- 排序
路小白同学
1.冒泡排序冒泡算法是一种基础的排序算法,这种算法会重复的比较数组中相邻的两个元素。如果一个元素比另一个元素大(小),那么就交换这两个元素的位置。重复这一比较直至最后一个元素。这一比较会重复n-1趟,每一趟比较n-j次,j是已经排序好的元素个数。每一趟比较都能找出未排序元素中最大或者最小的那个数字。这就如同水泡从水底逐个飘到水面一样。冒泡排序是一种时间复杂度较高,效率较低的排序方法。其空间复杂度是
- 【Python】数据结构,链表,算法详解
AIAdvocate
python数据结构链表排序算法广度优先深度优先
今日内容大纲介绍自定义代码-模拟链表删除节点查找节点算法入门-排序类的冒泡排序选择排序插入排序快速排序算法入门-查找类的二分查找-递归版二分查找-非递归版分线性结构-树介绍基本概述特点和分类自定义代码-模拟二叉树1.自定义代码-模拟链表完整版"""案例:自定义代码,模拟链表.背景: 顺序表在存储数据的时候,需要使用到连续的空间,如果空间不够,就会导致扩容失败,针对于这种情况,我们可以通过链表实现
- C语言暑假学习刷题——Day4
奋斗小温
C语言c语言学习java
目录选择题考点一:for循环的理解考点二:while循环和循环嵌套的理解考点三:break在switch语句中的应用考点四:升序插入排序算法的应用考点五:循环嵌套的理解编程题【leetcode题号:645.错误的集合】【难度:简单】【牛客网题号:OR141密码检查】【难度:简单】选择题考点一:for循环的理解1、设变量已正确定义,以下不能统计出一行中输入字符个数(不包含回车符)的程序段是()A:n
- windows C++-并行编程-并行算法(五) -选择排序算法
sului
windowsC++并行编程技术c++windows
并行模式库(PPL)提供了对数据集合并行地执行工作的算法。这些算法类似于C++标准库提供的算法。并行算法由并发运行时中的现有功能组成。在许多情况下,parallel_sort会提供速度和内存性能的最佳平衡。但是,当您增加数据集的大小、可用处理器的数量或比较函数的复杂性时,parallel_buffered_sort或parallel_radixsort性能更佳。确定在任何给定方案中使用哪种排序算法
- 12312312
二进制掌控者
c++
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c++,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm=1001.2014.3001.5343给大家分享一句我很喜欢我话:知不足而奋进,望远山而前行!!!铁铁们,成功的路上必然是孤独且艰难的,但是我们不可以放弃,远山就在前方,但我们
- 你知道什么是回调函数吗?
二进制掌控者
#C语言专栏c语言开发语言
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c++,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm=1001.2014.3001.5343给大家分享一句我很喜欢我话:知不足而奋进,望远山而前行!!!铁铁们,成功的路上必然是孤独且艰难的,但是我们不可以放弃,远山就在前方,但我们
- 【ShuQiHere】快速排序(Quick Sort):揭开高效排序算法的神秘面纱
ShuQiHere
排序算法算法数据结构
【ShuQiHere】引言在计算机科学中,排序算法是我们日常编程不可或缺的一部分。无论是处理大量数据、优化搜索引擎,还是进行系统性能提升,排序算法都起到了至关重要的作用。在所有的排序算法中,快速排序(QuickSort)凭借其高效性和灵活的分治策略成为最受欢迎的排序算法之一。在这篇博客中,我们将深入探讨快速排序的原理、性能分析以及如何通过优化策略进一步提升其效率。1.什么是快速排序?(QuickS
- 【ShuQiHere】从插入排序到归并排序:探究经典排序算法的魅力与实战应用
ShuQiHere
排序算法算法
【ShuQiHere】引言在计算机科学领域,排序算法是我们日常编程中经常会遇到的基本问题。无论是对数据进行排序、查找,还是优化复杂系统,排序算法都起着至关重要的作用。在这篇文章中,我们将详细探讨两种经典排序算法:插入排序和归并排序,通过对它们的原理、时间复杂度和实际应用场景的分析,帮你更好地理解并灵活应用这些算法。1.插入排序:像整理扑克牌一样排序插入排序(InsertionSort)是一种简单且
- 常见排序算法及算法的稳定性
CocoaAndYy
排序算法数据结构算法
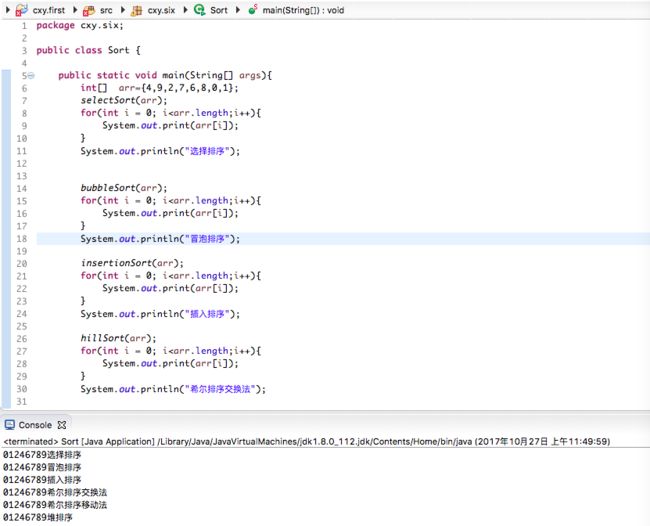
目录1.选择排序2.冒泡排序3.插入排序排序的稳定性1.选择排序每次选出最小的元素,与当前元素进行交换;保持前面的元素不变简单选择排序是最简单直观的一种算法,基本思想为每一趟从待排序的数据元素中选择最小(或最大)的一个元素作为首元素,直到所有元素排完为止,简单选择排序是不稳定排序。//简单选择排序publicstaticvoidselectSort(int[]arr){for(inti=0;iar
- C#排序算法新境界:深度剖析与高效实现基数排序
AitTech
算法排序算法c#算法
基数排序(RadixSort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数进行比较。具体来说,基数排序有两种方法:最低位优先(LSD,LeastSignificantDigitfirst):从最低位开始,向最高位进行排序。最高位优先(MSD,MostSignificantDigitfirst):通常用于字符串的排序,从最高位开始,向最低位进行排序,且常使用递归实
- 9.9日记录
冰榫
排序算法数据结构算法
1.常见排序算法的复杂度1.快速排序1.1快速排序为什么快从名称上就能看出,快速排序在效率方面应该具有一定的优势。尽管快速排序的平均时间复杂度与“归并排序”和“堆排序”相同,但通常快速排序的效率更高,主要有以下原因。出现最差情况的概率很低:虽然快速排序的最差时间复杂度为O(N的平方),没有归并排序稳定,但在绝大多数情况下,快速排序能在O(nlogN)的时间复杂度下运行。缓存使用效率高:在执行哨兵
- CSP-J 算法基础 选择排序
人才程序员
CSP-J算法排序算法数据结构比赛noi青少年编程竞赛
文章目录前言选择排序选择排序的过程最终结果编程实现选择排序总结前言选择排序(SelectionSort)是一种简单直观的排序算法,其工作原理是每次从未排序的部分中选出最小(或最大)的元素,将其与当前的第一个元素交换位置,然后缩小未排序部分的范围。每一轮都会找到剩余部分中的最小元素,逐步构建一个有序的数组。选择排序的时间复杂度为O(n²),不适合大数据集,但由于其实现简单,通常被用于教学和理解基本排
- PHP常用的几种算法
每天瞎忙的农民工
phpphp算法算法php
PHP常用的算法涵盖了多种场景,包括排序、加密、搜索、数据结构、字符串处理等。在实际开发中,根据业务需求,会选择合适的算法来优化性能和解决问题。以下是几种常见的PHP算法:1.排序算法排序算法用于将数据按一定的顺序排列。PHP内置了很多排序函数,例如sort()、rsort()、usort()等,但以下是几种常见的排序算法的手动实现:(1)冒泡排序冒泡排序是一种简单的排序算法,通过重复地交换相邻的
- 【软考】希尔排序算法分析
王佑辉
软考算法算法软考
目录1.c代码2.运行截图3.运行解析1.c代码#include#includevoidshellSort(intdata[],intn){//划分的数组,例如8个数则为[4,2,1]int*delta;intk;//i控制delta的轮次inti;//临时变量,换值inttemp;intdk;intj;k=n;delta=(int*)malloc(sizeof(int)*(n/2));i=0;d
- [排序算法]-拿捏堆排序法
芫荽_
DataStructure&Algorithms二叉树算法数据结构排序算法堆排序
彻底搞懂堆排序法基本介绍核心思想实例讲解主要思路图示演示代码实现基本介绍建堆-交换,往复进行至有序。——爱因斯坦核心思想堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆,注意:没有要求结点的左孩子的值和右孩子的值的大小关系。
- 数据结构--经典排序之快速排序(超详细!!)
鲁鲁修•vi•不列颠尼亚
数据结构算法排序算法
文章目录快速排序代码实现测试用例快速排序快速排序(QuickSort)是一种高效的排序算法,由英国计算机科学家霍尔(C.A.R.Hoare)在1960年提出。它的基本思想是,通过一次排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。算法步骤选择基准值(pivot
- 百度文库文章-暂存下-------题 目: 链式简单选择排序
weixin_62349327
数据结构算法
题目:链式简单选择排序初始条件:理论:学习了《数据结构》课程,掌握了基本的数据结构和常用的算法;实践:计算机技术系实验室提供计算机及软件开发环境。要求完成的主要任务:(包括课程设计工作量及其技术要求,以及说明书撰写等具体要求)1、系统应具备的功能:(1)用户自己输入数据的个数和数据;(2)建立链表;(3)基于链表的排序算法实现。2、数据结构设计;3、主要算法设计;4、编程及上机实现;5、撰写课程设
- 数据结构--经典排序之选择排序(超详细!!)
鲁鲁修•vi•不列颠尼亚
数据结构算法排序算法
文章目录选择排序代码实现使用示例选择排序选择排序(SelectionSort)是一种简单直观的排序算法。它的工作原理是,首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。选择排序的主要优点是与数据规模较小,其在待排序的数据规模较小时,效率较高,且实现简单。但是其缺点是不
- 前端面试题系列之-数据结构及算法篇
wowoqu
排序算法篇一、冒泡排序冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。算法描述比较相邻的元素。如果第一个比第二个大,就交换它们两个;对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这
- Java经典算法之选择排序(Selection Sort)
在知识的行业里狗刨
java算法排序算法快速排序数据结构
2选择排序选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。2.1算法描述n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:初始状态:无序区为R[1…n],有序区为空
- 算法之选择排序(Selection Sort)
cancer_t
技术java算法
表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。然后,再从剩余未排序元素中继续寻找最
- Python之10道最高频的手撕代码题
Ooo。
python代码实操
目录1、快速排序2、二分查找3、爬楼梯4、两数之和5、最大回撤6、合并两个有序数组7、最大连续子数组和8、最长不重复子串9、全排列10、三数之和源于:公众号Python与算法之美1、快速排序题目形式:手写一下快速排序算法。题目难度:中等。出现概率:约50%。手写快排绝对是手撕代码面试题中的百兽之王,掌握了它就是送分题,没有掌握它就是送命题。参考代码:defquick_sort(arr,start=
- 前端算法面试题3--排序、搜索、分治
临夏_
算法
排序:冒泡排序、快速排序、插入排序...搜索:二分搜索、顺序搜索...工具理解:https://visualgo.net/zh排序冒泡排序--交换冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较每对相邻的项,然后交换它们的顺序(如果需要)。遍历列表的工作是重复地进行直到没有更多需要交换的元素,也就是说列表已经排序完成了。functionbubbleSort(arr){letlen=ar
- lambda表达式简析及应用案例
极致人生-010
lambda数据
文章目录Lambda表达式的基本概念不同语言中的Lambda表达式示例PythonJava8及以上版本JavaScript(ES6+)C++使用场景高级用法注意事项实际应用场景Java应用案例1.数据处理:使用`Stream`APIC++应用案例2.排序算法中的比较操作Python应用案例3.动态创建函数4.字典分组JavaScript应用案例5.事件监听器总结Lambda表达式是一种简洁的、内联
- 推荐Rerank二次重排序算法
陈敬雷-充电了么-CEO兼CTO
算法人工智能hadoop机器学习人工智能大数据数据挖掘编程语言
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】推荐Rerank二次重排序算法前言推荐的Rerank排序有两种情况,一个是离线计算的时候为每个用户提前用Rerank排序算法算好推荐结果,另一个是在实时在线Web推荐引擎里做二次融合排序的时候。但不管哪一种用到的算法是一样的。比如用逻辑回归、随机森
- 高等排序——分割与快速排序
Se_ren_di_pity
数据结构排序算法算法
快速排序是最经常使用的排序算法,其时间复杂度为O(nlogn),且空间占用为常数在学习快速排序之前,我们先引入一个题目,学习分割的思想,这是实现快速排序的前提分割假定给出一个数组A,要求在下标q至r范围内,将其分割为p到q-1与q+1到r两个部分,并返回下标q的值,其中A[p,q-1]中的所有元素均小于等于A[q],而A[q+1,r]中的所有元素均大于A[q]我们将A[p,q-1]称作数组C,A[
- 07-希尔排序(Shell Sort)
ducktobey
希尔排序(ShellSort)希尔排序是唐纳德·希尔(DonaldShell)在0959年提出的。希尔排序与其他的排序算法不一样,非常有意思。希尔排序是把序列看做是一个矩阵,分成m列,逐列进行排序。m从某个整数逐渐减为1当m为1时,整个序列完全有序你现在看到这些,可能还是很迷糊的,不过不要紧,你现在只需要知道,希尔排序这种算法非常特殊,是将序列分为m列进行逐列排序即可。由于希尔排序的特性,所以也被
- 【算法】Java实现常用排序算法二(希尔排序、归并排序、计数排序、桶排序、基数排序)
傲丿奈我何
算法算法java排序算法数据结构
本博文是排序算法的第二篇,前作指路:【算法】JAVA实现常用排序算法一(冒泡排序、选择排序、插入排序、堆排序、快速排序)Java实现常用排序二前言希尔排序原理流程分析代码实现归并排序原理流程分析代码实现计数排序原理流程分析代码实现桶排序原理流程分析代码实现基数排序原理流程分析代码实现后记前言学习算法最绕不开的就是排序,虽然这是个信息爆炸的时代,但搜索到的毕竟是别人的,特此总结了一下常用的几种排序,
- 数据结构 哈希表 五大排序算法 二分查找(折半查找)
安亿103
数据结构排序算法c语言linux软件构建算法
1、哈希表1.1创建哈希表哈希表:将数据通过哈希算法映射称为一个键值存时在键值对应的位置存储取时通过键值对应的位置查找哈希冲突(哈希碰撞):多个数据通过哈希算法映射成同一个键值#include#include#include#include"list.h"#defineINDEX10structlist_headhashtable[INDEX];typedefstructData{structli
- 数据结构(五)——哈希表,数据排序方法
m0_6793018756
数据结构散列表算法
哈希表:哈希:将数据通过哈希算法映射称为一个键值存时在键值对应的位置存储取时通过键值对应的位置查找哈希冲突(哈希碰撞):多个数据通过哈希算法映射成同一个键值存储数字:排序算法:1.冒泡排序:简单2.选择排序:交换次数少,交换的数据所占空间较大时,适用于选择排序(较少交换次数带来的时间开销)时间复杂度:冒泡排序O(n^2)选择排序O(n^2)插入排序O(n^2)已经有序的数据使用插入排序时间复杂度为
- Nginx负载均衡
510888780
nginx应用服务器
Nginx负载均衡一些基础知识:
nginx 的 upstream目前支持 4 种方式的分配
1)、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2)、weight
指定轮询几率,weight和访问比率成正比
- RedHat 6.4 安装 rabbitmq
bylijinnan
erlangrabbitmqredhat
在 linux 下安装软件就是折腾,首先是测试机不能上外网要找运维开通,开通后发现测试机的 yum 不能使用于是又要配置 yum 源,最后安装 rabbitmq 时也尝试了两种方法最后才安装成功
机器版本:
[root@redhat1 rabbitmq]# lsb_release
LSB Version: :base-4.0-amd64:base-4.0-noarch:core
- FilenameUtils工具类
eksliang
FilenameUtilscommon-io
转载请出自出处:http://eksliang.iteye.com/blog/2217081 一、概述
这是一个Java操作文件的常用库,是Apache对java的IO包的封装,这里面有两个非常核心的类FilenameUtils跟FileUtils,其中FilenameUtils是对文件名操作的封装;FileUtils是文件封装,开发中对文件的操作,几乎都可以在这个框架里面找到。 非常的好用。
- xml文件解析SAX
不懂事的小屁孩
xml
xml文件解析:xml文件解析有四种方式,
1.DOM生成和解析XML文档(SAX是基于事件流的解析)
2.SAX生成和解析XML文档(基于XML文档树结构的解析)
3.DOM4J生成和解析XML文档
4.JDOM生成和解析XML
本文章用第一种方法进行解析,使用android常用的DefaultHandler
import org.xml.sax.Attributes;
- 通过定时任务执行mysql的定期删除和新建分区,此处是按日分区
酷的飞上天空
mysql
使用python脚本作为命令脚本,linux的定时任务来每天定时执行
#!/usr/bin/python
# -*- coding: utf8 -*-
import pymysql
import datetime
import calendar
#要分区的表
table_name = 'my_table'
#连接数据库的信息
host,user,passwd,db =
- 如何搭建数据湖架构?听听专家的意见
蓝儿唯美
架构
Edo Interactive在几年前遇到一个大问题:公司使用交易数据来帮助零售商和餐馆进行个性化促销,但其数据仓库没有足够时间去处理所有的信用卡和借记卡交易数据
“我们要花费27小时来处理每日的数据量,”Edo主管基础设施和信息系统的高级副总裁Tim Garnto说道:“所以在2013年,我们放弃了现有的基于PostgreSQL的关系型数据库系统,使用了Hadoop集群作为公司的数
- spring学习——控制反转与依赖注入
a-john
spring
控制反转(Inversion of Control,英文缩写为IoC)是一个重要的面向对象编程的法则来削减计算机程序的耦合问题,也是轻量级的Spring框架的核心。 控制反转一般分为两种类型,依赖注入(Dependency Injection,简称DI)和依赖查找(Dependency Lookup)。依赖注入应用比较广泛。
- 用spool+unixshell生成文本文件的方法
aijuans
xshell
例如我们把scott.dept表生成文本文件的语句写成dept.sql,内容如下:
set pages 50000;
set lines 200;
set trims on;
set heading off;
spool /oracle_backup/log/test/dept.lst;
select deptno||','||dname||','||loc
- 1、基础--名词解析(OOA/OOD/OOP)
asia007
学习基础知识
OOA:Object-Oriented Analysis(面向对象分析方法)
是在一个系统的开发过程中进行了系统业务调查以后,按照面向对象的思想来分析问题。OOA与结构化分析有较大的区别。OOA所强调的是在系统调查资料的基础上,针对OO方法所需要的素材进行的归类分析和整理,而不是对管理业务现状和方法的分析。
OOA(面向对象的分析)模型由5个层次(主题层、对象类层、结构层、属性层和服务层)
- 浅谈java转成json编码格式技术
百合不是茶
json编码java转成json编码
json编码;是一个轻量级的数据存储和传输的语言
在java中需要引入json相关的包,引包方式在工程的lib下就可以了
JSON与JAVA数据的转换(JSON 即 JavaScript Object Natation,它是一种轻量级的数据交换格式,非
常适合于服务器与 JavaScript 之间的数据的交
- web.xml之Spring配置(基于Spring+Struts+Ibatis)
bijian1013
javaweb.xmlSSIspring配置
指定Spring配置文件位置
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/spring-dao-bean.xml,/WEB-INF/spring-resources.xml,
/WEB-INF/
- Installing SonarQube(Fail to download libraries from server)
sunjing
InstallSonar
1. Download and unzip the SonarQube distribution
2. Starting the Web Server
The default port is "9000" and the context path is "/". These values can be changed in &l
- 【MongoDB学习笔记十一】Mongo副本集基本的增删查
bit1129
mongodb
一、创建复本集
假设mongod,mongo已经配置在系统路径变量上,启动三个命令行窗口,分别执行如下命令:
mongod --port 27017 --dbpath data1 --replSet rs0
mongod --port 27018 --dbpath data2 --replSet rs0
mongod --port 27019 -
- Anychart图表系列二之执行Flash和HTML5渲染
白糖_
Flash
今天介绍Anychart的Flash和HTML5渲染功能
HTML5
Anychart从6.0第一个版本起,已经逐渐开始支持各种图的HTML5渲染效果了,也就是说即使你没有安装Flash插件,只要浏览器支持HTML5,也能看到Anychart的图形(不过这些是需要做一些配置的)。
这里要提醒下大家,Anychart6.0版本对HTML5的支持还不算很成熟,目前还处于
- Laravel版本更新异常4.2.8-> 4.2.9 Declaration of ... CompilerEngine ... should be compa
bozch
laravel
昨天在为了把laravel升级到最新的版本,突然之间就出现了如下错误:
ErrorException thrown with message "Declaration of Illuminate\View\Engines\CompilerEngine::handleViewException() should be compatible with Illuminate\View\Eng
- 编程之美-NIM游戏分析-石头总数为奇数时如何保证先动手者必胜
bylijinnan
编程之美
import java.util.Arrays;
import java.util.Random;
public class Nim {
/**编程之美 NIM游戏分析
问题:
有N块石头和两个玩家A和B,玩家A先将石头随机分成若干堆,然后按照BABA...的顺序不断轮流取石头,
能将剩下的石头一次取光的玩家获胜,每次取石头时,每个玩家只能从若干堆石头中任选一堆,
- lunce创建索引及简单查询
chengxuyuancsdn
查询创建索引lunce
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Docume
- [IT与投资]坚持独立自主的研究核心技术
comsci
it
和别人合作开发某项产品....如果互相之间的技术水平不同,那么这种合作很难进行,一般都会成为强者控制弱者的方法和手段.....
所以弱者,在遇到技术难题的时候,最好不要一开始就去寻求强者的帮助,因为在我们这颗星球上,生物都有一种控制其
- flashback transaction闪回事务查询
daizj
oraclesql闪回事务
闪回事务查询有别于闪回查询的特点有以下3个:
(1)其正常工作不但需要利用撤销数据,还需要事先启用最小补充日志。
(2)返回的结果不是以前的“旧”数据,而是能够将当前数据修改为以前的样子的撤销SQL(Undo SQL)语句。
(3)集中地在名为flashback_transaction_query表上查询,而不是在各个表上通过“as of”或“vers
- Java I/O之FilenameFilter类列举出指定路径下某个扩展名的文件
游其是你
FilenameFilter
这是一个FilenameFilter类用法的例子,实现的列举出“c:\\folder“路径下所有以“.jpg”扩展名的文件。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
- C语言学习五函数,函数的前置声明以及如何在软件开发中合理的设计函数来解决实际问题
dcj3sjt126com
c
# include <stdio.h>
int f(void) //括号中的void表示该函数不能接受数据,int表示返回的类型为int类型
{
return 10; //向主调函数返回10
}
void g(void) //函数名前面的void表示该函数没有返回值
{
//return 10; //error 与第8行行首的void相矛盾
}
in
- 今天在测试环境使用yum安装,遇到一个问题: Error: Cannot retrieve metalink for repository: epel. Pl
dcj3sjt126com
centos
今天在测试环境使用yum安装,遇到一个问题:
Error: Cannot retrieve metalink for repository: epel. Please verify its path and try again
处理很简单,修改文件“/etc/yum.repos.d/epel.repo”, 将baseurl的注释取消, mirrorlist注释掉。即可。
&n
- 单例模式
shuizhaosi888
单例模式
单例模式 懒汉式
public class RunMain {
/**
* 私有构造
*/
private RunMain() {
}
/**
* 内部类,用于占位,只有
*/
private static class SingletonRunMain {
priv
- Spring Security(09)——Filter
234390216
Spring Security
Filter
目录
1.1 Filter顺序
1.2 添加Filter到FilterChain
1.3 DelegatingFilterProxy
1.4 FilterChainProxy
1.5
- 公司项目NODEJS实践0.1
逐行分析JS源代码
mongodbnginxubuntunodejs
一、前言
前端如何独立用nodeJs实现一个简单的注册、登录功能,是不是只用nodejs+sql就可以了?其实是可以实现,但离实际应用还有距离,那要怎么做才是实际可用的。
网上有很多nod
- java.lang.Math
liuhaibo_ljf
javaMathlang
System.out.println(Math.PI);
System.out.println(Math.abs(1.2));
System.out.println(Math.abs(1.2));
System.out.println(Math.abs(1));
System.out.println(Math.abs(111111111));
System.out.println(Mat
- linux下时间同步
nonobaba
ntp
今天在linux下做hbase集群的时候,发现hmaster启动成功了,但是用hbase命令进入shell的时候报了一个错误 PleaseHoldException: Master is initializing,查看了日志,大致意思是说master和slave时间不同步,没办法,只好找一种手动同步一下,后来发现一共部署了10来台机器,手动同步偏差又比较大,所以还是从网上找现成的解决方
- ZooKeeper3.4.6的集群部署
roadrunners
zookeeper集群部署
ZooKeeper是Apache的一个开源项目,在分布式服务中应用比较广泛。它主要用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步、集群管理、配置文件管理、同步锁、队列等。这里主要讲集群中ZooKeeper的部署。
1、准备工作
我们准备3台机器做ZooKeeper集群,分别在3台机器上创建ZooKeeper需要的目录。
数据存储目录
- Java高效读取大文件
tomcat_oracle
java
读取文件行的标准方式是在内存中读取,Guava 和Apache Commons IO都提供了如下所示快速读取文件行的方法: Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path)); 这种方法带来的问题是文件的所有行都被存放在内存中,当文件足够大时很快就会导致
- 微信支付api返回的xml转换为Map的方法
xu3508620
xmlmap微信api
举例如下:
<xml>
<return_code><![CDATA[SUCCESS]]></return_code>
<return_msg><![CDATA[OK]]></return_msg>
<appid><
 2017-10-27.png
2017-10-27.png