摘要:预训练语言模型如BERT等已经极大地提高了多项自然处理任务的性能,然而预训练语言模型通常具需要很大计算资源,所以其很难在有限的资源设备上运行。为了加速推理、减小模型的尺寸而同时保留精度,首先提出了一个新颖的迁移蒸馏方法,它是一种基于迁移方法的知识蒸馏思路。利用整个新颖的KD方法,大量的知识编码在一个大的“老师”BERT可以很好地被迁移到一个小的“学生”TinyBERT模型那里。我们引入一个新的两阶段学习TinyBERT学习框架,在预训练阶段和任务明确任务学习阶段都采用迁移蒸馏方式,整个框架可以保证TinyBERT能够捕捉到BERT中通用域和明确域的知识。
TinyBERT在经验上是有效的,其性能能够超过基线BERT的96%,容量小7.5倍,推理速度快9.4倍。同时,TinyBERT要比基线DistillBERT也明显更优,只有其28%的参数,31%的推理时间。
构建TinyBERT,首先提出新的迁移蒸馏方法能够从BERT中蒸馏知识嵌入,并构建多个损失函数:1)embedding层输出;2)隐含层状态和注意力矩阵;3)预测层的logits输出
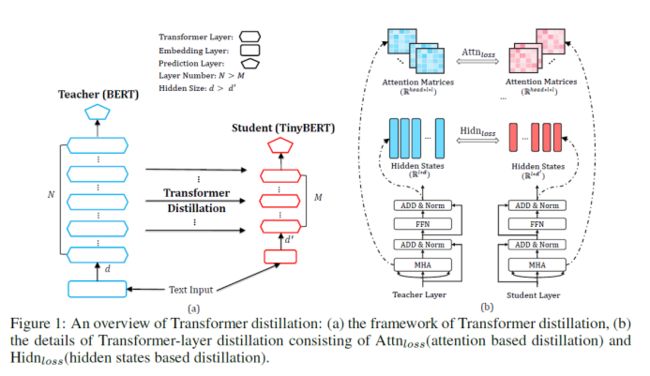
标准的transformer层包括多头注意力(MHA)和全连接前馈网络层(FFN),整体框架如下图:
最小化目标函数,那么学生模型便可以从老师模型那里获得知识:
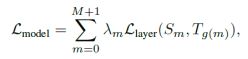
Transformer-layer 蒸馏:
包括基于注意的蒸馏和基于隐含状态的蒸馏。基于注意力的蒸馏受启发于:通过BERT中的注意力权重可以获取丰富的语言学知识,这些语言学知识含有语法和共指信息,这些信息都是自然语言理解的基础,所以,学生模型应当学习拟合老师模型中的多头注意力权重,通过如下目标函数:
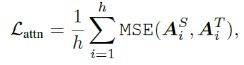
在此,不仅蒸馏注意力矩阵的参数,而且还有蒸馏Transformer输出层的参数,如下目标函数:
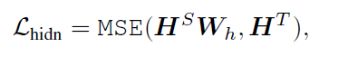
嵌入层蒸馏:
![]()
预测层蒸馏,同传统蒸馏方式保持一致:
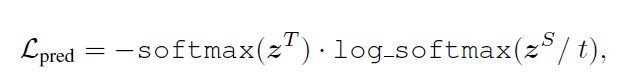
总损失:
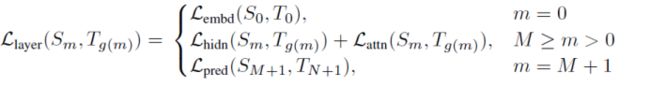
模型训练:
l 通用模式蒸馏
使用原始BERT预训练方式,通过以上的蒸馏步骤获取通用TinyBERT。经此步骤后,由于隐含层、嵌入层以及模型层数都减少了,通用TinyBERT效果要比BERT的表现差的多
l 确定任务蒸馏
需要一个增强明确任务的数据集,也就是使用数据做模型增强,数据增强是一个能够扩展特定任务中训练集的方法。通过学习更多任务相关的样本,学生模型的泛化能力可以进一步提升。研究者在数据增强阶段结合了 BERT 和 GloVe 的方法,进行词级别的替换,以此来增强数据
这两种策略是互补的:通用模式知识蒸馏能够为确定任务蒸馏提供一个很好的初始化,而明确任务蒸馏可以聚焦学习特定任务知识。
实证研究结果表明,TinyBERT 是有效的,在 GLUE 基准上实现了与 BERT 相当(下降 3 个百分点)的效果,并且模型大小仅为 BERT 的 13.3%(BERT 是 TinyBERT 的 7.5 倍),推理速度是 BERT 的 9.4 倍。此外,TinyBERT 还显著优于当前的 SOTA 基准方法(BERT-PKD),但参数仅为为后者的 28%,推理时间仅为后者的 31%左右
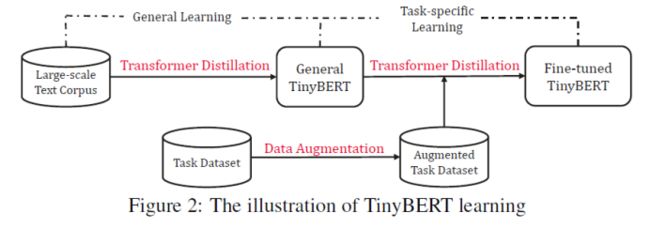
两段式蒸馏方式:预训练(知识蒸馏)+微调(知识蒸馏)
本质:在pre-training蒸馏一个general TinyBERT,然后再在general TinyBERT的基础上利用task-bert上再蒸馏出fine-tuned TinyBERT
作者表示,之后他们会测试 TinyBERT 在中文任务上的表现、尝试使用哪吒或 ALBERT 作为教师模型进行蒸馏,以及公开性能更好的模型等