Redis Cluster(集群)是官方提供的集群功能。Redis 在 3.0 版本中提供了 Redis Cluster 来满足分布式的需求。
为什么需要集群?
并发量,据 Redis 官方测试,有 50 个并发程序来执行 10 万次请求,Redis 读的速度达到了 11 万次/秒,写的速度达到了 8.1 万次/秒。那如果业务需要 100 万次/秒呢?
数据量,一台生产机器内存一般在 16G~256G,如果业务需要 500G 数据呢?
这些问题引出了 Redis Cluster。
1.数据分布
分布式数据库 - 数据分区:
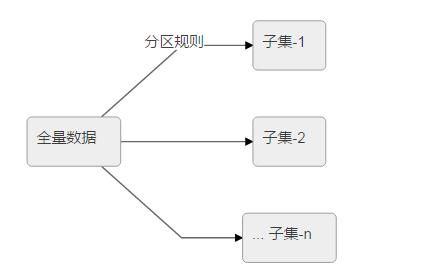
常用的两种分区方式是顺序分区(按顺序进行分区)和哈希分区(key 取哈希值进行分区)。

哈希分区主要有三种:
1.节点取余分区
客户端分片,分区位置 = hash(key) % nodes,nodes 指节点数,有一个问题就是如果扩容,约 80% 的数据会做漂移,如果是翻倍扩容,约 50% 的数据会做漂移,大量的漂移会影响系统性能,建议翻倍扩容。
2.一致性哈希分区
客户端分片,分区位置 = hash(key) + 顺时针(优化取余),是对节点取余分区的一个优化,为数据做一个 token 环,token = 0 ~ 2 的 32 次方,然后为每一个节点分配一个 token 范围,然后根据 hash(key) 值顺时针去找节点名。
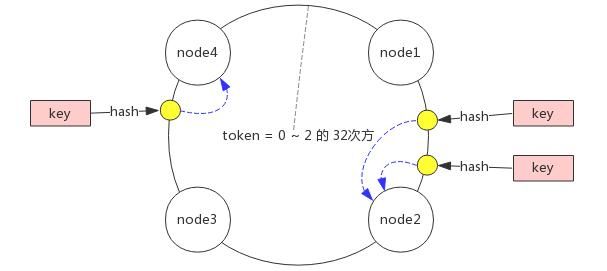
如果在 node1 和 node2 之间加一个 node5,node1 到 node5 之间的哈希就会落在 node5 上了,数据仍然会存在漂移,但是有一个好处是,添加节点后,不会影响 node1、node3、node4 的数据,影响范围会小很多。随着节点数量的增加,漂移影响范围也会越来越小。适合节点比较多的情况。
3.虚拟槽分区
预设虚拟槽:每个槽映射一个数据子集,一般比节点数大。
Redis Cluster 使用的分区方式,服务端(Redis)分片。Redis Cluster 中有一个16384(0~16383)长度的虚拟槽。
分区位置 = hash(key) % 16383。
虚拟槽分配:
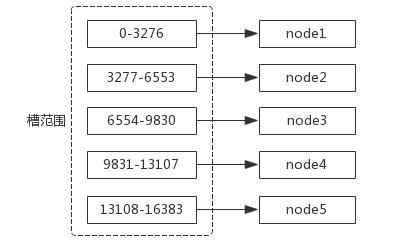
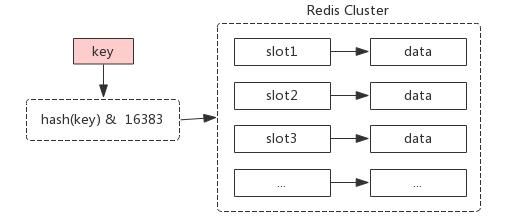
像节点取余分区和一致性哈希分区都有一个问题,就是添加节点之后,数据会进行漂移,存在丢数据的可能性,只能作为缓存场景来使用。而虚拟槽分区是不存在这样的问题的,因为每个槽负责的范围是固定的,加了新节点,也不会把其他节点的槽抢过去。
2.基本架构
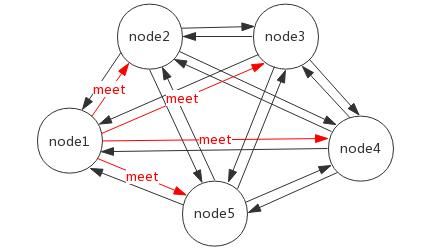
节点:Redis Cluster 中会有多个节点,节点之间是相互通信的,且每个节点都负责读写。
meet 操作(gossip 协议):节点之间相互通信的基础。假如现在有 5 个节点,node1 节点对 node2、node3、node4、node5 节点分别发送了一个 meet 操作,node2 等节点会各自返回一个 pong 命令(表示 Redis 服务运行正常),其他节点可以自动找到,最终所有节点都可以相互通信。
分配槽:需要给节点分配虚拟槽。
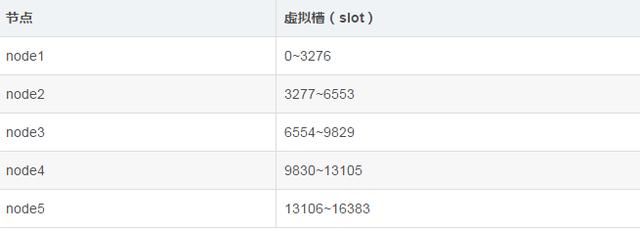
对于客户端来说,只需要计算 slot = hash(key) %16383。
复制:为了保证高可用,每一个节点都有一个 slave 节点。
3.搭建集群
配置开启 Redis,原生命令安装和官方工具安装这一步是一样的。这里 Redis 五个节点用五个端口进行区分,分别是 7000、7001、7002、7003、7004。
Redis 节点 redis/config/redis-7000.conf 配置(redis.conf 模板文件在 redis/redis.conf,这里只给出一个节点配置,其余节点只能端口号不同):
# 关闭保护模式
protected-mode no
# 配置启动端口
port 7000
# 配置后台启动
daemonize yes
# 修改pidfile指向路径 redis-${port}.pid
pidfile /var/run/redis-7000.pid
# 日志记录方式 redis-${port}.log
logfile "redis-7000.log"
# 配置dump数据存放目录
dir "/opt/soft/redis/data/"
# 配置dump数据文件名 redis-${port}.rdb
dbfilename dump-7000.rdb
# 开启集群模式
cluster-enabled yes
# cluster节点超时时间,毫秒
cluster-node-timeout 15000
# cluster配置文件
cluster-config-file "nodes-7000.conf"
# 是否需要集群内所有节点都能提供服务才认为集群是正确的,默认yes
cluster-require-full-coverage no
启动命令:
# redis-server redis-7000.conf
继续操作,分别启动剩余 7001、7002、7003、7004 端口的节点。此时各个节点没有进行任何通信,各自都是孤立的。
1.原生命令安装(理解架构)
首先进行 meet 操作(gossip 协议):
# redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 -p 7001 //在 7000 上执行命令,7000 端口的 redis 节点 meet 7001端口的 redis 节点
# redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 -p 7002
# redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 -p 7003
# redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 -p 7004
然后分配槽:
# redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0...3276} //在 7000 上执行命令
# redis-cli -h 127.0.0.1 -p 7001 cluster addslots {3277...6553}
# redis-cli -h 127.0.0.1 -p 7002 cluster addslots {6554...9829}
# redis-cli -h 127.0.0.1 -p 7003 cluster addslots {9830...13105}
# redis-cli -h 127.0.0.1 -p 7004 cluster addslots {13106...16383}
这样所有槽分配之后,集群就算基本建立完成了。
最后需要设置主从(只有有了主从关系后,才可以实现故障自动转移):
# redis-cli -h 127.0.0.1 -p 8000 cluster replicate ${node-id-7000} //在 8000 上执行命令
node-id 是指集群的一个节点 id,在集群启动的时候就会进行分配,需要注意的是,这里的 node-id 非单机节点的 runid,runid 重启会重置,node-id 重启不会重置。
2.官方工具安装(生产推荐)
Redis Cluster 官方提供了 Ruby 的安装脚本,相比于原生命令安装要容易很多。
Linux 上安装 Ruby 环境:
# wget -P /usr/local http://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.3.tar.gz
# cd /usr/local
# tar -zxvf ruby-2.6.3.tar.gz //解压缩
# cd ruby-2.6.3
# ./configure -prefix=/usr/local/ruby //配置
# make
# make install //安装
# cd /usr/local/ruby
# cp bin/ruby /usr/local/bin
# cp bin/gem /usr/local/bin
安装 Ruby Redis 客户端:
# wget -P /usr/local http://rubygems.org/downloads/redis-4.1.2.gem
# cd /usr/local
# gem install -l redis-4.1.2.gem //安装rubygem redis
# gem list --check redis gem
# cp /usr/local/redis/src/redis-trib.rb /usr/local/bin //安装redis-trib.rb
redis-trib 安装 Redis Cluster:
一键开启:
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.
这个命令表示创建集群,–replicas 1 表示每个主节点配备一个从节点,前五个 7000 到 7004 的端口表示主节点,后五个 8000 到 8004 的端口表示从节点,7000 对应 8000,7001 对应 8001,以此类推。
相比原生命令安装,官方工具安装更高效、准确,生成环境可使用。
4.集群伸缩
1.伸缩原理
一个 node1、node2、node3 组成的集群,加入 node4 的过程,其实就是槽和数据在节点之间的移动。

2.扩容集群
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 组成的集群,加入 127.0.0.1:7003。
1.原生命令安装(理解架构)
1、准备新节点
需要新节点是集群模式(cluster-enabled yes),配置需要和其他节点统一,然后启动改节点。
2、加入集群
通过 meet 操作(gossip 协议)来完成的:
# redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 -p 7003 //在 7000 上执行命令,7000 端口的 redis 节点 meet 7003端口的 redis 节点
# redis-cli -h 127.0.0.1 -p 7000 cluster nodes //加入集群,观察集群配置
3、迁移槽和数据
首先进行槽迁移计划,平均槽数据,计算每个节点应该迁移到新节点的槽的数量。
然后迁移数据,迁移数据的过程是比较复杂的:
1)对目标节点发送 cluster setslot {slot} importing {sourceNodeId} 命令,让目标节点准备导入槽数据;
2)对源节点发送 cluster setslot {slot} migrating {targetNodeId} 命令,让源节点准备迁出槽的数据;
3)源节点循环执行 cluster getkeysinslot {slot} {count} 命令,每次获取 count 个属于槽的键;
4)在源节点上执行 migrate {targetIp} {targetPort} key 0 {timeout} 命令把指定 key 迁移;
5)重复执行 3~4 直到槽下所有的键数据迁移到模板节点;
6)向集群内所有 master 节点发送 cluster setslot {slot} node {targetNodeId} 命令,通知槽分配给目标节点。
迁移数据的完整流程图:

4、添加从节点
2.官方工具安装(生产推荐)
扩容集群命令:./redis-trib.rb add-node new_host:new_port existing_host:existing_port --slave --master-id < arg>
# ./redis-trib.rb add-node 127.0.0.1:7003 127.0.0.1:7000
建议使用 redis-trib.rb,能够避免新节点已经加入了其他集群,造成故障。
建议使用 redis-trib.rb,能够避免新节点已经加入了其他集群,造成故障。
2.缩容集群
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 组成的集群,缩容 127.0.0.1:7003。
1.原生命令安装(理解架构)
1、下线迁移槽
将下线节点持有的槽均匀的迁移到其他节点,迁移命令跟扩容集群的命令相同,不再赘述。
2、忘记节点
# redis-cli -h 127.0.0.1 -p 7000 cluster forget 7003 //在7000节点上执行,让7000忘记7003节点
、关闭节点
2.官方工具安装(生产推荐)
1、集群缩容
集群缩容命令:
# ./redis-trib.rb reshard --from {7003 nodeid} --to {7000…7002 nodeid} --slots 1366 127.0.0.1:7003 //任一端口上执行,分别迁移槽位到之前的三个主节点
建议使用 redis-trib.rb,能够避免新节点已经加入了其他集群,造成故障。
2、下线节点
先下线从节点,再下线主节点。
# ./redis-trib.rb del-node 127.0.0.1:7000 {7003nodeid}
# ./redis-trib.rb del-node 127.0.0.1:7000 {8003nodeid}
下线节点包含了从集群中 remove 节点、从集群中 forget 节点、shutdown 节点。
3、忘记节点
# redis-cli -h 127.0.0.1 -p 7000 cluster forget {nodeId}
# redis-cli -p cluster slots //查看节点情况
5.客户端路由
1.moved重定向
moved 异常:
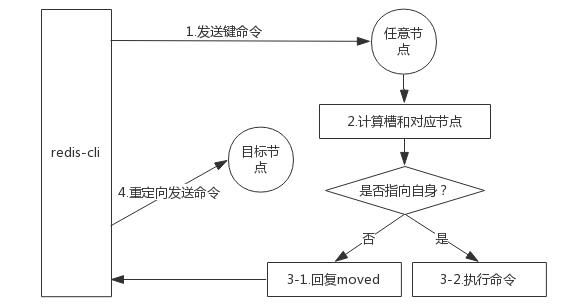
槽命中,直接返回:
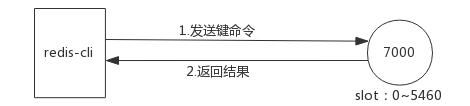
槽不命中,moved 异常:

2.ask重定向
在集群扩容缩容的时候,会对槽进行迁移,槽的迁移是遍历槽中的 key,然后逐步执行 migrate 命令把指定 key 迁移,这个操作本身是比较慢的,假如此时客户端记录了槽的信息是在源节点,此时去访问,发现 key 已经迁移到目标节点了,这个时候就引出了 ask 重定向。
ask 异常:
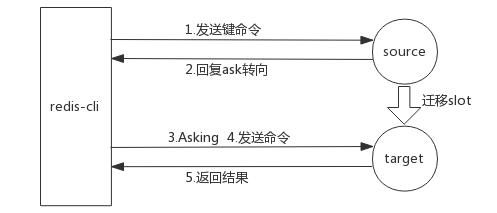
moved 重定向和 ask 重定向两者都是客户端重定向,不同是 moved 槽已经确定迁移,ask 槽还在迁移中 。
3.smart客户端
1、smart 客户端使用:例如 Java 客户端 JedisCluster。
2、smart 客户端原理
smart 客户端首要目标就是追求性能,不可以使用代理模式(影响性能),Redis 作者建议直连对应槽的节点,但是碰到 moved 异常和 ask 异常需要做兼容,基本过程是这样的:
从集群中选一个可运行节点,执行 cluster slots 命令初始化槽和节点映射;
将 cluster slots 的结果映射到本地,为每个节点创建 JedisPool;
准备执行命令。
执行命令的基本过程:
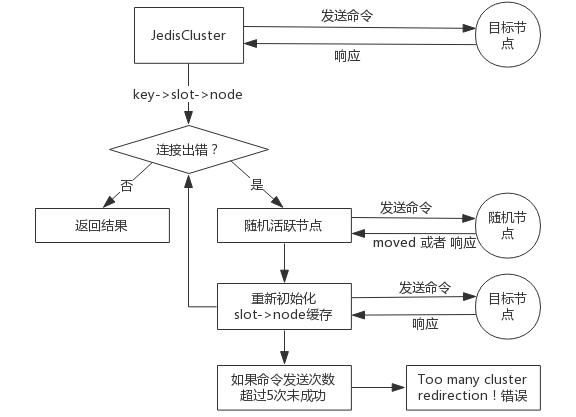
3、JedisCluster 执行源码分析
打开 JedisCluster 类,看下 set 方法的实现:
@Override
public String set(final String key, final String value) {
return new JedisClusterCommand(connectionHandler, maxAttempts) {
@Override
public String execute(Jedis connection) {
return connection.set(key, value);
}
}.run(key);
}
可以看到使用了一个匿名内部类然后进行封装,跟进去看下 JedisClusterCommand 的实现:
public abstract class JedisClusterCommand {
/**
* 在cluster初始化的时候,它会帮我们初始化所有的槽和节点的对应关系
*/
private final JedisClusterConnectionHandler connectionHandler;
/**
* 最大尝试次数
*/
private final int maxAttempts;
public JedisClusterCommand(JedisClusterConnectionHandler connectionHandler, int maxAttempts) {
this.connectionHandler = connectionHandler;
this.maxAttempts = maxAttempts;
}
public abstract T execute(Jedis connection);
public T run(String key) {
if (key == null) {
throw new JedisClusterException("No way to dispatch this command to Redis Cluster.");
}
return runWithRetries(JedisClusterCRC16.getSlot(key), this.maxAttempts, false, null);
}
private T runWithRetries(final int slot, int attempts, boolean tryRandomNode, JedisRedirectionException redirect) {
// 尝试初始化的次数,attempts默认传入5
if (attempts <= 0) {
throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?");
}
// jedis连接
Jedis connection = null;
try {
// 第一次执行的时候redirect是null
if (redirect != null) {
connection = this.connectionHandler.getConnectionFromNode(redirect.getTargetNode());
if (redirect instanceof JedisAskDataException) {
// Ask异常
// TODO: Pipeline asking with the original command to make it faster....
connection.asking();
}
} else {
// 是否尝试随机节点,第一次执行的时候tryRandomNode是false
if (tryRandomNode) {
connection = connectionHandler.getConnection();
} else {
// 通过JedisClusterCRC16.getSlot(key)算出key对应的槽,通过槽获取对应的连接
connection = connectionHandler.getConnectionFromSlot(slot);
}
}
// 执行命令
return execute(connection);
// 无节点可达,直接抛出异常
} catch (JedisNoReachableClusterNodeException jnrcne) {
throw jnrcne;
// 连接异常
} catch (JedisConnectionException jce) {
// 释放当前连接
releaseConnection(connection);
connection = null;
if (attempts <= 1) {
//We need this because if node is not reachable anymore - we need to finally initiate slots
//renewing, or we can stuck with cluster state without one node in opposite case.
//But now if maxAttempts = [1 or 2] we will do it too often.
//TODO make tracking of successful/unsuccessful operations for node - do renewing only
//if there were no successful responses from this node last few seconds
// 刷新本地slot缓存
this.connectionHandler.renewSlotCache();
}
return runWithRetries(slot, attempts - 1, tryRandomNode, redirect);
// 重定向异常
} catch (JedisRedirectionException jre) {
// if MOVED redirection occurred,
if (jre instanceof JedisMovedDataException) {
// it rebuilds cluster's slot cache recommended by Redis cluster specification
this.connectionHandler.renewSlotCache(connection);
}
// release current connection before recursion
releaseConnection(connection);
connection = null;
return runWithRetries(slot, attempts - 1, false, jre);
} finally {
// 释放当前连接
releaseConnection(connection);
}
}
}
执行命令就回到 JedisCluster 类,看下 execute 这个模板方法:
@Override
public String set(final String key, final String value) {
return new JedisClusterCommand(connectionHandler, maxAttempts) {
@Override
public String execute(Jedis connection) {
return connection.set(key, value);
}
}.run(key);
}
这样就完成了一次 Redis 命令的操作。
小编这里整理了更多相关的 学习资料和 学习视频,可免费领取。
加 VX:bmaaa01 通过验证备注:111(备注必填,方便通过)