统计学中均值、标准差、方差这些概念和例子都很常见。这些数字特征不是本文要重点探讨的可以看看这篇对于概率论数字特征的理解
- 均值描述的是样本集合中平衡点,因为信息是有限的。
- 标准差描述的是样本集合中各个样本点到均值之间距离的平均值
eg:[0, 8, 12, 20]和[8, 9, 11, 12],两个集合的均值都是10,但显然两个集合的差别是很大的,计算两者的标准差,前者是8.3后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是n,是因为这样能使我们以较小的样本集更好地逼近总体的标准差,即统计上所谓的“无偏估计”。(这个例子来源于网络看到的,挺好的就引用过来,凑出均值相同)
而方差则仅仅是标准差的平方。方差是协方差的一种特殊情况,即当两个变量是相同的情况 。
引出协方差
前面的标准差,方差一般用来描述一维的,现实中我们遇到的大多是多维的,这时候虽然可以每一维独立计算出方差啥的,但信息单一,这就引出协方差。
简单地说:协方差就是这样一种用来度量两个随机变量关系的统计量
通俗的说:两个变量之间是否同时偏离均值。
也可以写成和期望有关:
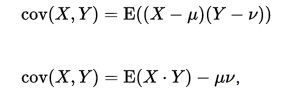
有了上面的定义我们就看看怎么来理解
p(x,y)是x,y的二维概率分布函数,颜色深浅应该表示进概率密度的大小,p(x,y)整个区域二重积分得到1,这个就是下面圆的背景知识了。下面是协方差的三种不同意义情况
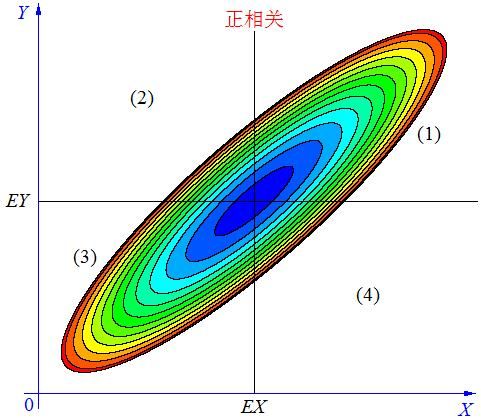
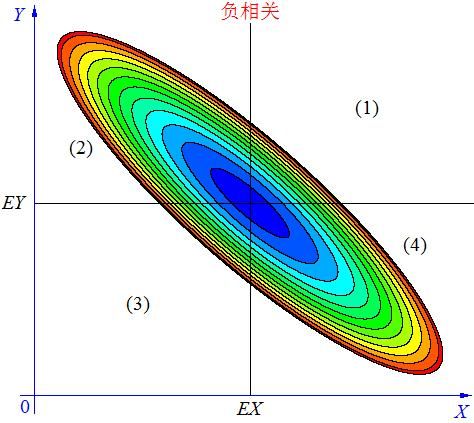
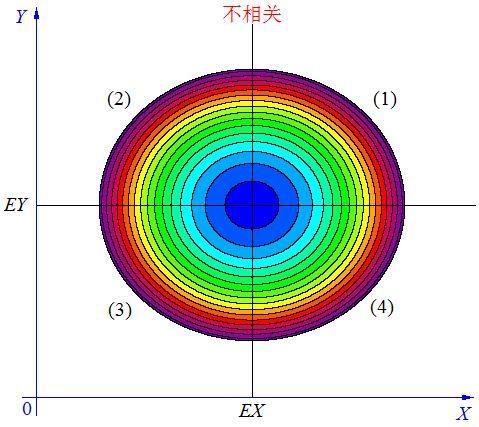
当X, Y 的联合分布像上图那样时,我们可以看出:既不是X 越大Y 也越大,也不是 X 越大 Y 反而越小,这种情况我们称为“不相关”。
怎样将这3种相关情况,用一个简单的数字表达出来呢?
- 在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
- 在图中的区域(2)中,有 X
0 ,所以(X-EX)(Y-EY)<0; - 在图中的区域(3)中,有 X
0; - 在图中的区域(4)中,有 X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
当X 与Y ****正相关****时,它们的分布大部分在区域(****1****)和(****3****)中,小部分在区域(****2****)和(****4****)中,所以平均来说,有E(X-EX)(Y-EY)>0 。
当 X与 Y负相关时,它们的分布大部分在区域(2)和(4)中,小部分在区域(1)和(3)中,所以平均来说,有(X-EX)(Y-EY)<0 。
当 X与 Y不相关时,它们在区域(1)和(3)中的分布,与在区域(2)和(4)中的分布几乎一样多,所以平均来说,有(X-EX)(Y-EY)=0** 。
所以,我们可以定义一个表示X, Y 相互关系的数字特征,也就是协方差
cov(X, Y) = E(X-EX)(Y-EY)。
- 当 cov(X, Y)>0时,表明** X与Y **正相关;
- **当 cov(X, Y)<0时,表明X与Y负相关;
- **当 ****cov(X, Y)=0****时,表明X与Y不相关。
相关系数
如果X 与Y 是统计独立的,那么二者之间的协方差就是0,这是因为
但是反过来并不成立,即如果X 与Y 的协方差为0,二者并不一定是统计独立的。
取决于协方差的相关性η

相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差,它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
协方差表示线性相关的方向,相关系数不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。
协方差矩阵
协方差解决的也只是二维的问题,那么继续维数上升呢,就要计算多个协方差,这个道理很好懂。
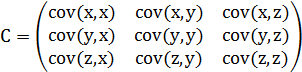
协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方,对于机器学习领域的PCA来说,如果遇到的矩阵不是方阵,需要计算他的协方差矩阵来进行下一步计算,因为协方差矩阵一定是方阵,而特征值分解针对的必须是方阵,SVD针对的可以是非方阵情况。
协方差矩阵在主成分分析中主成分分析有关键作用。主成分分析就是把协方差矩阵做一个奇异值分解,求出最大的奇异值的特征方向。
协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的,这点要记牢了。
剩下可以参考下:
[转]浅谈协方差矩阵
[线性代数] 如何求协方差矩阵
详解协方差与协方差矩阵
另外,我不是数学专业对这方面没有过多研究,现阶段只是简单明白,在学习过程中会把好的精彩干练的整合起来,方便复习,就酱紫了,咱们可以发邮件讨论,博客下面就是地址了。