利用node实现的小爬虫以及有关异步操作的一些思考
在搭建唯厘UED blog的时候一直想实现一个功能,就是类似于bing首页每天的壁纸都不一样,于是就考虑使用node做个小爬虫来实现这个功能并把它应用在管理后台的登陆页面上。下面主要来分享一下实现的过程和遇到的一些坑以及一些思考。
相关工具库
首先介绍一下实现这个功能所使用到的一些工具库。
- cheerio: Node.js 版的jQuery
- https:封装了一个HTPPS服务器和一个简易的HTTPS客户端
- iconv-lite:解决爬取网页出现乱码
这是一个简单的小爬虫,那么,要爬取所需要的数据,首先要分析页面的结构。这次爬取的是必应壁纸(https://bing.ioliu.cn/),可以看到页面的结构如下图
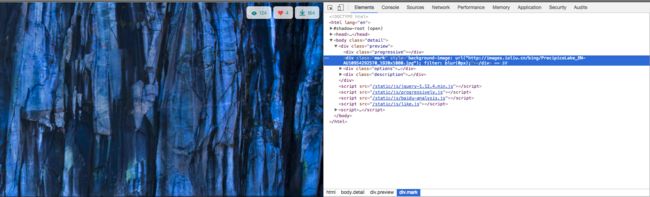
那么我们的目标很明确,只需要爬取img标签里面的src属性值就可以了。那么首先,当然是要爬取到页面的html结构,再进行筛选,代码如下
function get(url) {
https.get(url, (sres) => {
const chunks = []
sres.on('data', (chunk) => {
chunks.push(chunk)
})
sres.on('end', () => {
const html = iconv.decode(Buffer.concat(chunks), 'UTF-8')
const $ = cheerio.load(html, { decodeEntities: false })
})
})
}
ondata事件获取到的结果是一堆Buffer数据流,如下图,那么我们需要把这一堆数据转换成DOM,这个时候就需要使用cheerio,cheerio是为服务器特别定制的,快速、灵活、实施的jQuery核心实现。简单来说,就是它能够把这一堆堆buffer数据流转变为DOM,并且支持使用jquery的语法来进行DOM操作。

在上述ondata事件中补充以下代码,如果有数据,那么就爬取成功了。但是就这么容易成功了吗?文章短小一般都不是我的尿性,先剧透,下面代码执行完之后的结果是undefined。

console.log($('.mark').css('background-image'))
ok,我们分析一下原因,当进去这个图片页面的时候,可以发现其使用了懒加载的效果,那么就意味着,图片链接是由js动态添加上去的,再去看一下js代码(如下),果不其然。这里就遇到了第一个坑,大部分简单的爬虫并没有办法获取得到动态生成的内容,要实现获取动态内容的效果,需要使用PhantomJS,有兴趣的可以深入了解一下,由于时间关系,以及社区上反映的的PhantomJS的性能问题,这里就不使用PhantomJS。
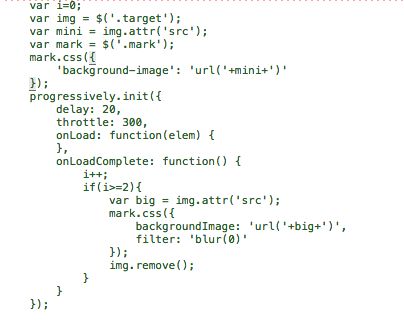
既然直接爬取的途径断了,那么我们能不能试一下间接爬取,实行曲线救国?先分析分析一下一张完整大图的路径和缩略图的路径有什么不一样的地方
大图:http://images.ioliu.cn/bing/Shanghai_ZH-CN10665657954_1920x1080.jpg
缩略图: https://bing.ioliu.cn/photo/Shanghai_ZH-CN10665657954?force=home_1
可以看到,这两者不同的只是照片的名字之外的地方,那么我们需要截取照片的名字,再把域名和分辨率进行拼接,这样就能获取得到一张大图的真实路径。

完整代码
const basicUrl = 'http://images.ioliu.cn/bing'
let picLinkArray = []
/*
*params url: 需要爬取的链接
*/
function get(url) {
https.get(url, (sres) => {
const chunks = []
sres.on('data', (chunk) => {
console.log(chunk)
chunks.push(chunk)
})
sres.on('end', () => {
const html = iconv.decode(Buffer.concat(chunks), 'UTF-8')
const $ = cheerio.load(html, { decodeEntities: false })
const tagArray = $('.item a.mark')
const oriLinkArray = []
for (let i = 0; i < tagArray.length; i += 1) {
oriLinkArray.push(tagArray[i].attribs.href)
}
for (let i = 0; i < oriLinkArray.length; i += 1) {
const link = oriLinkArray[i]
const index = oriLinkArray[i].indexOf('force')
const picLink = oriLinkArray[i].slice(0, index - 1).replace('/photo', '').concat('_1920x1080.jpg')
picLinkArray.push(basicUrl + picLink)
}
})
})
}
这样,我们就实现了获取大图的函数,接下来只需要循环执行,便可以获取得到前10页的大图
for (let i = 1; i < 10; i += 1) {
get('https://bing.ioliu.cn?p=' + i)
}
到这里,爬虫基本就完成了。很简单的一个功能,顺带提一下另一个坑,之前爬虫函数是写在管理后台一个单独的js文件里并在login组件require进来使用,但这样一来存在一个异步的问题,二来因为同源策略存在跨域的问题,因此换了一个思路,写在了node层里面,这样就避免了跨域的问题,但是异步的问题还是有一些麻烦的,下面以实现登录这个功能为例来说明蛋疼的地方,顺便集思广益,看看有木有什么更优雅的办法来解决这个问题。
首先简单说明一下当前整个项目所采用的结构,当前采用的是操作方法和路由操作分离,对数据库的操作方法都写在controller文件夹下的js文件里面,同时controller会暴露一个接口给路由层。
在美迪科项目里面,这种方法是可行的,因为lowdb的链式操作是同步的,这样能够顺利保证数据库的操作结果能够顺利返回到路由层,然后由路由层来进行下一步操作,如下图。但在mongoose + mongodb的组合里,mongoose有关数据库的结果操作都放在了一个回调函数里,这样要把数据库的操作结果传递到route层就有点蛋疼。经过摸索,目前的解决方案有两种。
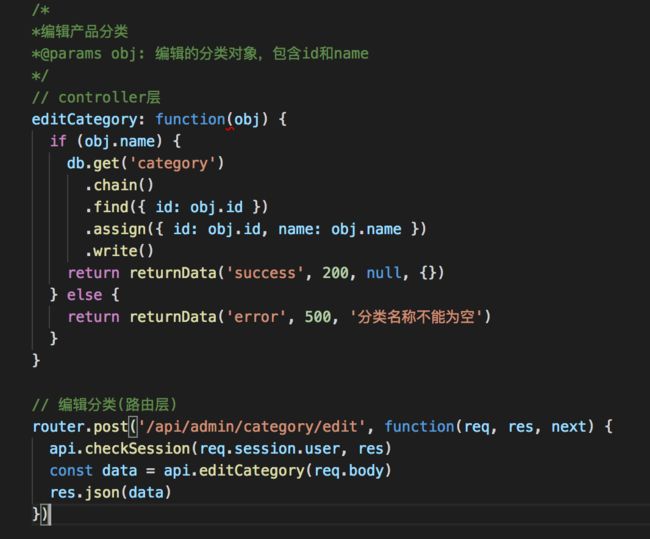
1.返回一个promise对象给路由层
controller里面的login方法
login(user) {
var promise = userdb.find({ "username": user.username, "password": user.password }).exec()
return promise
}
路由里面的操作
router.post('/api/admin/login', (req, res, next) => {
const promise = frontEndAdmin.login(req.body)
promise.then(
function(result) {
if (result.length === 0) {
res.json(returnData('error', 503, '唯厘这里没有这个人哦', {}))
}
}
)
res.json(data)
})
}
这种方法的缺点也很明显,就是对数据库的操作和路由的操作紧密结合,并没有很好的解耦,显然不是我们需要的,同样的也尝试过使用node的eventEmitter,但也有这种问题。我们需要的仅是数据库的操作结果,并且根据这个结果来返回不同的接口信息。
2.把res对象传递到controller层
controller里面的login方法
login(user, res) {
userdb.find(
{ "username": user.username, "password": user.password },
function (err, person) {
console.log(person)
if (err) {
res.json(returnData('error', 500, '出错啦,去怼写接口的人', {}))
}
if (person.length === 0) {
res.json(returnData('error', 503, '唯厘这里没有这个人哦', {}))
} else {
res.json(returnData(null, null, null, {}))
}
}
)
路由里面的方法
router.post('/api/admin/login', (req, res, next) => {
frontEndAdmin.login(req.body, res)
}
这样咋一看似乎简洁明了了许多,但是路由的信息操作混进了controller层,也并没有完全的解耦,目前采用的是第二种方法。
经过新一轮的摸索,截止2017年09月27日18:54:59,上述问题作废,终于探索出一个完美的解决方案,之前一直是想尝试使用async + await这个方案的,但无奈本机node版本达不到要求,也因为同时进行的项目比较多,担心升级后会有什么副作用,但最后还是一狠心把node版本给升级了,这样就可以使用这个组合了。贴代码贴代码
controller里面的login方法
login(user) {
var promise = userdb.find({ "username": user.username, "password": user.password }).exec().then(
(result) => {
if (result.length === 0) {
return returnData('error', 503, '唯厘这里没有这个人哦', {})
}
}
)
return promise
)
路由里面的方法
router.post('/api/admin/login', async(req, res, next) => {
const data = await frontEndAdmin.login(req.body)
res.json(data)
})
