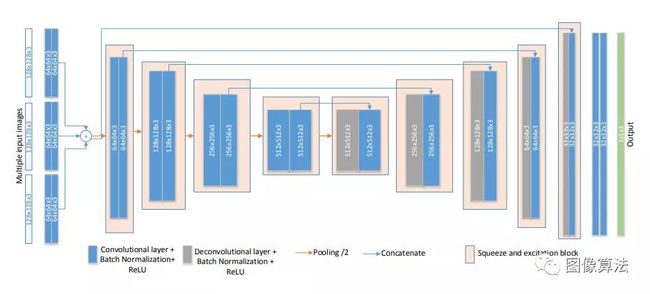
图1. X-Unet的体系结构包括挤压和激励块。
回归我们将分割任务视为图像回归,而不是像素分类问题,在深度学习中,这通常需要将低级像素信息转换为高级特征。但是,对于光盘和杯子二进制分割任务,低级别的像素级功能更为重要。与学习对像素进行分类相反,将视网膜图像直接映射到其对应的标签可以保留更多的低像素级特征.
损失函数训练图像中主要的逐像素相似性使我们可以采用平均绝对误差(MAE)作为损失函数来计算标记和预测之间的逐像素差异。
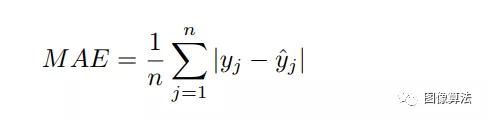
其中n是像素数;ˆyj是预测像素;yj是实际像素。
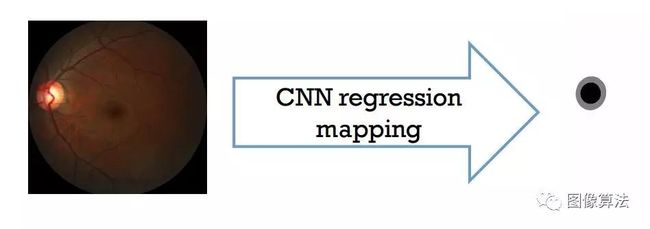
图2.将分割视为图像回归,而不是像素分类问题。
分类
视盘的区域和周围区域包含关键的像素明智特征,例如垂直盘直径,盘/杯的椭圆形形状,ISNT规则和橙黄色边缘,主要用于区分 青光眼。包括像素颜色和位置在内的各种比例的像素级特征比高级特征更为重要,高级特征可以通过非常深的卷积神经网络(例如Resnet )来学习。Atrous(膨胀)卷积是一种关键方法,可以提取不同的比例尺特征并同时保留位置信息。
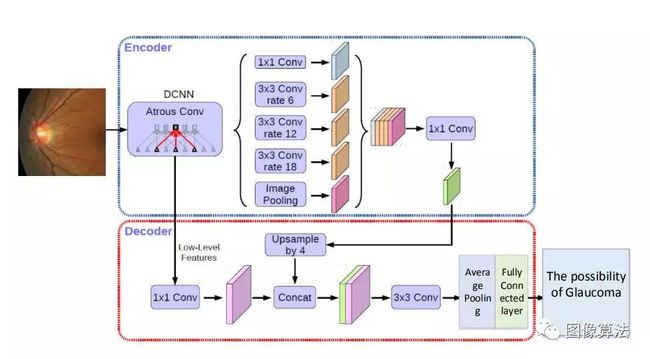
图3.用于青光眼分类的Deeplab + 3变体架构。 我们用平均池化层和完全连接层替换最后一个上采样层。
作者将DeepLab + 3修改为分类器,将最后一层替换为全局平均池化层,然后再替换为完全连接的层,以预测青光眼的风险可能性。DeepLab + 3包含一个编码器和一个解码器。编码器将无用的空间金字塔池(ASPP)和卷积嵌入级联,以提取各种比例上下文上下文像素信息。解码器拒绝通过无意识卷积和编码器的各种比例上下文特征学习到的低级特征。
损失函数我们利用二进制熵函数来计算谓词类(可能性)与实际类之间的差。
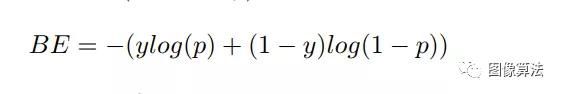
其中BE表示二进制熵损失的值;y是二进制指示符(0或1);p是预测概率。
实施细节
数据预设我们通过使用预先训练的模型:感知光盘的集合网络(DE-Net)裁剪600×600大小的感兴趣区域(ROI)补丁来减少训练图像与验证图像之间的差异。这种数据处理还可以使模型专注于学习最重要的像素信息。

图4.进行分段和分类训练以及测试数据的数据预设步骤。
作者使用数据增强技能(例如,图像旋转-90/180/270各种角度和图像翻转)来增加训练图像的数量。总共生成了3200张ROI图像用于分割和分类训练。为了确保网络的接收范围足够,我们将训练补丁的大小调整为较小的尺寸128×128,作为细分任务训练的输入。对于分类任务,我们在分割中使用相同的方法(图3)裁剪出用于训练和测试的ROI。我们将原始裁剪区域图像的大小调整为各种尺寸,例如216×216、256×256、286×286、324×324和360×360,以进行多次深度网络训练。我们将模型输出平均作为最终的预测结果。

图5.分类训练数据的数据预设步骤。
另外需要处理训练图像和验证图像之间的图像大小差异。因此在验证图像的测试阶段,我们为分割任务裁剪出500×500(不是训练中的600×600)ROI,而为分类任务裁剪为800×800(不是训练中的1024×1024)ROI。这样可以确保网络的输入尽可能类似于训练图像。
其他对于培训平台,我们使用Keras + tensorflow + python2.7。使用Adam优化器,学习率为0.0001。
结果
对于细分,在训练集上,Optic Cup Dice为0.9626,Optic Cup Dice为0.9876,MAE CDR为0.0161。
在验证集上,Optic Cup Dice= 0.8498,Optic Cup Dice= 0.9433,MAE CDR为0.0444。最佳排名(在线结果):第8。
对于分类,在训练集上AUC:1.0,灵敏度:1.0。发生了潜在的过度拟合。在验证集上,AUC为0.9708,灵敏度为0.95。
最新(结果在线)排名:第二。
结论
在这项工作中,作者提出了两个用于视网膜眼底青光眼分割和检测的深度学习网络。为了克服主要挑战,例如训练和测试图像之间的差异(由于不同的采集设备而导致的颜色和大小),作者采用了像素级学习和注意力策略,这可以使网络专注于直接学习关键特征,像素级准确预测。特别是,我们提出了一个多输入UNet,称为X-Unet,以放大原始图像像素信息,以进行低级特征回归和预测。对于分类,我们提出了如何学习分类问题的像素特征。详细地说,基于扩张的(Atrous)卷积网络可以提取不同的比例尺特征,并同时保留位置信息。多孔空间金字塔池(ASPP)和卷积可以提取各种比例上下文上下文像素信息。编码器部分学习各种按像素划分的特征,而解码器部分拒绝通过膨胀卷积与编码器的各种缩放上下文特征学习的低级特征。我们提出的方法可以克服训练和测试数据之间的差异问题。但是,作者认为拥有健壮模型的最佳方法是为任何基于深度学习的模型标准化图像质量。
论文地址源码下载地址:关注“图像算法”微信公众号 回复"RLPA"