下载 tesseract_ocr
使用composer下载,tesseract_ocr
$ composer require thiagoalessio/tesseract_ocr
ocr 测试
require_once './vendor/autoload.php';
use thiagoalessio\TesseractOCR\TesseractOCR;
echo (new TesseractOCR('./1.jpg'))
->lang('eng')
->run();
训练样本数据
安装 Tesseract
笔者这里是直接自动安装,没选择编译安装
$ sudo apt install tesseract-ocr
下载图片
function getPicture($uri)
{
for($i=0;$i<100;$i++) {
$img = file_get_contents($uri);
$filename = './test/'.$i.'.gif';
file_put_contents($filename,$img);
}
}
下载之后有点小问题,因为笔者电脑少了一个gif库,后面处理的时候总是有点问题。所以我用软件将 gif 转成了 png 格式.
安装 jTessBoxEditor
下载地址 笔者下载的是 jTessBoxEditor-2.0-Beta.zip
解压
$ unzip jTessBoxEditor-2.0-Beta.zip
- 运行
$ java -Xms128m -Xmx1024m -jar jTessBoxEditor.jar
jTessBoxEditor
图片转换成 tiff 格式
因为jTessBoxEditor只能处理.tiff后缀的文件,因此我们需要将验证码图片转化为.tiff后缀,这里我们使用ImageMagick的convert工具进行转化,首先安装ImageMagick:
$ sudo apt-get install imagemagick
shell 脚本批量转换当前目录下的图片
创建 tran.sh 文件
$ vim tran.sh
tran.sh 文件内容
#~/bin/sh
for file in `ls *.jpg`
do
name=${file%.*}
convert $file "../tiff/"$name".tiff"
done
图片转换
$ ./tran.sh
将 .tiff 文件合并成 .tif 文件
打开 jTessBoxEditor ,点击界面上的Tools/Merge TIFF,将之前生成的 .tiff 文件合并成一个 .tif文件
官方定义 tif 文件的命名格式为:[lang].[fontname].exp[num].tif
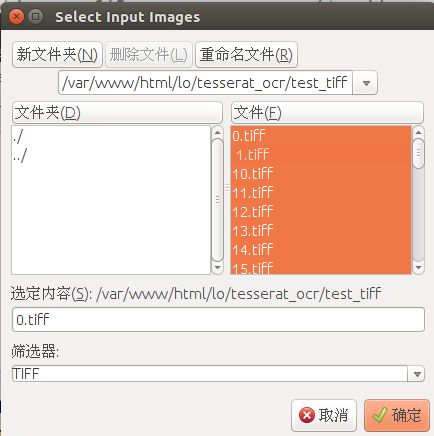
marge
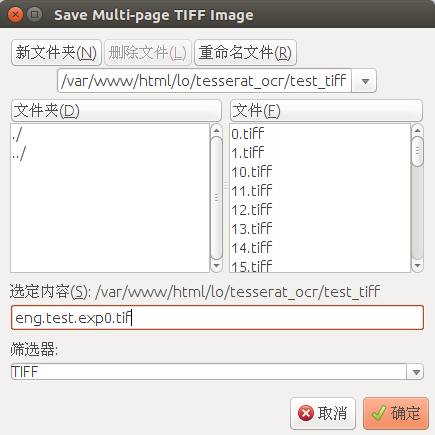
rename
生成 .box 文件
$ tesseract eng.test.exp0.tif eng.test.exp0 -l eng -psm 7 batch.nochop makebox
使用jTessBoxEditor校正字符
打开刚才生成的eng.test.exp0.tif 文件,在左侧的Char列输入正确的值,调整x,y,w,h的值。可选择工具栏上的merge 和 split 对结果进行合并和拆分。点击下方中间的翻页查看下一张验证码。
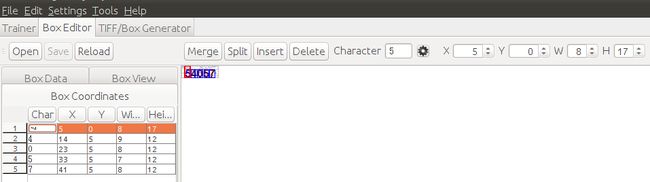
correcting
自制语言库
定义字体特征文件
$ echo test 0 0 0 0 0 > font_properties
语法: fontname italic bold fixed serif fraktur
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
生成字符特征文件
$ tesseract eng.test.exp0.tif eng.test.exp0 -l eng -psm 7 nobatch box.train
产生字符集
unicharset_extractor eng.test.exp0.box
生成shapetable
$ shapeclustering -F font_properties -U unicharset -O eng.test.exp0 eng.test.exp0.tr
生成聚集字符特征文件
$ mftraining -F font_properties -U unicharset -O eng.test.exp0 eng.test.exp0.tr
生成字符形状正常变化特征文件normproto
cntraining eng.test.exp0.tr
$ combine_tessdata test.
给inttemp,normproto,pffmtable,shapetable,unicharset 添加前缀 “test.”。
生成语言库
$ combine_tessdata test.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type 0 (test.config ) is -1
Offset for type 1 (test.unicharset ) is 140
Offset for type 2 (test.unicharambigs ) is -1
Offset for type 3 (test.inttemp ) is 891
Offset for type 4 (test.pffmtable ) is 137813
Offset for type 5 (test.normproto ) is 137935
Offset for type 6 (test.punc-dawg ) is -1
Offset for type 7 (test.word-dawg ) is -1
Offset for type 8 (test.number-dawg ) is -1
Offset for type 9 (test.freq-dawg ) is -1
Offset for type 10 (test.fixed-length-dawgs ) is -1
Offset for type 11 (test.cube-unicharset ) is -1
Offset for type 12 (test.cube-word-dawg ) is -1
Offset for type 13 (test.shapetable ) is 139557
Offset for type 14 (test.bigram-dawg ) is -1
Offset for type 15 (test.unambig-dawg ) is -1
Offset for type 16 (test.params-model ) is -1
Output test.traineddata created successfully.
语言库存到tesseract中
$ sudo cp test.traineddata /usr/share/tesseract-ocr/tessdata/
对比
for ($i=0; $i < 100; $i++) {
echo $i.":".(new TesseractOCR('./test/'.$i.'.jpg'))
->lang('test')
->run();
echo '\r';
}
for ($i=0; $i < 100; $i++) {
echo $i.":".(new TesseractOCR('./test/'.$i.'.jpg'))
->lang('eng')
->run();
echo '\r';
}
笔者用100张照片去对比,结果如下
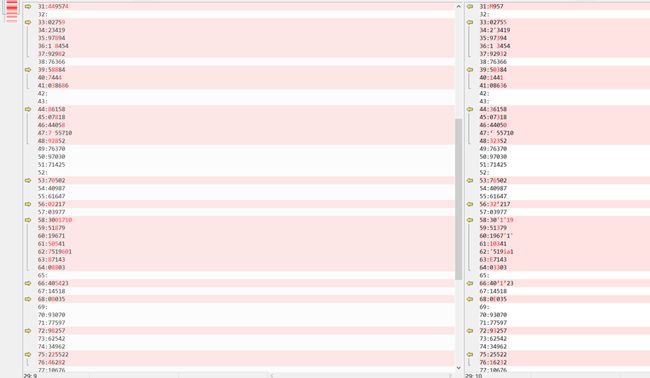
contrast
因为eng是还有匹配字母,所有速度和正确率方面有所影响。test我主要是校正数字,所以速度上相对有优势,加上训练数据不大,正确率不是很高。
| 语言库 | eng | test |
|---|---|---|
| 识别率 | 52% | 69% |
Tesseract 识别的图片如果太脏,需要清洗一下,否则极影响识别率。