查看帮助
?jiebaR #在Rstudio中 该包的帮助文档
jiebaR中文分词文档
这个很详细很强大
还有微信上看到有人的分享文章也不错:http://mp.weixin.qq.com/s/PJ5bCtodjxikcSbynEZ8Dw
本文就是在参照以上资料写的
两个重要函数:
- worker
- segment
worker是最重要的一个函数。
函数使用方法(获取帮助):
?worker
语法:
worker(type = "mix", dict = DICTPATH, hmm = HMMPATH, user = USERPATH,
idf = IDFPATH, stop_word = STOPPATH, write = T, qmax = 20, topn = 5,
encoding = "UTF-8", detect = T, symbol = F, lines = 1e+05,
output = NULL, bylines = F, user_weight = "max")
worker()用于新建分词引擎。
worker()有很多参数。
worker()初始化参数
worker(
type = "mix",
dict = DICTPATH,
hmm = HMMPATH,
user = USERPATH,
idf = IDFPATH,
stop_word =
STOPPATH,
write = T,
qmax = 20,
topn = 5,
encoding = "UTF-8",
detect = T,
symbol = F,
lines = 1e+05,
output = NULL,
bylines = F)
- type
指分词引擎类型,这个包括mix,mp,hmm,full,query,tag,simhash,keyword,分别指混合模型,支持最大概率,隐形马尔科夫模型,全模式,索引模式,词性标注,文本Simhash相似度比较,关键字提取。
具体为:
mp(最大概率模型)- 基于词典和词频
hmm(HMM模型)- 基于HMM模型,可以发现词典中没有的词
mix(混合模型)-先用mp分,mp分完调用hmm再把剩余的可能成词的单字分出来
query(索引模型)-mix基础上,对大于一定长度的词再进行一次切分
tag(标记模型)-词性标记,基于词典的
keywords(关键词模型)- tf-idf抽 关键词
simhash(Simhash) - 在关键词的基础上计算simhash
- dict系统词典
系统词典。词库路径,默认为jiebaR::DICTPATH。
jiebaR::DICTPATH
[1] "D:/R-3.4.0/library/jiebaRD/dict/jieba.dict.utf8" #这个是我这里的路径
打开jieba.dict.utf8,如下(包括词、词频、词性标注三列):
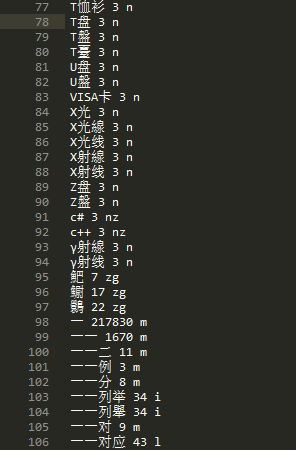
看了这个图片,大概就有了一个直观的认识。
也可以读取前n条查看:
readLines(jiebaR::DICTPATH,5)
user用户词典
用户自定义的词库,用户词典,包括词、词性标注两列(只有词一列也可以)。
用户词典中的所有词的词频均为系统词典中的最大词频(默认,可以通过user_weight参数修改)
user= 后面直接接文件路径。User_weight
用户词典中词的词频,默认为"max",系统词典的最大值。
还可以选择"min"最小值或"median"中位数
- idf IDF词典
IDF 词典,关键词提取使用。
- stop_word 关键词用停止词库
关键词提取使用的停止词库。
分词时也可以使用,但是分词时使用的对应路径不能为默认的jiabaR::STOPPATH
- write 写入文件
是否将文件分词结果写入文件,默认为否。只在输入内容为文件路径时,本参数才会被使用。本参数只对分词和词性标注有效。
qmax 最大索引长度
词的最大查询长度,默认为20,可用于query分词类型topn 关键词数
关键词的个数,默认为5,可以用于simhash和keyword分词类型
encoding输入文件编码
默认为UTF-8.detect检测编码
是否检查输入文件的编码,默认检查。symbol 保留符号
输出是否保留符号(标点符号),默认为False。lines 读取行数
每次读取文件的最大行数,用于控制读取文件的长度。
对于大文件,实现分次读取。output 输出路径
指定输出路径,一个字符串路径。只在输入内容为文件路径时,本参数才会被使用。bylines 按行输出
文件结果是否按行输出。如果是,则将读入的文件或字符串向量按行逐个进行分词操作。
另外一个函数是segment.
它有三个参数,code好比任务,jiebar就是一个worker,mod参数告诉worker怎么做,也就是什么分词引擎分词。
?segment
Usage
segment(code, jiebar, mod = NULL)
Arguments
code
A Chinese sentence or the path of a text file.
jiebar
jiebaR Worker.
mod
change default result type, value can be "mix","hmm","query","full","level", or "mp"
1.分词
library(jiebaRD)
library(jiebaR)
engine <- worker() #这个默认参数,未进行特别设置
words <- "晚上早早就睡觉但是睡不着,白天又很早就醒。为了改变现状,我决定用早起倒逼早睡,最终达到早睡早起的目的。"
segment(words,engine)
[1] "晚上" "早早" "就" "睡觉" "但是"
[6] "睡不着" "白天" "又" "很" "早就"
[11] "醒" "为了" "改变现状" "我" "决定"
[16] "用" "早起" "倒逼" "早睡" "最终"
[21] "达到" "早睡早起" "的" "目的"
这个地方,"很早" "就"是这样的。它是"很" "早就"的。
2.添加用户自定义词或词库
这个有两种方法:
- 使用
new_user_word函数; - 使用
worker函数中通过user参数添加词库
这里我想让"很早"在一起,”早早就“也在一起。
new_user_word函数
engine_new_word <- worker()
new_user_word(engine_new_word,c("早早就","很早"))
segment(words,engine_new_word)
[1] "晚上" "早早就" "睡觉" "但是" "睡不着"
[6] "白天" "又" "很早" "就" "醒"
[11] "为了" "改变现状" "我" "决定" "用"
[16] "早起" "倒逼" "早睡" "最终" "达到"
[21] "早睡早起" "的" "目的"
使用user参数添加词库
自定义一个词库
zidingyi.txt
文件内容:
早早就
很早
getwd() #这里看下工作目录,把zidingyi.txt文件放到该路径下即可
engine_user <- worker(user = "zidingyi.txt")
segment(words,engine_user)
[1] "D:/Rdata"
[1] "晚上" "早早就" "睡觉" "但是" "睡不着"
[6] "白天" "又" "很早" "就" "醒"
[11] "为了" "改变现状" "我" "决定" "用"
[16] "早起" "倒逼" "早睡" "最终" "达到"
[21] "早睡早起" "的" "目的"
注意下哦:
- 词库的第一行空着,不然第一个词默认不起作用了
- 新建txt文件可能默认编码为ASCII,另存下选择编码为UTF-8
3.添加停止词以删除
这里,删除"又"、"的"这样的词
使用worker函数的stop_word参数
新建stopwords.txt文件,同上
engine_s <- worker(stop_word = "stopwords.txt")
segment(words,engine_s)
[1] "晚上" "早早" "就" "睡觉" "但是"
[6] "睡不着" "白天" "很" "早就" "醒"
[11] "为了" "改变现状" "我" "决定" "用"
[16] "早起" "倒逼" "早睡" "最终" "达到"
[21] "早睡早起" "目的"
4.统计词频
jiebaR包,提供了一个函数freq来自动计算获取词频。
freq(segment(words,engine_s))
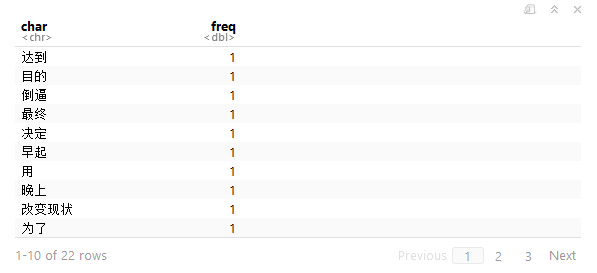
这个函数自动计算了words分词后的词频。
之后就可以用wordcloud2绘制词云(这里词频太少啦)
//
jiebaR包提供了一个** qseg**函数,它也可以分词:
两种使用方法:
qseg[words]
qseg<=words
5.词性标注
词性标注可以使用worker函数的type参数。
type默认参数为mix,将它设置为tag。
engine_tag <- worker(type = "tag") ##设置type
segment(words,engine_tag)
t t d v c v
"晚上" "早早" "就" "睡觉" "但是" "睡不着"
t d zg d v p
"白天" "又" "很" "早就" "醒" "为了"
n r v p v v
"改变现状" "我" "决定" "用" "早起" "倒逼"
v d v vn uj n
"早睡" "最终" "达到" "早睡早起" "的" "目的"
6.提取关键字
把worker函数的参数type设置为keyword或simhash,使用参数topn设置提取关键词的个数,默认为5.
keys <- worker(type = "keywords",topn = 2) ##设置type
keys<=words #这个是更方便的一种写法//还可以用segment函数做
11.9548 11.5028
"改变现状" "早睡早起"
jiebaR的大部分功能都可以通过worker函数来实现。
可参考jiebaR的主页:
http://qinwenfeng.com/jiebaR/
附上关于worker()参数的英文说明(具体参数使用可以实际操作以下)。
Arguments
type
The type of jiebaR workers including mix, mp, hmm, full, query, tag, simhash, and keywords.
dict
A path to main dictionary, default value is DICTPATH, and the value is used for mix, mp, query, full, tag, simhash and keywords workers.
hmm
A path to Hidden Markov Model, default value is HMMPATH, full, and the value is used for mix, hmm, query, tag, simhash and keywords workers.
user
A path to user dictionary, default value is USERPATH, and the value is used for mix, full, tag and mp workers.
idf
A path to inverse document frequency, default value is IDFPATH, and the value is used for simhash and keywords workers.
stop_word
A path to stop word dictionary, default value is STOPPATH, and the value is used for simhash, keywords, tagger and segment workers. Encoding of this file is checked by file_coding, and it should be UTF-8 encoding. For segment workers, the default STOPPATH will not be used, so you should provide another file path.
write
Whether to write the output to a file, or return a the result in a object. This value will only be used when the input is a file path. The default value is TRUE. The value is used for segment and speech tagging workers.
qmax
Max query length of words, and the value is used for query workers.
topn
The number of keywords, and the value is used for simhash and keywords workers.
encoding
The encoding of the input file. If encoding detection is enable, the value of encoding will be ignore.
detect
Whether to detect the encoding of input file using file_coding function. If encoding detection is enable, the value of encoding will be ignore.
symbol
Whether to keep symbols in the sentence.
lines
The maximal number of lines to read at one time when input is a file. The value is used for segmentation and speech tagging workers.
output
A path to the output file, and default worker will generate file name by system time stamp, the value is used for segmentation and speech tagging workers.
bylines
return the result by the lines of input files
user_weight
the weight of the user dict words. "min" "max" or "median".