姓名:崔升 学号:14020120005
转载自:http://www.cnblogs.com/en-heng/p/5719101.html
【嵌牛导读】:
Apriori作为一种经典的处理大数据的算法,是我们在学习互联网大数据时不得不去了解的一种常用算法
【嵌牛鼻子】:经典大数据算法之Apriori简单介绍
【嵌牛提问】:Apriori是一种怎么的算法,其如何做到关联分析的?
【嵌牛正文】:
1. 关联分析
关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。比如,在著名的购物篮事务(market basket transactions)问题中,
TIDIterms
1{Bread, Milk}
2{Bread, Diapers, Beer, Eggs}
3{Milk, Diapers, Beer, Cola}
4{Bread, Milk, Diapers, Beer}
5{Bread, Milk, Beer, Cola}
关联分析则被用来找出此类规则:顾客在买了某种商品时也会买另一种商品。在上述例子中,大部分都知道关联规则:{Diapers} → {Beer};即顾客在买完尿布之后通常会买啤酒。后来通过调查分析,原来妻子嘱咐丈夫给孩子买尿布时,丈夫在买完尿布后通常会买自己喜欢的啤酒。但是,如何衡量这种关联规则是否靠谱呢?下面给出了度量标准。
支持度与置信度
关联规则可以描述成:项集 → 项集。项集XX出现的事务次数(亦称为support count)定义为:
σ(X)=|ti|X⊆ti,ti∈T|σ(X)=|ti|X⊆ti,ti∈T|
其中,titi表示某个事务(TID),TT表示事务的集合。关联规则X⟶YX⟶Y的支持度(support):
s(X⟶Y)=σ(X∪Y)|T|s(X⟶Y)=σ(X∪Y)|T|
支持度刻画了项集X∪YX∪Y的出现频次。置信度(confidence)定义如下:
s(X⟶Y)=σ(X∪Y)σ(X)s(X⟶Y)=σ(X∪Y)σ(X)
对概率论稍有了解的人,应该看出来:置信度可理解为条件概率p(Y|X)p(Y|X),度量在已知事务中包含了XX时包含YY的概率。
对于靠谱的关联规则,其支持度与置信度均应大于设定的阈值。那么,关联分析问题即等价于:对给定的支持度阈值min_sup、置信度阈值min_conf,找出所有的满足下列条件的关联规则:
支持度>=min_sup置信度>=min_conf支持度>=min_sup置信度>=min_conf
把支持度大于阈值的项集称为频繁项集(frequent itemset)。因此,关联规则分析可分为下列两个步骤:
生成频繁项集F=X∪YF=X∪Y;
在频繁项集FF中,找出所有置信度大于最小置信度的关联规则X⟶YX⟶Y。
暴力方法
若(对于所有事务集合)项的个数为dd,则所有关联规则的数量:
====∑idCid∑jd−iCjd−i∑idCid(2d−i−1)∑idCid∗2d−i−2d+1(3d−2d)−2d+13d−2d+1+1∑idCdi∑jd−iCd−ij=∑idCdi(2d−i−1)=∑idCdi∗2d−i−2d+1=(3d−2d)−2d+1=3d−2d+1+1
如果采用暴力方法,穷举所有的关联规则,找出符合要求的规则,其时间复杂度将达到指数级。因此,我们需要找出复杂度更低的算法用于关联分析。
2. Apriori算法
Agrawal与Srikant提出Apriori算法,用于做快速的关联规则分析。
频繁项集生成
根据支持度的定义,得到如下的先验定理:
定理1:如果一个项集是频繁的,那么其所有的子集(subsets)也一定是频繁的。
这个比较容易证明,因为某项集的子集的支持度一定不小于该项集。
定理2:如果一个项集是非频繁的,那么其所有的超集(supersets)也一定是非频繁的。
定理2是上一条定理的逆反定理。根据定理2,可以对项集树进行如下剪枝:

项集树共有项集数:∑dk=1k×Ckd=d⋅2d−1∑k=1dk×Cdk=d⋅2d−1。显然,用穷举的办法会导致计算复杂度太高。对于大小为k−1k−1的频繁项集Fk−1Fk−1,如何计算大小为kk的频繁项集FkFk呢?Apriori算法给出了两种策略:
Fk=Fk−1×F1Fk=Fk−1×F1方法。之所以没有选择Fk−1Fk−1与(所有)1项集生成FkFk,是因为为了满足定理2。下图给出由频繁项集F2F2与F1F1生成候选项集C3C3:

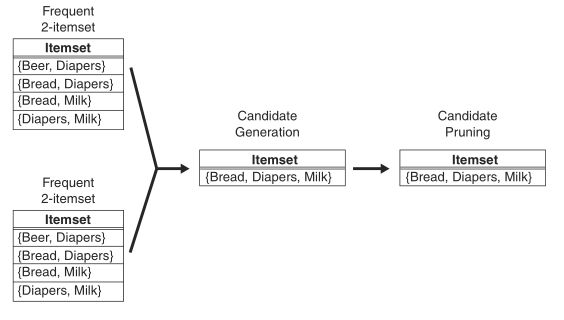
Fk=Fk−1×Fk−1Fk=Fk−1×Fk−1方法。选择前k−2k−2项均相同的fk−1fk−1进行合并,生成Fk−1Fk−1。当然,Fk−1Fk−1的所有fk−1fk−1都是有序排列的。之所以要求前k−2k−2项均相同,是因为为了确保FkFk的k−2k−2项都是频繁的。下图给出由两个频繁项集F2F2生成候选项集C3C3:
生成频繁项集FkFk的算法如下:

关联规则生成
关联规则是由频繁项集生成的,即对于FkFk,找出项集hmhm,使得规则fk−hm⟶hmfk−hm⟶hm的置信度大于置信度阈值。同样地,根据置信度定义得到如下定理:
定理3:如果规则X⟶Y−XX⟶Y−X不满足置信度阈值,则对于XX的子集X′X′,规则X′⟶Y−X′X′⟶Y−X′也不满足置信度阈值。
根据定理3,可对规则树进行如下剪枝:

关联规则的生成算法如下:

3. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar,Introduction to Data Mining.