提到dependency parser,我们就会想到自然语言处理,而句法分析是自然语言处理领域的一个关键问题,dependency parser作为句法分析中的一个文法体系,近年来,成为研究热点,并且逐渐广泛应用于其他自然语言处理任务中。飞马网于3月21日晚,邀请到上海交大计算机科学与信息硕士,先后在UBS和蚂蚁金服工作过的胡翔老师,在直播中为我们分享关于dependency parser的研究进展以及它的一些主流方法等相关内容。

以下是本次分享内容:
一.自然语言理解的主要解决问题
我们首先要了解一下自然语言理解领域想要解决的几个问题。自然语言处理的领域非常广,信息检索、智能问答、情感分析、自动翻译等等,都可以说是这个领域非常难且有待解决的问题,今天我们主要讨论的是语义表达及知识表达。

我们先从一个简单的例子着手,来了解一下语义表达。下面这张图片的两句话,放到现在的语义自动匹配模型里,几乎相同,但为什么到人类理解这里,这两句话就是完全不同的意思呢?
从语义角度来说,一句话的含义是有层次和主要元素的,主要元素用学术性的话语说就是语义框架,也就是我们所说的“主谓宾”。虽然不是所有的句子都会有主谓宾覆盖,但我们这里,先拿一个主谓宾的句子举个例子。
主谓宾的句式可以理解为,这个句子里面有三个不同类型的槽,每个槽只能填一个字或词。一旦我们把两句话结构化之后,它们的区别就十分明显了。
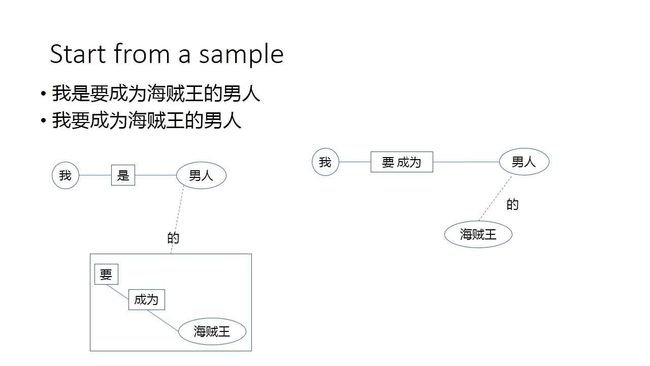
所以问题就来了,有没有一种结构化的表达方式,可以有效地解决语义表达这个问题?我们细想一下,这个问题其实有几大难点。首先,如果说存在这样一种结构,那么这个结构一定要具有普适性,其次,更难的问题是,如何让计算机实现把一个序列化的句子转化成这种结构。
二.自然语言理解的几种主流理论
接下来的部分,我们就来谈谈目前解决这两个问题的方法以及思考。自然语言理解主要有以下三种主流理论。

1.Phrase structure(句法结构):
这套理论是由乔姆斯基提出的,在句法结构中,一个非终结符只能生成小于等于两个非终结符,或者生成一个终结符。
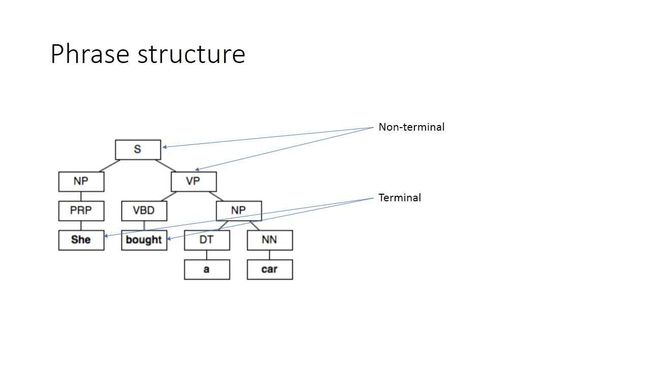
非终结符就是这张图里面,像“S、NP、VP”等这些没有实词的标签,在我们构成树状节点的结构中,它下面还会有子节点,有子节点的节点,我们都称之为非终结符。
终结符就是这张图里面,像“she、bought、car”等这些具体的实词,是树状结构中的叶子节点。
我们从句子层面看,一句话可以根据语义的层次性,即它们之间的紧密型,被表达成一个二叉树,如上图所示。
那这个句法结构有什么缺陷呢?我们看下图,首先它是一个强序列要求的结构。其次,它不是各种语言通用的框架,依赖于特定语言规则,普适性很差。最后,它反映的语义信息比较有限。

2.Dependency structure(一层句法):
它通过用词与词之间的有效边来表示语法关系,因此在形式上会更简单、直观。
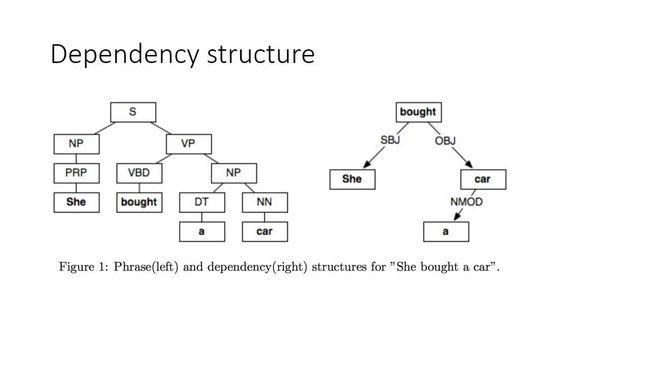
在上图这个例子里面,我们可以看到一条边SBJ,也就是指句子的主语,OBJ就是指句子的宾语,NMOD就是指名词的修饰词,它通过边的类型来定义词与词之间的关系。而边的类型比较多,目前有三十几种。
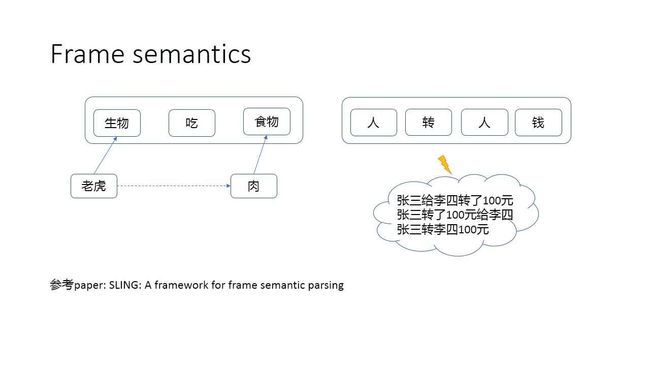
3.Frame semantics(框架语义):
它相比于之前的两个理论,更偏重于语义及知识表达,这套理论认为一个完整的表达是要结合背景知识的。比如“吃”这个词,不能独立于知识来讨论这个词应该怎么用,而要把它放在完整的语义结构中。“转”这个词也是如此。
三.Dependency parser的意义
Dependency parser是我们今天的主讲内容,所以我们就dependency parser来讨论它的主要意义是什么。其实要讨论dependency parser的意义,这可能是个比较难的话题,因为它是自然语言处理领域里面一项比较基础的研究,但它真正在实际应用中的效果,主要有以下几方面:
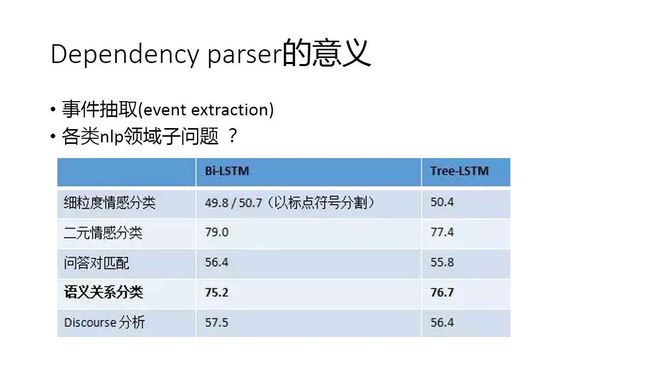
我们可以看到,Tree-LSTM较Bi-LSTM并没有很明显的优势,所以“结构化是不是有必要”,仍然是一个争议点,在胡翔老师看来,他认为这个话题对dependency parser的研究相当于是对语言本质的一些揭露,它的研究成果对理解自然语言很有帮助,虽然它不一定在实际应用中起到效果。
四.Dependency parser的结构
在传统的dependency parser结构中,有以下几个限制:
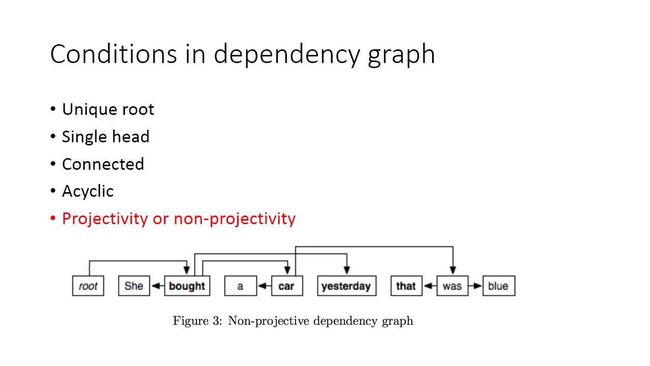
在这些条件下,自然而言最后构成的结果是一棵树。存在争议的一点是,我们构成一个dependency parser结构的时候,有交叉还是无交叉,实际上,支持交叉,句子表达的语义性更强,但相继引来的pass难度也会更高。
依存句法结构的规范了解完之后,我们来介绍它的几种主流pass方法。所谓的parser就是教会计算机把一句话自动地翻译成所规范的结构,因此我们就要有一些方法,帮助计算机能够结合上下文或某些操作,来缩小它的搜索范围和空间,有效地去构成一棵树。
1.Transition-based parser:
这是最经典的方法,transition-based简单来说是它定义的一系列操作,我们只要用这一系列的操作一路做下去,最后就能把它变成一棵树,这是直观一点的理解。

这种pass方法主要基于状态转移,我们来看下面这张图中的例子,来直观地了解一下具体过程:
shift的功能是把当前临时站I站顶里面的token或一个结构,往左边的S站里压一个。
然后我们看到图三里的Left-Arc(向左形成一条弧)操作,它的具体意义是从I和S里面各取一个元素弹出来,画一条左弧把它们连起来,丢到最右边的A里面,A的意义是一个操作历史。
在“she”和“bought”之间形成一条左弧,左弧的意义是,弧向哪边指,被指向的那个token是作为子节点,指别人的token是作为一个父节点,在这里,“bought”就作为一个父节点重新被压到站里面,之后的操作就是不断循环往复,一直做到I站为空,这时候过程终止。
A站表示这个过程当中的操作记录,我们通过A站看到形成的弧是哪些,就能形成一棵树。
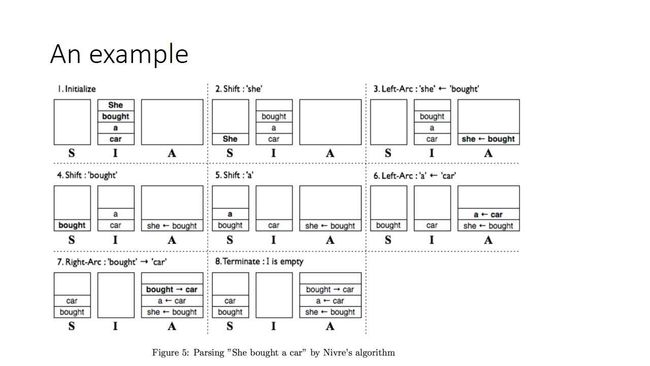
这个算法的意义主要是,“我永远只操作我这句话最前面的两个token”,可以这么理解,transition-based parser是通过基于局部词的组合,来进行局部的合并,一直到把整个东西“吃”完。它在运行性能上有优势,包含更多的语义性。
2.Graph-based parser:
相比于上面局部的方法,graph-based parser就是一种全局的方法。
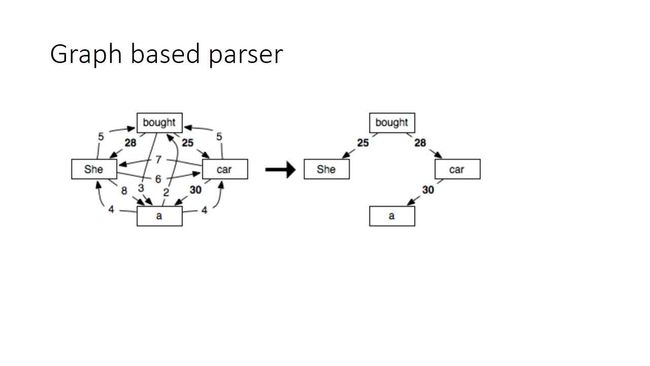
它的核心思想是,不管每个词之间的距离,把词与词的关系密切性变成一个值,然后生成一个对角树,生成这个树的路径就是dependency parser的路径。它的优势是能够实现局部最优解,因此它不会因为之前的误差,导致全局最后的pass结果错误。
五.基于deep learning的parser model介绍
最后我们介绍基于transition-based理论的一些deep learning模型。
1.Transition-based methods:
它的主要思路是先把一个句子变成句法树,再变成dependency parser,这个方法有点舍近求远,但它的效果不错。它同样会定义一些操作,即在一个序列上不断做这些操作,直到结束,就能形成一棵树。主要有以下三种操作:
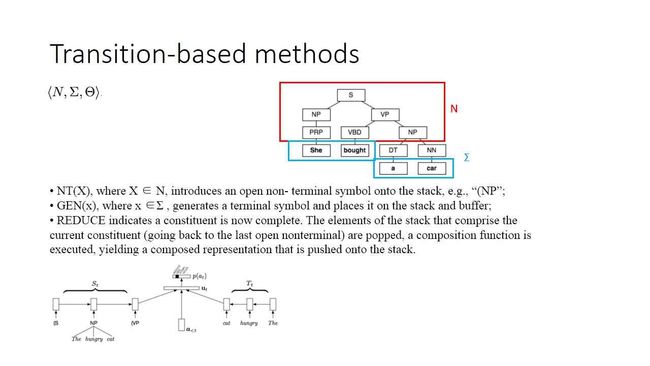
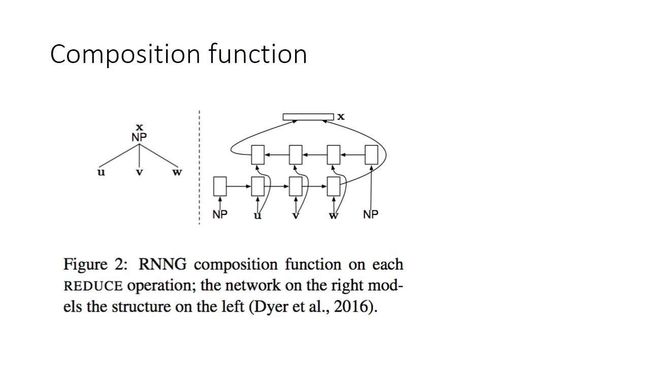
这个模型就是在序列中,插左括号或右括号的非典型性序列打标问题,deep learning在里面起的作用是,每一个左括号和右括号封闭的token,把它们表达成一个更高级的含义。
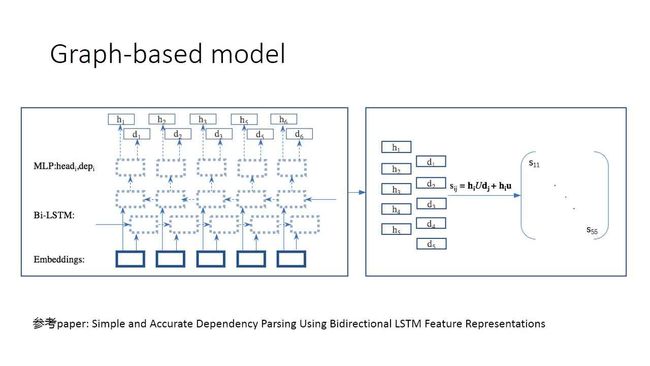
2.Graph-based model:
这个模型是把之前构建数的问题变成距离计算的问题。它本质做的事情是建立一个矩阵,行和列都是这个句子里的token,每两个行列中的一个点表示a修饰b的概率或b修饰a的概率的一个得分,最后要形成树,我们就是在这个距离向量中找一棵最小生成树,生成出来的就是dependency parser。
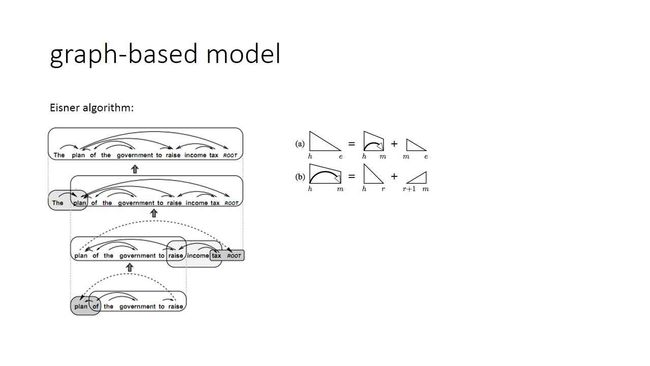
所以在deep learning的模型里面,比较重要的就是怎么去计算这个距离向量,同样的,也是因为有word embedding的发现,让我们能够把一个句子变成连续向量。
那么在实际应用中,dependency parser有多少意义呢?我们不能否认dependency parser的意义,但它有几点很大的限制:

那么为什么中文准确率会那么低呢?主要有以下两点:

为了解决这个问题,我们设计了一种简化标注的思路:
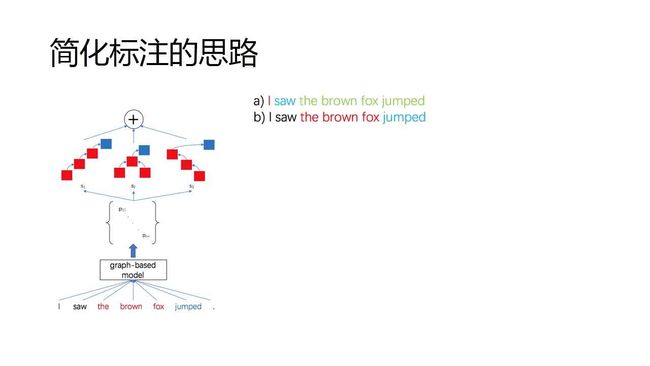
怎么简化呢?就是让标注人员去标这里面的语义结构,识别里面的语义块,但它仍然有缺陷,我们只能强化学习。
以上所有部分就是这次线上直播的主要分享内容,相信你一定对dependency parser有了更深入的认识,想了解更多更详细内容的小伙伴们,可以关注服务号:FMI飞马网,点击菜单栏飞马直播,即可进行学习。
