创建于:20161208
本章小目标
- 在上一章的基础上进行操作
- 安装spark2.0测试环境
- 构建至少3个节点的spark集群
- 基于yarn模式构建集群
软件版本
- java: jdk-8u91-linux-x64.tar.gz 官网下载可能会比较慢
- scala: scala-2.11.8.tgz官网下载,spark2.0要求scala2.11.×
- hadoop: hadoop-2.7.2.tar.gz 镜像下载地址较快
- spark: spark-2.0.2-bin-hadoop2.7.tgz 官网下载
- IDE: ideaIU-2016.2.4.tar.gz 中文网站下载稍快一些
参考链接
- spark官方文档,选择对应版本2.0.2
- hadoop官方文档,选择对应版本2.7.2
- apache旗下众多软件镜像下载列表 速度快
- http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/
- http://blog.csdn.net/u010638969/article/details/51283216
- http://blog.chinaunix.net/uid-28311809-id-4341735.html
1. 安装JDK
1.1 apt-get 自动安装法(需要慎重考虑网速)
$ which java
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
#选择同意条款,开始安装,速度很慢,提示要2小时,果断杀掉安装进程
...
$ sudo update-java-alternatives -s java-7-oracle
$ sudo update-java-alternatives -s java-8-oracle #可以切换不同的系统默认java版本
1.2 下载gz包安装法(本文推荐)
$ sudo mkdir /usr/lib/jvm
$ sudo tar -zxvf jdk-8u91-linux-x64.tar.gz -C /usr/lib/jvm
$ sudo vim /etc/profile #增加如下内容
#add at 20161210
#set oracle jdk environment
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=${JAVA_HOME}/bin:$PATH
set -o vi
注销登录,测试生效
$ java -version
1.3 本节参考:
http://www.cnblogs.com/a2211009/p/4265225.html
2. 安装scala
2.1 apt安装,前提是前面的JDK也是apt安装,否则会报错。apt的scala也是2.11.×
$ sudo apt show scala
$ sudo apt install scala=2.11.6-6
2.2 下载gz安装(本文推荐)
$ sudo mkdir /usr/lib/scala
$ sudo tar -xvzf scala-2.11.8.tgz -C /usr/lib/scala/
$ sudo su
$ vi /etc/profile #增加如下设置
#set scala env
export SCALA_HOME=/usr/lib/scala/scala-2.11.8
export PATH=${SCALA_HOME}/bin:$PATH
2.3 本节参考
菜鸟-scala
3. 安装hadoop
3.1 下载gz包安装
$ mkdir -p soft/hadoop #个性化的软件,我不打算放在/usr/lib; 找个新家~/soft/
$ tar -xzvf hadoop-2.7.2.tar.gz -C ~/soft/hadoop/
#对应地,环境变量就在当前用户下生效吧
$ vi ~/.bashrc
# install hadoop
export HADOOP_HOME=/home/bit/soft/hadoop/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=/home/bit/soft/hadoop/hadoop-2.7.2
export YARN_CONF_DIR=$YARN_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
$ . ~/.bashrc
$ hadoop version
3.2 配置hadoop
配置文件目录
$ pwd
/home/bit/soft/hadoop/hadoop-2.7.2/etc/hadoop
3.2.1 slaves
$ cat slaves
U1604N2
U1604N3
3.2.2 core-site.xml
$ vim core-site.xml
fs.defaultFS
hdfs://U1604N1:9000/
hadoop.tmp.dir
/home/bit/soft/hadoop/hadoop-2.7.2/tmp
3.2.3 hdfs-site.xml
$ vim hdfs-site.xml
dfs.namenode.secondary.http-address
U1604N1:9001
dfs.namenode.name.dir
/home/bit/soft/hadoop/hadoop-2.7.2/dfs/name
dfs.datanode.data.dir
/home/bit/soft/hadoop/hadoop-2.7.2/dfs/data
dfs.replication
3
3.2.4 mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
mapreduce.framework.name
yarn
3.2.5 yarn-site.xml
$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
U1604N1:8032
yarn.resourcemanager.scheduler.address
U1604N1:8030
yarn.resourcemanager.resource-tracker.address
U1604N1:8035
yarn.resourcemanager.admin.address
U1604N1:8033
yarn.resourcemanager.webapp.address
U1604N1:8088
3.2.6 hadoop-env.sh
一开始在/etc/profile已经设置了JAVA_HOME,但在这里还需要再设置一下,否则会报错。
$ vim hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91 #add
3.2.7 yarn-env.sh
$ vim yarn-env.sh
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91
4. 安装Spark
4.1 下载gz包安装
$ mkdir ~/soft/spark
$ tar -xzvf spark-2.0.2-bin-hadoop2.7.tgz -C ~/soft/spark/
4.2 配置spark
配置路径
$ pwd
/home/bit/soft/spark/spark-2.0.2-bin-hadoop2.7/conf
4.2.1 spark-env.sh
$ cp spark-env.sh.template spark-env.sh
$ vi spark-env.sh #JAVA_HOME等需要再配置一下,暂时不知道环境变量为何不生效
export SCALA_HOME=/usr/lib/scala/scala-2.11.8
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91
export HADOOP_HOME=/home/bit/soft/hadoop/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=U1604N1
SPARK_LOCAL_DIRS=/home/bit/soft/spark/spark-2.0.2-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
4.2.2 slaves
U1604N2
U1604N3
5. 构建集群
5.1 虚拟机拷贝
前面都是在U1604N1上进行的操作,下面将对U1604N1进行vmware虚拟机镜像复制,并开启U1604N2, U1604N3.
- 从前面的配置可以猜到,我用U1604N1做主控,2,3做为工作节点
- U1604N2,可以把快照全删掉,缩小体积
- U1604N2,可以调整为2G内存,单核CPU,节省资源
- 虚拟机复制开启的时候选择“我已复制该虚拟机”
- 打开U1604N2,修改/etc/hosts; /etc/hostname; 并设置静态IP。
操作办法请参考 第二章 的内容 - U1604N2复制到U1604N3,再来一遍。
效果如图:

image.png
后续的操作主要针对集群的3个节点,同步进行。
5.2 SSH免密码互访
# 三个节点都执行
$ sudo apt-get install openssh-server
$ ssh-keygen -t rsa #生成公私秘钥
$ ssh-copy-id -i ~/.ssh/id_rsa.pub bit@U1604N1 #公钥集中到1
#还可以用下面的命令实现同样的效果:
ssh bit@U1604N1 'cat >> ~/.ssh/authorized_keys' < .ssh/id_rsa.pub
#1 节点执行公钥分发
# chmod 600 ~/.ssh/authorized_keys 检查权限若不是600则改之
$ scp ./authorized_keys bit@U1604N2:~/.ssh
$ scp ./authorized_keys bit@U1604N3:~/.ssh
$ ssh bit@U1604N2 hostname #测试效果,实现无密码访问
$ ssh bit@U1604N3 hostname
5.3 启动集群
5.3.1 启动hadoop
#在节点U1604N1执行
$ cd /home/bit/soft/hadoop/hadoop-2.7.2
$ bin/hadoop namenode -format
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
$ jps
9249 SecondaryNameNode
9041 NameNode
10071 Jps
9992 ResourceManager
#在节点U1604N2执行
$ jps
10036 Jps
9575 DataNode
9932 NodeManager
#在节点U1604N3执行
$ jps
10699 Jps
10589 NodeManager
10207 DataNode
浏览器访问:http://u1604n1:8088/cluster 可以看到hadoop的管理界面
5.3.2 启动spark
#在节点U1604N1执行
$ cd /home/bit/soft/spark/spark-2.0.2-bin-hadoop2.7/sbin
$ ./start-all.sh
$ jps
9249 SecondaryNameNode
9041 NameNode
10758 Master
10920 Jps
9992 ResourceManager
同理在2,3节点上执行jps,可以看到对应的worker进程
$ jps
9575 DataNode
10361 Worker #在这里
9932 NodeManager
10412 Jps
spark启动后多出来master和worker进程。
浏览器访问:http://u1604n1:8080/ 可以看到spark管理界面
5.3.3 可能遇到的报错:
- 情况1:如果因为hdfs-site.xml 的配置路径值前面带有file而起不来,去掉即可
- 情况2:下面这种报错信息,是因为主机名带有下划线“_”导致的,很不幸被我遇到了,经过一番折腾总算解决。之前的教程也已经重新更新hostname,如果是一路跟着教程做的话应该不会掉进这个坑。
Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured
- 情况3: 仔细检查一下配置文件的路径,目录等是否准确。
类似于:export SCALA_HOME=$SCALA_HOME; 引用环境变量赋值可能是无效的。
6. 集群测试
用圆周率计算的例子测试运行
6.1 本地模式
$ cd ~/soft/spark/spark-2.0.2-bin-hadoop2.7
$ ./bin/run-example SparkPi 10 --master local[2]
6.2 Standalone模式
$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
examples/jars/spark-examples_2.11-2.0.2.jar \
100
可以在spark的管理台查看任务运行情况:
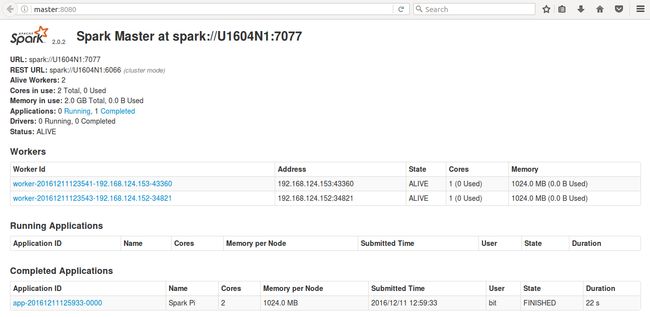
image.png
6.3 yarn模式
$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
examples/jars/spark-examples_2.11-2.0.2.jar \
10
可以在hadoop的管理界面查看任务运行情况
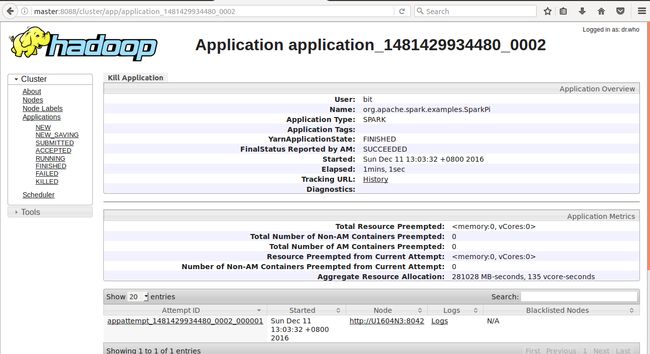
image.png
6.4 使用hdfs文件系统
$ hdfs dfs -mkdir -p /user/bit #当前用户bit的主目录需要手工创建
$ hdfs dfs -put ./README.md /user/bit #上传一个文件到创建的目录
$ hdfs dfs -ls
Found 2 items
drwxr-xr-x - bit supergroup 0 2016-12-11 13:04 .sparkStaging
-rw-r--r-- 3 bit supergroup 3828 2016-12-11 13:22 README.md
也可以登录管理台:http://u1604n1:50070/explorer.html#/
查看hdsf文件系统如下
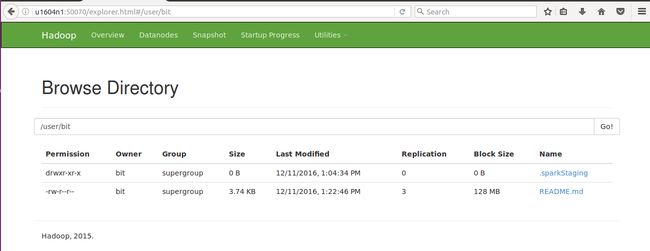
image.png
目标达成,收工!
PS:操作过程中如果遇到问题,欢迎反馈