Discord的增长速度及用户生成的内容超出了我们的预期。有了更多的用户,更多的聊天信息就会出现。7月,我们计划每天有4000万条消息,12月我们每天达到1亿条消息,截至本博客帖子,我们每天数据量已经超过了1.2亿条。我们很早就决定永远保存所有聊天记录,这样用户就可以随时回来,在任何设备上都可以使用他们的数据。这大量的数据,其速度、大小都在不断增加,我们必须保证他们的可用性。我们该怎么做呢?答案就是Cassandra!
我们在做什么
Discord的原始版本是在2015年初的不到两个月内构建的。可以说,最快的迭代数据库之一是MongoDB。 Discord上的所有内容都存储在一个MongoDB副本集中,这是有意的,但我们还计划了一切,以便轻松迁移到新数据库(我们知道我们不会使用MongoDB分片,因为它使用起来很复杂而且不知道其稳定性)。这实际上是我们公司文化的一部分:快速实现产品功能去对产品进行试错,但始终通向更强大的解决方案。
这些消息存储在MongoDB集合中,在channel_id和created_at字段上具有单个复合索引。 2015年11月左右,我们存储了1亿条消息,此时我们开始看到预期出现的问题:数据和索引不再适合RAM,延迟开始变得不可预测。是时候迁移到更适合该任务的数据库了。
选择正确的合适数据库
在选择新数据库之前,我们必须了解读/写模式以及我们当前的解决方案会导致出现问题的原因。
- 很快就发现我们的读取非常随机,我们的读/写比率约为50/50。
- Discord 的语音聊天服务几乎不发送任何消息。这意味着他们每隔几天发一两条信息。在一年之内,这种服务器消息量在1000条以内。问题是,尽管这是一小部分消息,但它使向用户提供这些数据变得更加困难。比如只向用户返回50条消息会导致在磁盘上进行许多随机查找,从而导致磁盘缓存收回。
- Discord的私有文本聊天服务发送了相当多的消息,很容易达到每年10万到100万条消息。他们请求的数据通常只是最近产生的。问题是,由于这些服务器的成员通常不到100个,因此请求此数据的速度很低,不太可能位于磁盘缓存中。
- 大型公共Discord服务器发送大量消息。他们有成千上万的会员每天发送数千封邮件,每年轻松收集数百万封邮件。他们几乎总是在获取过去一小时内发送的消息,并且他们经常获取这些消息。因此,这些数据通常位于磁盘缓存中。
- 我们知道,在接下来的一年里,我们将为用户提供更多的随机阅读方式:查看过去30天内您提到的内容,然后跳到历史上的那个点,查看并跳到固定邮件,以及全文搜索。所有这些拼写都更随意!!
接着下来是我们系统的要求
- 线性的可扩展性 - 我们不希望稍后重新考虑解决方案或手动重新分片数据。
- 故障自动转移 - 我们喜欢在晚上睡觉,并尽可能地建立Discord自我修复功能。
- 维护成本低 - 一旦我们设置它就应该工作。我们只需要在数据增长时添加更多节点。
- 事实证明(Proven to work) - 我们喜欢尝试新技术,但不是太新。
-可预测的性能 - 当我们的API响应时间第95百分位数超过80毫秒时,我们会发出警报。我们也不想在Redis或Memcached中缓存消息。 - 存储方式不是blob(Not a blob store ) - 如果我们必须不断地反序列化blob并将其附加到Blob存储区中,那么每秒写入数千条消息将不会很好。
- 开源 - 我们相信控制自己的命运,不想依赖第三方公司。
Cassandra是唯一满足我们所有要求的数据库。我们可以添加节点来扩展节点,它可以容忍节点丢失而不会对应用程序产生任何影响。 Netflix和Apple等大公司拥有数千个Cassandra节点。相关数据连续存储在磁盘上,提供最小的搜索并在群集周围轻松分发。它得到了DataStax的支持,但仍然是开源和社区驱动的。
做出选择后,我们需要证明我们选择的确是对的。
数据模型
将Cassandra为新手描述的最佳方式是它是KKV存储。两个K包括主键。第一个K是分区键,用于确定数据所在的节点以及磁盘上的位置。分区中包含多个行,分区中的行由第二个K标识,第二个K是集群key。群集key既充当分区中的主键,又充当行的排序方式。您可以将分区视为有序字典。结合这些属性可实现非常强大的数据建模。
你还记得我们之前使用channel_id和created_at在MongoDB中索引消息? channel_id成为分区键,因为所有查询都在一个通道上运行,但created_at没有成为一个很好的集群键,因为两个消息可以具有相同的创建时间。幸运的是,Discord上的每个ID实际上都是Snowflake(按时间顺序排序),所以我们可以使用它们。主键变为(channel_id,message_id),其中message_id是Snowflake。这意味着在加载channel 时,我们可以准确地告诉Cassandra扫描消息的范围。
这是我们的消息表的简化模式(这省略了大约10列)。
CREATE TABLE messages (
channel_id bigint,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY (channel_id, message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
Cassandra的schemas 与关系数据库不同,它们的改变成本很低廉,并且不会对临时性能产生任何影响。我们得到了最好的blob存储和关系存储。
当我们开始将现有消息导入Cassandra时,我们立即在日志中看到警告,告诉我们分区的大小超过100MB。发生什么事了?! Cassandra宣称它可以支持2GB分区!显然,仅仅因为它可以完成,它并不意味着它应该。在压缩,集群扩展等过程中,大型分区会对Cassandra造成很大的GC压力。拥有大分区也意味着其中的数据无法在群集中分布。很明显,我们必须以某种方式限制分区的大小,因为单个Discord通道可以存在多年并且不断增大。
我们决定按时间播放我们的消息。我们查看了Discord上最大的channel(频道),并确定我们是否在一个存储桶中存储了大约10天的消息,我们可以轻松地保持在100MB以下。存储桶必须可以从message_id或时间戳中导出。
DISCORD_EPOCH = 1420070400000
BUCKET_SIZE = 1000 * 60 * 60 * 24 * 10
def make_bucket(snowflake):
if snowflake is None:
timestamp = int(time.time() * 1000) - DISCORD_EPOCH
else:
# When a Snowflake is created it contains the number of
# seconds since the DISCORD_EPOCH.
timestamp = snowflake_id >> 22
return int(timestamp / BUCKET_SIZE)
def make_buckets(start_id, end_id=None):
return range(make_bucket(start_id), make_bucket(end_id) + 1)
Cassandra分区键可以组合,因此我们的新主键变为((channel_id,bucket),message_id)。
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
为了查询频道中的最近消息,我们生成从当前时间到channel_id的桶范围(它也是Snowflake并且必须比第一条消息更旧)。然后我们依次查询分区,直到收集到足够的消息。这种方法的缺点是很少有活动的Discords必须查询多个桶以随时间收集足够的消息。在实践中,这被证明是好的,因为对于活动的Discords,通常在第一个分区中找到足够的消息,并且它们占大多数。
将消息导入Cassandra顺利进行,我们已准备好投入正式使用。
Dark Launch(注: 是Fackbook使用的一种测试产品新功能的测试方法)
将新系统引入生产总是很可怕,所以尝试在不影响用户的情况下进行测试是个好主意。我们设置代码以对MongoDB和Cassandra进行双重 读/写操作。
启动后我们立即开始在错误跟踪器中收到错误,告诉我们author_id为空。怎么会是null?这是一个必填字段!
最终一致性
Cassandra是一个AP数据库,这意味着它可以提供强大的可用性一致性,这是我们想要的。它是Cassandra中的read-before-write(读取更昂贵)的反模式,因此即使你只提供某些列,Cassandra所做的一切本质上都是一个upsert。您还可以写入任何节点,它将使用每列的“last write wins”语义来自动解决冲突。那我们会遇到坑么?
在用户同时编辑消息而另一个用户删除相同消息的情况下,我们最终得到的行缺少除主键和文本之外的所有数据,因为所有Cassandra写入都是upserts。处理此问题有两种可能的解决方案:
1.编辑消息时写回整个消息。这有可能恢复被删除的消息,并为并发写入其他列的冲突增加更多机会。
2.弄清楚该消息是否是脏数据并从数据库中删除它。
我们选择了第二个选项,我们选择了一个必需的列(在本例中为author_id)并删除了该消息(如果它为null)。
在解决这个问题时,我们注意到我们的写入效率非常低。由于Cassandra最终是一致的,它不能立即删除数据。它必须将删除复制到其他节点,即使其他节点暂时不可用也要执行此操作。 Cassandra通过将删除视为一种称为“墓碑”的写入形式来实现这一点。在阅读时,它只是跳过它遇到的墓碑。'墓碑' 在配置的时间内(默认为10天)存在,并且在该时间到期时会在执行压缩操作后被永久删除。
删除列或将null写入列里他们效果完全相同,他们都会生成墓碑。由于Cassandra中的所有写入都是upserts,这意味着即使在第一次写入null时,您也会生成一个逻辑删除。实际上,我们的整个消息模式包含16列,但平均消息只设置了4个值。这样我们大部分时间都无缘无故地向Cassandra写了12个墓碑。解决方案很简单:只向Cassandra写入非空值。
性能
众所周知,Cassandra的写入速度比读取速度快,我们确实观察到了这一点。写入是亚毫秒,读取时间不到5毫秒。我们观察到这一点,无论访问什么数据,并且在一周的测试期间性能保持一致。没有什么是令人惊讶的,和我们预期效果差不多。
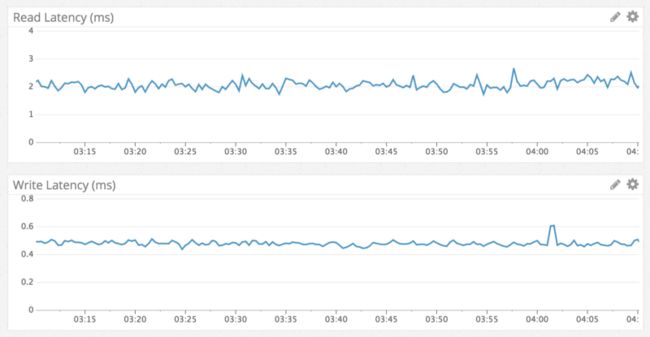
In line with fast,一致的读性能,这里是一个一年前在包含数百万条消息的频道中跳转到消息的示例:
一个大惊喜
一切顺利,所以我们将其作为主要数据库推出,并在一周内逐步淘汰MongoDB。它继续完美地工作......大约6个月,直到有一天Cassandra反应变得很迟钝。
我们注意到Cassandra经常运行10秒“stop-the-world”GC,但我们不知道为什么。我们开始研究并找到一个耗时20秒的Discord频道。由于它是公开的,我们加入它看看情况。令我们惊讶的是,该频道只有一条消息。就在那一刻,很明显他们使用我们的API删除了数百万条消息,在频道中只留下了一条消息。
如果您一直在关注,您可能还记得Cassandra如何使用墓碑处理删除(在最终一致性中提到)。当用户加载此频道时,即使只有一条消息,Cassandra也必须有效地扫描数百万条消息(注:cassandra读取到消息到再和墓碑里的delete消息进行合并操作,如果墓碑里的delete操作有成千上万那么他合并操作就会有点费时)逻辑删除(生成垃圾的速度比JVM可以收集的速度快)。
我们通过以下方式解决了这个问题:
- 我们将墓碑的寿命从10天缩短到2天,因为我们每天晚上在我们的消息集群上进行Cassandra修复(repair操作,他会进行压缩操作)。
- 我们更改了查询代码以跟踪空桶,并在将来避免使用它们作为通道。这意味着如果用户再次引发此查询,那么在最糟糕的情况下,Cassandra将仅在最近的桶中进行扫描。
结论
自从我们进行转换以来已经过去了一年多,尽管“出人意料”,但它一帆风顺。我们从处理总量为1亿条消息到每天超过1.2亿条消息,性能和稳定性保持很好。
由于该项目的成功,我们已将线上的数据移至Cassandra,这也取得了成功。
在本文的后续内容中,我们将探讨如何使数十亿条消息可搜索。
我们还没有专门的DevOps工程师(只有4个后端工程师),因此拥有一个我们不必担心的系统非常棒。我们正在招聘,所以如果这种类型的东西刺激你的想法加入我们。
原文:https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7